Harness Engineering
쉽게 이해하기
자동차에는 엔진만 있는 게 아니다. 속도계, 안전벨트, ABS 브레이크, 주행 기록 장치까지 수십 개의 보조 시스템이 엔진을 감싸고 있다. AI 에이전트도 마찬가지다. 아무리 뛰어난 언어 모델이라도 프로덕션에 혼자 던져놓으면 사고가 난다. Harness Engineering은 AI 에이전트 주변을 감싸는 보조 구조 전체 - 권한 관리, 도구 조율, 상태 추적, 오류 복구, 감시, 승인 게이트 - 를 체계적으로 설계하는 방법론이다.
미슐랭 스타 셰프(LLM)가 아무리 뛰어나도, 주방에 레시피 북, 위생 규정, 조리 시간 타이머, 알레르기 표시판이 없으면 레스토랑을 운영할 수 없다. Harness Engineering은 셰프가 최선의 요리에 집중할 수 있도록 주방 전체 인프라를 설계하는 일이다. 이를 한 줄로 정리하면: Coding Agent = AI Model(s) + Harness. 모델이 두뇌라면, 하네스는 골격 + 신경계 + 면역계다1.
2025년 에이전트가 실험실을 벗어나 실제 업무에 투입되기 시작하면서, 2026년 초 "Harness Engineering"이 정식 엔지니어링 분야로 부상했다. OpenAI는 Codex 에이전트만으로 100만 줄 이상의 코드를 사람 손 없이 작성하는 프로젝트를 완수했고, 이 과정에서 강건한 하네스 설계가 핵심 성공 요인이었다2. @Claude Code의 hooks 시스템, @Cursor의 rules 파일, @Devin의 자율 실행 환경 등 주요 코딩 에이전트들이 유사한 하네스 아키텍처로 수렴하고 있다.

기술 심층 분석
선수학습: 이 내용을 이해하려면 Agentic Workflow를 먼저 읽으면 좋습니다.
핵심 아키텍처
Harness Engineering의 핵심은 에이전트 루프를 래핑하는 **6대 구성 요소(Configuration Surface)**다1:
-
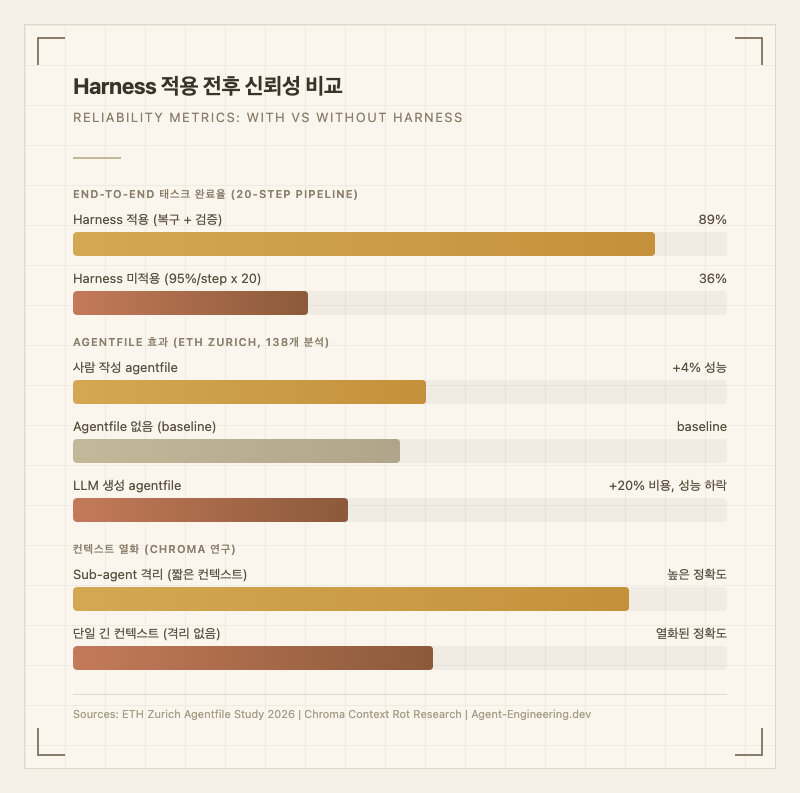
Agent Files (CLAUDE.md, AGENTS.md): 시스템 프롬프트에 결정적으로 주입되는 마크다운 설정 파일. 에이전트의 행동 규칙, 코드 스타일, 금지 패턴을 정의한다. ETH Zurich 연구에 따르면 사람이 작성한 agentfile은 성능을 약 4% 향상시키지만, LLM이 자동 생성한 agentfile은 오히려 비용만 20% 증가시키며 성능이 하락했다3.
