Adapter Tuning
Fine-tuning
쉽게 이해하기
스마트폰 케이스를 떠올려 보자. 스마트폰 본체는 바꾸지 않으면서, 용도에 맞는 케이스만 교체하면 방수 기능, 카드 수납, 거치대 등 다양한 기능을 추가할 수 있다. 어댑터 튜닝(Adapter Tuning)은 이와 같은 원리다. 수십억 개 파라미터로 이루어진 대형 AI 모델의 가중치는 그대로 "동결"시키고, 각 Transformer 레이어 사이에 아주 작은 신경망 모듈 -- 어댑터 -- 을 끼워 넣는다. 학습할 때는 이 작은 어댑터만 업데이트하므로, 전체 모델을 처음부터 다시 학습하는 것에 비해 훨씬 적은 비용으로 새로운 태스크에 적응할 수 있다.
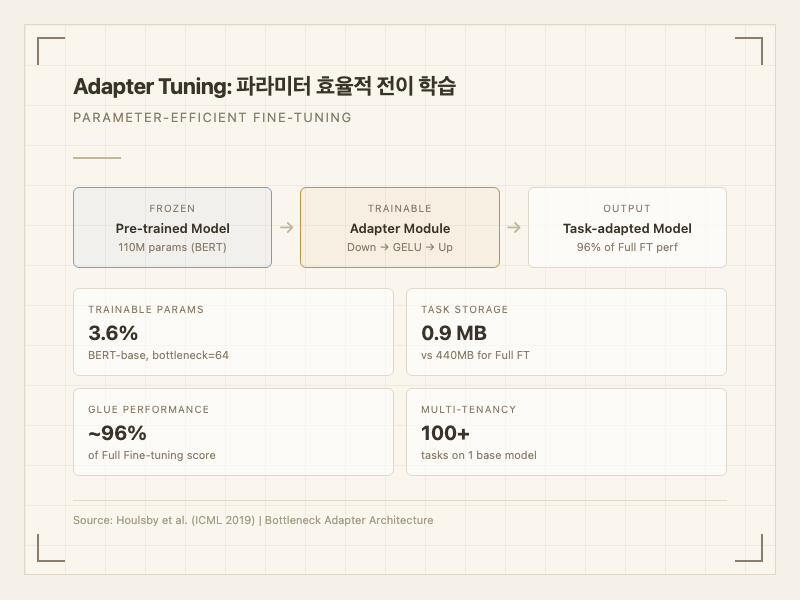
기존의 전체 파인튜닝(Full Fine-tuning)은 모델의 모든 파라미터를 태스크에 맞게 조정한다. 이 방식은 성능은 좋지만, 태스크마다 모델 전체의 복사본을 저장해야 하고, 학습에 막대한 GPU 메모리가 필요하다. 어댑터 튜닝은 원본 모델은 하나만 유지하면서 태스크별로 작은 어댑터 파일(약 0.9MB)만 따로 저장하면 된다. BERT-base 기준으로 전체 110M 파라미터 중 단 3.6%만 학습해도 전체 파인튜닝 성능의 약 96%를 달성한다1.
어댑터 튜닝은 특히 하나의 기본 모델 위에 여러 태스크를 동시에 서빙해야 하는 환경에서 빛난다. 예컨대 법률 문서 분류, 의료 보고서 요약, 고객 감성 분석 등 서로 다른 업무를 같은 모델에서 처리하되, 각각의 어댑터만 교체하면 된다. Databricks, Predibase 같은 MLOps 플랫폼은 이 패턴을 "멀티 어댑터 서빙"으로 공식 지원한다.
수치로 보면, 어댑터 튜닝은 전체 파인튜닝 대비 학습 파라미터를 97% 줄이면서도, GLUE 벤치마크 평균 점수 기준 약 1점 차이 이내의 성능을 유지한다(Houlsby et al., ICML 2019). 태스크당 저장 공간은 0.9MB 수준이어서, 100개 태스크를 관리해도 90MB에 불과하다.
