o1-pro
OpenAILLM자연어 처리컴퓨터 비전오디오 처리200K 토큰
2025년 3월 20일Proprietary
한줄 소개
o1-pro는 OpenAI가 2025년 3월에 API로 공개한 프리미엄 추론 모델이다. o1과 동일한 아키텍처를 기반으로 하되, 각 문제에 더 많은 컴퓨팅 자원을 할당하여 더 깊고 신중한 추론을 수행한다. 한마디로 "같은 뇌인데 더 오래 생각하는 버전"이고, 그 대가로 현존하는 AI 모델 중 가장 비싼 API 가격(입력 600/1M)을 매기고 있다.
주요 특징
o1-pro의 핵심 차별점은 단순한 모델 크기 증가가 아니라 "추론 시간 컴퓨팅"의 강화다. 동일한 o1 아키텍처에서 더 많은 추론 토큰을 생성하게 함으로써, 복잡한 문제를 풀 때 오답률을 크게 줄인다. OpenAI 공식 발표에 따르면, 특히 모호하거나 다단계 추론이 필요한 문제에서 일반 o1 대비 일관되게 더 나은 답변을 제공한다.
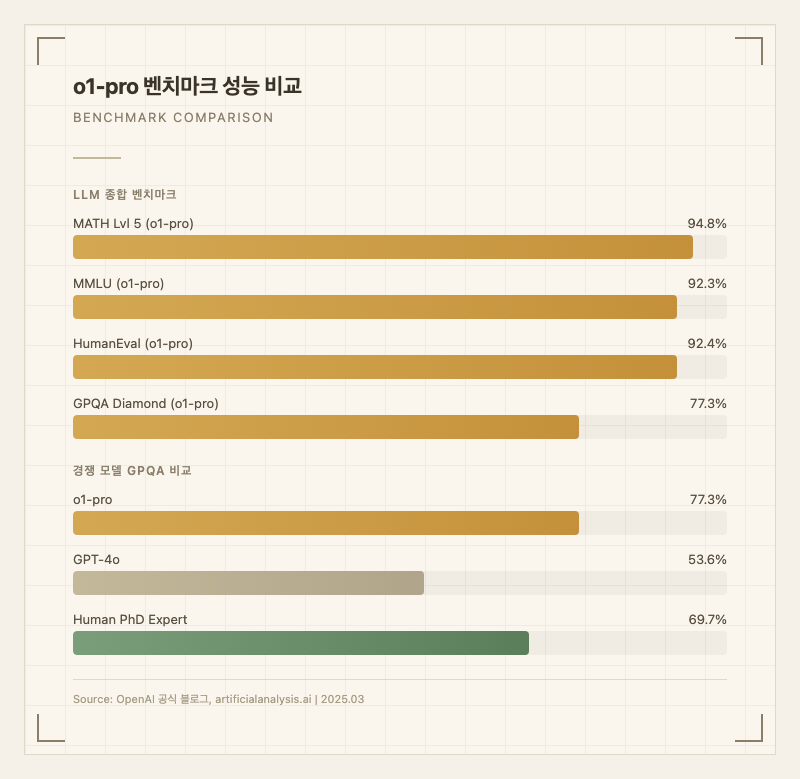
GPQA Diamond 벤치마크에서 77.3%를 기록하며 물리, 생물, 화학 분야의 인간 PhD 전문가 정확도(69.7%)를 최초로 넘어섰다 (출처: OpenAI 공식 블로그). AIME(미국 수학 올림피아드 예선)에서는 단일 샘플 74%, 합의 기반 83%로 전국 상위 500명 수준의 성적을 보여준다 (출처: OpenAI 공식 블로그).
다만 실사용자들의 체감은 숫자만큼 극적이지 않다. 클리앙의 한 사용자는 "o1과 o1 Pro 사이에서 뚜렷한 차이를 느끼기 어렵다"고 평가했고, OpenAI 커뮤니티에서도 "Fast But Totally Useless - $180 Extra for What?"이라는 제목의 글이 올라오기도 했다. 벤치마크 수치와 체감 사이의 괴리가 있는 모델이라는 점을 인지해야 한다.
200K 토큰 컨텍스트 윈도우와 100K 토큰 최대 출력을 지원하며, Function Calling, Structured Outputs, 이미지 입력을 지원한다. 반면 스트리밍은 미지원이고, Fine-tuning도 불가능하다.