-
MCP Servers: Model Context Protocol로 도구 노출을 표준화하면서, 어떤 도구를 어떤 조건에 노출할지를 서버 단에서 제어한다. 단, MCP 서버를 과도하게 연결하면 도구 설명이 컨텍스트 윈도우를 채워 성능이 저하된다.
-
Skills: 점진적 공개(Progressive Disclosure) 방식의 도메인 지식 번들. SKILL.md 파일에 관련 지식과 도구를 묶어, 필요할 때만 활성화해 컨텍스트 효율을 유지한다.
-
Sub-agents: 역할 분리가 아닌 컨텍스트 방화벽으로 기능한다. 부모 에이전트는 프롬프트와 최종 결과만 보고, 중간 과정의 노이즈가 축적되지 않는다. Chroma 연구에 따르면 긴 컨텍스트에서 쿼리와 의미적 유사도가 낮은 정보가 쌓이면 모델 성능이 측정 가능하게 열화된다.
-
Hooks: 에이전트 라이프사이클 이벤트(PreToolUse, PostToolUse, Stop 등)에 외부 스크립트를 주입하는 제어점. @Claude Code는 21개 라이프사이클 이벤트와 4가지 핸들러 패턴을 지원한다4.
-
Back-pressure: 에이전트가 자신의 작업을 검증하는 피드백 루프. typecheck, 테스트, lint를 에이전트 종료 시 실행해 오류가 있으면 exit code 2로 재개입을 강제한다. 전체 테스트 스위트를 매번 돌리면 컨텍스트가 오염되므로, 관련 서브셋만 실행하는 것이 핵심이다.

에이전트 행동 공간 에 대해 하네스는 허용 집합 를 정의한다:
위험도 점수 를 기준으로 임계값 를 두면: 이면 자동 실행, 이면 로깅 후 실행, 이면 Human-in-the-Loop 에스컬레이션으로 분기한다.
장기 실행 에이전트(Long-running Agent)의 경우 멀티세션 조정이 추가된다. Anthropic의 연구에 따르면, 첫 세션에서 초기화 에이전트가 init.sh, 진행 로그(claude-progress.txt), 기능 목록(JSON)을 설정하고, 이후 세션마다 git 히스토리와 진행 파일을 읽어 상태를 복구한 뒤 단일 기능씩 점진적으로 구현하는 패턴이 효과적이다5.
성능 및 비교
| 항목 | Harness 미적용 | Harness 적용 | 비고 |
|---|---|---|---|
| 20-step 태스크 완료율 | 36% | 89% | 각 step 95% 성공률 가정6 |
| Agentfile 비용 효율 | baseline | +4% 성능 | 사람 작성 기준 (ETH Zurich)3 |
| LLM 생성 Agentfile | -성능 하락 | +20% 비용 | 자동 생성 비추천3 |
| 컨텍스트 열화 대응 | 긴 단일 컨텍스트 | Sub-agent 격리 | Chroma 연구 기반 |
| 항목 | 기존 MLOps | Harness Engineering |
|---|---|---|
| 제어 대상 | 모델 학습/배포 파이프라인 | 에이전트 런타임 행동 |
| 개입 시점 | 배포 전 | 추론 루프 중 실시간 |
| 실패 처리 | 롤백, 재배포 | 즉각 인터럽트, 폴백 |
| 관찰 단위 | 배치 메트릭 | 도구 호출 단위 트레이스 |
| 정책 갱신 | 모델 재훈련 필요 | 런타임 설정 변경 |
| 인간 참여 | 배포 승인 | 고위험 액션별 승인 |
20-step 파이프라인에서 각 단계가 95% 성공하더라도 하네스 없이는 전체 완료율이 36%로 급락한다. 복구 메커니즘과 검증 루프를 갖춘 하네스는 이를 89%까지 끌어올린다.
장점과 한계
장점
첫째, 예측 불가능성 감소. LLM은 동일한 프롬프트에도 비결정적으로 동작한다. 하네스는 출력 공간을 제한해 프로덕션 환경의 예측 가능성을 높인다.
둘째, 점진적 권한 확장. 에이전트를 처음 도입할 때 읽기 전용 도구만 허용하고, 신뢰도가 쌓이면 쓰기, 외부 API 호출 순으로 권한을 확장하는 단계적 배포가 가능하다.
셋째, 규정 준수(Compliance). 금융, 의료 등 규제 업종에서 AI 에이전트의 모든 액션을 감사 가능한 로그로 남기는 것이 법적 요건이다.