기술 심층 분석
선수학습: 이 내용을 이해하려면 Fine-tuning의 개념과 Transformer 블록 구조를 먼저 읽으면 좋습니다.
핵심 아키텍처
어댑터 모듈은 병목(Bottleneck) 구조를 사용한다. 입력 히든 스테이트 에 대해 어댑터의 출력은 다음과 같다:
여기서:
- : 다운 프로젝션 (차원 압축, )
- : 업 프로젝션 (차원 복원, )
- : 비선형 활성화 함수 (보통 GELU 또는 ReLU)
- : 병목 차원. , 이면 어댑터 파라미터 수 = 개
잔차 연결()과 의 영점 근처 초기화 덕분에, 학습 초기에 어댑터는 항등 함수(identity function)로 동작한다. 이는 사전학습된 모델의 출력을 훼손하지 않고 안정적으로 학습을 시작하게 해준다.
Transformer Block with Adapter:
Input x
|
v
[Multi-Head Attention] (frozen)
|
v
[Adapter: Down -> GELU -> Up + residual] (trainable) <-- Houlsby #1
|
v
[Layer Norm + Residual] (frozen)
|
v
[Feed-Forward Network] (frozen)
|
v
[Adapter: Down -> GELU -> Up + residual] (trainable) <-- Houlsby #2
|
v
[Layer Norm + Residual] (frozen)
|
v
Output
삽입 위치 변형어댑터를 어디에 삽입하느냐에 따라 세 가지 주요 변형이 존재한다:
| 변형 | 삽입 위치 | 어댑터 수/레이어 | 특징 |
|---|---|---|---|
| Houlsby (2019) | Attention 이후 + FFN 이후 | 2개 | 표현력 높음, 파라미터 2배 |
| Pfeiffer (2021) | FFN 이후만 | 1개 | 파라미터 절반, Houlsby와 유사 성능 |
| Parallel (He et al., 2022) | Attention/FFN과 병렬 | 1-2개 | 직렬 레이턴시 제거 |
Pfeiffer 변형은 파라미터 수가 절반이면서도 대부분의 벤치마크에서 Houlsby와 동등한 성능을 보여, 현재 AdapterHub 등에서 기본 설정으로 사용된다2.

핵심 파생 기법
AdapterFusion: 여러 태스크용 어댑터를 독립적으로 학습한 뒤, 어텐션 기반 가중 합성(Fusion)으로 결합한다. 새로운 태스크에서 기존 어댑터들의 지식을 재활용할 수 있어 전이 학습에 효과적이다.
MAD-X: 언어별 어댑터와 태스크별 어댑터를 분리 학습한 뒤 조합하는 방식이다. 한국어 어댑터 + 감성 분석 어댑터를 조합하면, 한국어 감성 분석기를 처음부터 학습하지 않고도 구축할 수 있다(Pfeiffer et al., EMNLP 2020).
AdapterDrop: 추론 시 하위 레이어의 어댑터를 제거하여 속도를 40% 높이면서 성능 손실을 최소화하는 기법이다(Ruckle et al., EMNLP 2021).
성능 및 비교
PEFT 방법론 간 비교
| 방법론 | 학습 파라미터 비율 | GLUE 평균 (출처) | 추론 레이턴시 추가 | 가중치 병합 |
|---|---|---|---|---|
| Full Fine-tuning | 100% | 86.4 (Mao et al. 2022, Table 2) | 없음 | 해당 없음 |
| Adapter (UniPELT) | ~8.9% | 85.6 (Mao et al. 2022, Table 2) | 4-6% | 불가 |
| LoRA | ~0.5% | 85.2 (Hu et al. 2021, Table 2) | 병합 시 0 | 가능 |
| Prefix Tuning | ~0.1% | 82.1 (Li & Liang 2021, Table 1) | 최소 | 불가 |
도메인 적응 성능 (RoBERTa-base)
| 도메인 | Full FT (출처) | Adapter (PT+UniPELT) (출처) | 차이 |
|---|---|---|---|
| ACL-ARC (CS) | 63.0 (Gururangan 2020) | 82.1 (Mao et al. 2022, Table 4) | +19.1 |
| SCIERC (CS) | 77.3 (Gururangan 2020) | 87.2 (Mao et al. 2022, Table 4) | +9.9 |
| CHEMPROT (BioMed) | 81.9 (Gururangan 2020) | 84.3 (Mao et al. 2022, Table 4) | +2.4 |
| AG News | 93.9 (Gururangan 2020) | 94.3 (Mao et al. 2022, Table 4) | +0.4 |
주목할 점: 기본 모델의 사전학습 데이터와 어휘 겹침이 적은 도메인(CS 분야, 19.2% 어휘 겹침)에서 어댑터의 이점이 가장 크다. 반면 일반 뉴스(54.1% 어휘 겹침)에서는 차이가 미미하다.