할 수 있는 것
o1-pro가 진가를 발휘하는 영역은 "한 번에 정확한 답이 필요한 고가치 작업"이다. 구체적으로 다음과 같은 유스케이스에서 강점을 보인다.
복잡한 수학/과학 문제 풀이: MATH Lvl 5에서 94.8%를 기록하며 (출처: OpenAI 공식 블로그), 고난도 수학 증명이나 과학 연구 질문에 대해 높은 정확도를 보인다. MMMU에서 78.2%로 시각적 문제까지 포함한 대학원 수준 멀티모달 문제에서도 인간 전문가와 경쟁한다 (출처: OpenAI 공식 블로그).
법률/금융 문서 분석: 다단계 논리 추론이 필요한 법률 문서 검토나 금융 모델링에서 일반 LLM보다 정확한 판단을 내린다. 다만 이것은 공식 벤치마크가 아닌 유스케이스 기반 평가이므로, 실제 적용 시에는 반드시 전문가 검증을 병행해야 한다.
소프트웨어 아키텍처 설계: gpters.org의 한 사용자는 "대강 내가 구상하는 로직을 설명하는 것보다 어떻게 구성되었으면 하는지 설명만 잘 해줘도 알잘딱으로 설계를 짜준다. 개발용으로는 사람이랑 일하는 것보다 낫다"고 평가했다. HumanEval 92.4% (출처: OpenAI 공식 발표)로 코딩 능력도 상위권이지만, 2026년 기준 GPT-5.4 Pro(88.3%)나 Claude Opus 4.6(79.3%) 같은 최신 모델들이 SWE-bench에서 더 높은 점수를 기록하고 있어 코딩 분야 절대 강자라고 보기는 어렵다.
연구 지원/팟캐스트 준비: Zapier의 보도에 따르면, 한 콘텐츠 팀은 팟캐스트 시즌과 인터뷰 준비에 ChatGPT Pro(o1 pro 모드)를 핵심 워크플로우로 활용하고 있다고 밝혔다.
반면 할 수 없는 것도 명확하다. 응답 속도가 GPT-4o 대비 약 30배 느리며, 간단한 Python 작업도 127초가 걸릴 수 있다 (출처: 커뮤니티 벤치마크). 스트리밍 미지원으로 30-60초간 로딩 스피너만 보게 된다. PDF 첨부가 안 되고 이미지만 첨부 가능하다는 한국 사용자 후기도 있다.
성능
o1-pro의 벤치마크 성능을 정리하면 다음과 같다.
| 벤치마크 | o1-pro | 비고 |
|---|---|---|
| MMLU | 92.3% | 57개 하위 카테고리 중 54개에서 GPT-4o 초과 (출처: OpenAI 공식 블로그) |
| GPQA Diamond | 77.3% | 인간 PhD 전문가(69.7%) 최초 초과 (출처: OpenAI 공식 블로그) |
| MATH Lvl 5 | 94.8% | (출처: OpenAI 공식 블로그) |
| HumanEval | 92.4% | (출처: OpenAI 공식 발표) |
| AIME 2024 | 74% (단일) / 83% (합의) | 전국 상위 500명, USAMO 커트라인 초과 (출처: OpenAI 공식 블로그) |
| MMMU | 78.2% | 인간 전문가와 경쟁 수준 (출처: OpenAI 공식 블로그) |
| Codeforces | 89th percentile | (출처: OpenAI 공식 블로그) |
벤치마크는 인상적이지만 실사용 체감은 다소 다르다. 여러 사용자 후기를 종합하면:
- "o1과 o1 Pro 사이에서 뚜렷한 차이를 느끼기 어렵다"는 의견이 다수 (출처: 클리앙)
- "벤치마크는 이런데 실제로는 이렇다" 식으로 보면, 수학/과학 같은 정형화된 문제에서는 확실히 강하지만, 일상적인 대화나 창작에서는 체감 차이가 미미하다
- 속도 면에서 GPT-4o 대비 30배 느림. Reddit 한 사용자는 "SQL 쿼리 최적화를 시켰더니 커피 타고 와도 아직 로딩 중이었다"고 표현 (출처: Reddit)
- Function Calling 성공률이 60% 수준으로, GPT-4o의 98%와 비교하면 프로덕션 도구 연동에서 신뢰하기 어렵다는 평가 (출처: 커뮤니티 벤치마크)
한계를 정리하면: (1) 응답 속도가 극도로 느림 (2) 스트리밍 미지원 (3) Function Calling 안정성 부족 (4) 비용 대비 체감 성능 향상이 크지 않음. 2026년 현재 o3, o4-mini, GPT-5.4 Pro 등 후속 모델이 나온 상태에서 o1-pro의 벤치마크 우위는 상당 부분 희석되었다.