넷째, 비용 제어. 에이전트가 무한 루프에 빠지거나 불필요한 API를 과다 호출하는 상황을 토큰 예산 guardrail로 차단할 수 있다.
다섯째, 모델 교체 용이성. 하네스가 잘 설계되면 기반 모델을 교체해도 동일한 안전성과 워크플로우를 유지할 수 있다.
한계
첫째, 오버헤드. 모든 tool_use 호출에 guardrail 검사를 삽입하면 레이턴시가 증가한다. Human-in-the-Loop gate가 동기적으로 동작하면 사용자 경험이 저하된다. 해결 방향: 비동기 승인 패턴, 위험도 기반 선택적 검사.
둘째, 과잉 차단(False Positive). 보수적인 정책은 정상적인 에이전트 행동도 막아 태스크 완료율을 떨어뜨린다. 해결 방향: 임계값의 지속적 튜닝, A/B 테스트 기반 정책 최적화.
셋째, 하네스 자체의 취약성. Prompt injection이 guardrail 로직을 우회하도록 설계될 수 있다. MCP 서버도 prompt injection 벡터가 될 수 있다1. 해결 방향: Defense-in-depth (다중 레이어 방어).
넷째, 표준 부재. 2026년 현재 Harness Engineering의 산업 표준은 없다. 각 조직이 독자적인 구현을 유지하면서 이식성이 낮다. 해결 방향: MCP 같은 프로토콜 표준화 노력 확산.
다섯째, 하네스 과적합. 특정 하네스에 post-training된 모델은 다른 하네스에서 성능이 떨어질 수 있다. Opus가 Claude Code에서는 33위지만 다른 하네스에서 5위를 기록한 사례가 보고되었다1.
실무 적용 가이드
적합한 시나리오: 파일 시스템 수정, 외부 API 호출, 데이터베이스 쓰기 등 실제 부작용(side effect)이 있는 에이전트. 장기 실행 멀티세션 에이전트. 규제 업종의 AI 에이전트 배포.
부적합한 시나리오: 순수 텍스트 생성(챗봇, 요약). 일회성 프롬프트 실행. 프로토타입/실험 단계에서 과도한 하네스는 반복 속도를 저하시킨다.
도입 판단 기준
- 에이전트가 비가역적 작업을 수행하면: HITL 게이트 필수
- 세션이 단일 컨텍스트 윈도우를 초과하면: 멀티세션 조정 (진행 파일 + Git 기반 상태 복구)
- 10개 이상 도구 또는 병렬 에이전트: MCP + Sub-agent 격리
- 소수 도구 + 단일 에이전트: Agent File + Hooks로 충분

실무 체크리스트
- 모든 도구에 위험 등급(low/medium/high/critical) 부여
- Critical 도구에 Human-in-the-Loop 게이트 적용
- 토큰 예산 및 최대 루프 횟수 상한 설정
- 모든 tool_use 이벤트 구조화 로깅
- Prompt injection 방어 레이어 (입력 새니타이징)
- 장애 시나리오별 Recovery 경로 문서화
- Harness 정책의 버전 관리 (config-as-code)
- 정기적인 Red Team 테스트 (하네스 우회 시도)
- @Claude Code, @Cursor 등 코딩 에이전트 하네스 활용
실무 원칙: 처음부터 완벽한 하네스를 설계하지 말 것. 실제 실패를 관찰한 후 설정을 추가하고, 반복 속도를 최적화하라. "Just in case" 스킬이나 MCP 서버를 미리 설치하지 말 것1.

Footnotes
-
HumanLayer, "Skill Issue: Harness Engineering for Coding Agents", 2026. https://www.humanlayer.dev/blog/skill-issue-harness-engineering-for-coding-agents ↩ ↩2 ↩3 ↩4 ↩5
-
OpenAI, "Harness Engineering: Leveraging Codex in an Agent-First World", 2026. https://openai.com/index/harness-engineering/ ↩
-
ETH Zurich, Agentfile Study (138 agentfiles analyzed), 2026. ↩ ↩2 ↩3
-
Anthropic, "Claude Code hooks system documentation", 2025. https://docs.anthropic.com/en/docs/claude-code/hooks ↩
-
Anthropic, "Effective Harnesses for Long-Running Agents", 2026. https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents ↩
-
Agent-Engineering.dev, "Harness Engineering in 2026", 2026. https://www.agent-engineering.dev/article/harness-engineering-in-2026-the-discipline-that-makes-ai-agents-production-ready ↩