Auto Research
Agentic Workflow
쉽게 이해하기
대학원생이 연구를 한다고 생각해 보겠습니다. 논문을 읽고, 가설을 세우고, 실험 코드를 짜서 돌리고, 결과를 분석하고, 다시 가설을 수정합니다. 이 과정을 몇 주에서 몇 달에 걸쳐 반복하지요. Auto Research는 이 전체 연구 사이클을 AI 에이전트가 자율적으로, 24시간 쉬지 않고 수행하는 방법론입니다. 단순히 문헌을 검색하거나 요약하는 수준이 아니라, AI가 직접 코드를 작성하고, 실험을 실행하고, 결과를 해석하고, 심지어 논문까지 써냅니다.
기존 연구 자동화는 대부분 특정 단계만 돕는 도구였습니다. AutoML은 하이퍼파라미터 탐색을 자동화하지만 새로운 아이디어를 제안하지는 못합니다. 문헌 검색 AI는 논문을 찾아주지만 실험을 설계하지는 않습니다. Auto Research는 이런 개별 도구들과 달리 아이디어 생성부터 논문 작성까지 연구의 전체 생애주기를 하나의 에이전트 루프로 통합합니다. Sakana AI의 AI Scientist가 대표적인 구현체로, 논문 한 편을 약 14M 시드 투자를 유치하며 세계 최초 자동화 연구소 구축에 나섰고1, OpenAI도 "완전 자동화 연구 인턴"을 2026년 9월까지 구축하겠다고 발표했습니다2.
이 비유의 한계: 대학원생은 지도교수와 토론하며 방향을 잡지만, 현재 Auto Research 시스템은 이런 고수준 방향 설정에서 아직 인간의 개입이 필요합니다.
기술 심층 분석
선수학습: 이 내용을 이해하려면 Agentic Workflow를 먼저 읽으면 좋습니다.
핵심 아키텍처
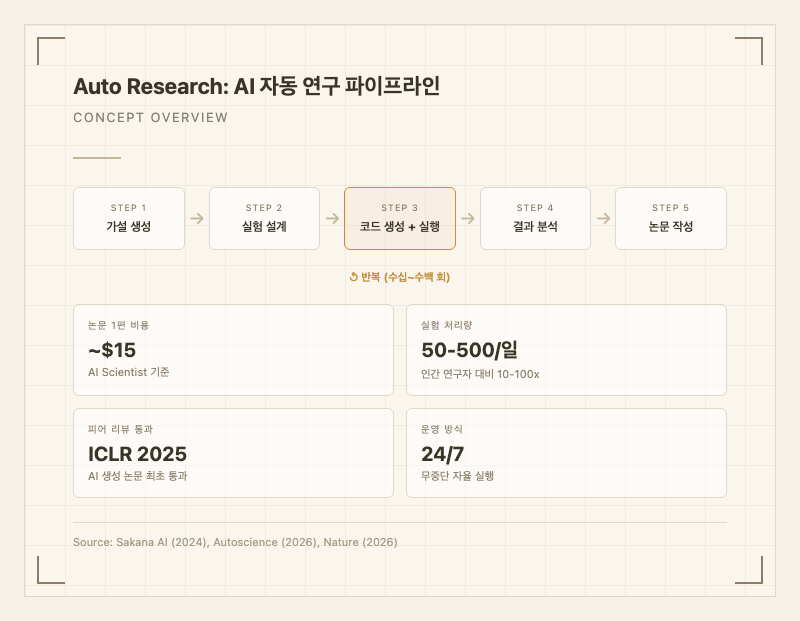
Auto Research는 과학적 방법론(Scientific Method)을 에이전트 루프로 형식화한 것입니다. 핵심 구조는 다음과 같습니다:
[Auto Research 루프]
목표 설정 (인간 또는 상위 에이전트)
|
v
Phase 1: 아이디어 생성 (Idea Generation)
- LLM이 연구 방향 제안
- Semantic Scholar API로 신규성 검증
- 기존 연구와 차별점 명시
|
v
Phase 2: 실험 설계 + 실행 (Experimentation)
- 가설에 맞는 코드 자동 생성
- 샌드박스 환경에서 실행
- 결과 수치 + 시각화 자동 생성
|
v
Phase 3: 논문 작성 (Paper Writing)
- LaTeX 형식 논문 자동 생성