사용 방법
웹/앱 (일반 사용자): ChatGPT Pro 구독(20/월)에서도 o1을 제한적으로 사용할 수 있지만, pro 모드는 Pro 구독 전용이다.
API (개발자): OpenAI API를 통해 o1-pro 모델 ID로 호출할 수 있다. Chat Completions API의 표준 형식을 따르며, reasoning_effort 파라미터로 추론 깊이를 조절할 수 있다. 공식 문서는 https://platform.openai.com/docs/models/o1-pro 에서 확인할 수 있다. Batch API(v1/batch)를 통한 대량 처리도 지원한다.
주의할 점: 스트리밍이 미지원이므로 응답이 한 번에 오며, 타임아웃 설정을 넉넉히 잡아야 한다. 시스템 프롬프트는 지원하지만 이전 o1 시리즈에서는 제한이 있었으므로 공식 문서를 반드시 확인하는 것이 좋다.
가격
o1-pro는 현존하는 AI 모델 중 가장 비싼 가격 구조를 가지고 있다.
구독 요금:
- ChatGPT Plus: $20/월 (o1 제한적 사용 가능, pro 모드 불가)
- ChatGPT Pro: $200/월 (o1 pro 모드 무제한, 무료 체험 없음)
API 가격:
- 입력: $150 / 1M 토큰
- 출력: $600 / 1M 토큰
비교하면 일반 o1(60)보다 10배, GPT-4o(10)보다 60배 비싸다. Claude Opus 4.6(75) 대비로도 약 8배 비싸다.

실사용자들의 가성비 평가는 갈린다. DC인사이드 ChatGPT 갤러리의 3개월 사용 후기에서는 "200달러를 먹는데 엄청난 성능 향상을 기대하기보다는 그저 어떤 생성형 AI를 쓸까 막막할 때 o1 pro 토큰 무한인 게 좋다"라는 반응이 있었다. 반면 GPTers Korea에서는 "30-40만원을 내고 그 이상의 가치를 창출할 수 있다면 o1 pro가 좋다"는 의견도 있다.
Zapier의 분석에 따르면 "PhD 수준의 작업을 하지 않는다면 Pro는 과도하다. 대부분의 사용자는 Plus로 충분하다"는 결론이다. API 기준으로도 가성비가 극히 낮아서, Artificial Analysis 기준 efficiencyScore가 매우 낮은 편에 속한다.
한국어 토큰 효율 데이터는 미공개 상태다. 일반적으로 OpenAI의 토크나이저는 한국어에서 영어 대비 2-3배 더 많은 토큰을 소비하므로, 실질 비용은 영어 사용 대비 2-3배 더 높을 수 있다.
기술 사양
| 항목 | 사양 |
|---|---|
| 개발사 | OpenAI |
| 출시일 | 2025년 3월 (API), 2024년 12월 (ChatGPT Pro 내 pro 모드) |
| 아키텍처 | o1 기반 강화학습 추론 모델 (파라미터 수 미공개) |
| 컨텍스트 윈도우 | 200,000 토큰 |
| 최대 출력 | 100,000 토큰 |
| 학습 데이터 기준일 | 2023년 10월 |
| 라이선스 | Proprietary (비공개) |
| 지원 기능 | Function Calling, Structured Outputs, 이미지 입력, Batch API |
| 미지원 기능 | 스트리밍, Fine-tuning, 오디오 입력, Assistants API |

참고 자료





스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2025년 3월 20일
학습 마감일
2023년 10월 31일
가성비 지수
-0.0
API 가격 (혼합)
입력 $150/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$150.00 / 1M 토큰
출력 (Completion)
$600.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
코딩최강
92.4
코드 생성, 버그 수정, 소프트웨어 엔지니어링
수학/추론
86.0
수학, 과학, 논리적 추론
Provider
OpenAI
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 86.4
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GPQA | 77.3 | % |
| HumanEval | 92.4 | % |
| MATH Lvl 5 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |
| Mistral Large 3 2512 | 72.8 |