DistilBERT 감성 분류 (재현 실험)
| 방법 | 학습 시간 | 테스트 정확도 (출처) |
|---|---|---|
| Full Fine-tuning | 7.12분 | 93.0% (Raschka 2023, 재현 실험) |
| Adapter (bottleneck=32) | 5.69분 | 88.4% (Raschka 2023, 재현 실험) |
| Last 2 Layers Only | 2.89분 | 86.4% (Raschka 2023, 재현 실험) |
실무적 의미: 어댑터는 레이어 일부만 학습하는 방식보다 2%p 높은 정확도를 보이면서, 전체 파인튜닝보다 20% 빠르게 학습된다.

장점과 한계
장점
- 극단적 파라미터 효율성: 전체 모델의 3.6%만 학습해도 96% 성능 달성. BERT-base 기준 태스크당 0.9MB 저장(Houlsby et al. 2019)
- 모듈성과 합성 가능성: 태스크별 어댑터를 독립적으로 학습하고 AdapterFusion으로 합성할 수 있다. MAD-X처럼 언어/태스크 어댑터를 조합하면 데이터가 없는 언어-태스크 쌍에도 대응 가능
- 망각 방지: 원본 가중치를 동결하므로 전체 파인튜닝 대비 사전학습 지식의 변형이 적다. He et al.(2021)은 어댑터가 "사전학습 표현 공간에서의 이탈이 적다"고 보고
- 저자원 환경에 강함: 학습 데이터가 적을 때 전체 파인튜닝보다 과적합에 강하고 학습률 변화에 덜 민감(He et al., ACL 2021)
- 멀티 테넌시 서빙: 하나의 기본 모델에 태스크별 어댑터를 교체 장착하여 여러 고객/용도를 동시에 서빙 가능
한계
- 추론 레이턴시 증가: 어댑터가 직렬로 삽입되므로 4-6%의 추론 시간 증가가 발생한다. LoRA는 가중치 병합으로 이 문제를 해결하지만 어댑터는 병합이 불가. 대안: AdapterDrop으로 하위 레이어 어댑터를 제거하면 40% 속도 향상 가능(Ruckle et al. 2021)
- 삽입 위치 선택의 모호성: Houlsby, Pfeiffer, Parallel 등 변형마다 최적 삽입 위치가 다르고, 태스크/모델에 따라 결과가 달라진다. 일관된 규칙이 없어 실험적 탐색이 필요
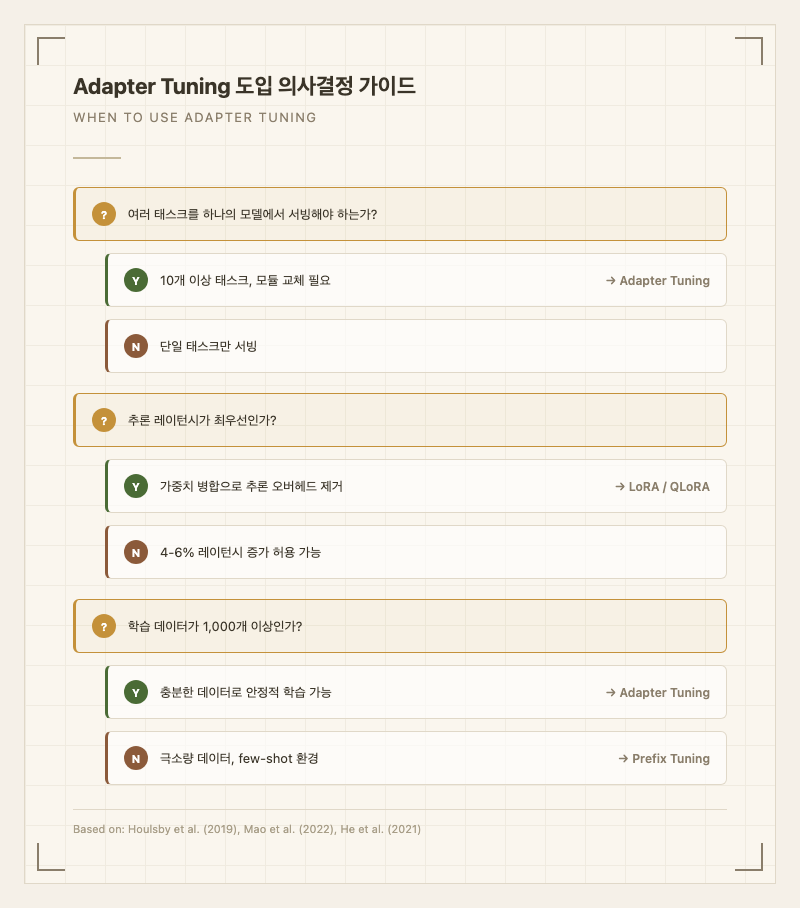
- Few-shot에서 불리: 학습 데이터가 1,000개 미만일 때는 Prefix Tuning이나 프롬프트 기반 방법이 더 안정적. 어댑터는 충분한 데이터가 있을 때 진가를 발휘
- LoRA 대비 구현 복잡도: LoRA는 기존 레이어에 저랭크 행렬을 더하는 단순 구조인 반면, 어댑터는 새 레이어를 삽입하고 forward pass를 수정해야 한다. HuggingFace PEFT 라이브러리에서도 LoRA가 기본 추천
- 라이브러리 구현 불일치: 일부 PEFT 라이브러리의 어댑터 구현이 원 논문과 다른 경우가 보고되었다(Mao et al. 2022). 구현 시 원 논문의 구조를 교차 검증해야 한다
실무 적용 가이드
적합한 시나리오
- 하나의 기본 모델로 10개 이상의 태스크를 서빙해야 할 때 (멀티 테넌시)
- 도메인 특화 적응이 필요하되, 기본 모델의 일반 지식을 보존해야 할 때
- 학습 데이터가 수천~수만 개 수준으로 충분할 때
- 다국어 전이가 필요할 때 (MAD-X 활용)
부적합한 시나리오
- 실시간 추론에서 레이턴시가 극도로 중요한 경우 -> LoRA 사용 후 가중치 병합
- 학습 데이터가 100개 미만인 극단적 few-shot -> Prefix Tuning 권장
- 단일 태스크에 최대 성능이 필요한 경우 -> 전체 파인튜닝 또는 QLoRA
추천 하이퍼파라미터
| 파라미터 | 권장값 | 비고 |
|---|---|---|
| 병목 차원 (m) | 64-256 | 작을수록 효율적, 클수록 표현력 증가 |
| 활성화 함수 | GELU | ReLU도 사용 가능하나 GELU가 일반적 |
| 학습률 | 2e-4 ~ 5e-4 | 전체 FT보다 높게 설정 |
| 삽입 변형 | Pfeiffer | 파라미터 효율 최적, AdapterHub 기본값 |
| Dropout | 0.1 | 과적합 방지 |
형제 방법론과의 선택 기준
LoRA와 어댑터 튜닝 중 고민된다면: 추론 레이턴시가 중요하면 LoRA, 태스크 모듈성과 합성이 중요하면 어댑터. 두 방법을 게이팅으로 결합한 UniPELT도 고려할 수 있다.