- Semantic Scholar에서 인용 자동 탐색
- 실험 결과 해석 + 시각화 삽입
|
v
Phase 4: 자동 피어 리뷰 (Automated Review)
- LLM 기반 리뷰어가 논문 평가
- 강점/약점/개선 방향 피드백
|
v
피드백 -> Phase 1로 복귀 (Open-Ended Loop)
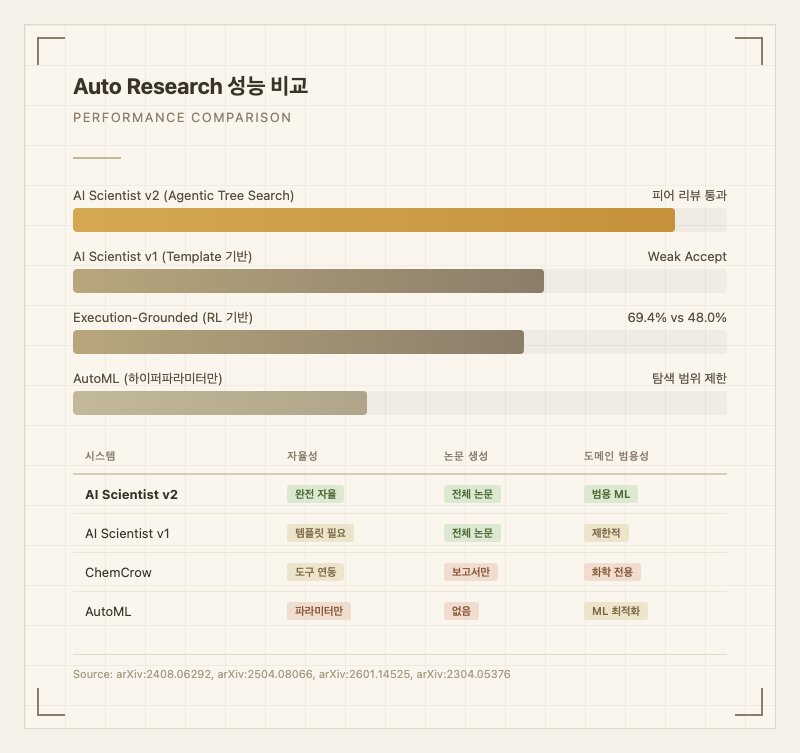
AI Scientist v1(2024)은 인간이 작성한 코드 템플릿을 기반으로 실험을 변형하는 방식이었습니다. v2(2025)에서는 Progressive Agentic Tree Search를 도입해 이 의존성을 제거했습니다. Experiment Manager 에이전트가 트리 구조로 실험 경로를 탐색하며, Vision-Language Model(VLM) 피드백 루프로 그래프와 시각화 품질까지 자동 개선합니다(arXiv:2504.08066).
또 다른 접근인 Execution-Grounded Research(arXiv:2601.14525)는 LLM이 생성한 아이디어를 자동 실행기(executor)로 구현하고, 대규모 병렬 GPU 실험으로 검증합니다. 진화적 탐색(evolutionary search)과 강화학습(RL) 두 가지 학습 방식을 테스트했으며, 진화적 탐색이 더 안정적인 성능을 보였습니다.
도메인 특화 시스템도 존재합니다. ChemCrow(arXiv:2304.05376)는 GPT-4에 18개 화학 전문 도구를 연동하여, 곤충 기피제와 유기촉매 합성 경로를 자율적으로 설계하고 신규 발색단을 발견했습니다(Nature Machine Intelligence, 2024).

성능 및 비교
| 시스템 | 자율성 수준 | 논문 품질 (출처) | 비용 | 도메인 |
|---|---|---|---|---|
| AI Scientist v1 | 템플릿 기반 실험 변형 | Weak Accept (arXiv:2408.06292) | ~$15/편 | ML 3개 서브필드 |
| AI Scientist v2 | 완전 자율 (템플릿 불필요) | ICLR 워크숍 피어 리뷰 통과 (arXiv:2504.08066) | ~$15/편 | 범용 ML |
| Execution-Grounded | 실행 기반 검증 | Post-training 69.4% vs baseline 48.0% (arXiv:2601.14525) | GPU 비용 변동 | LLM 학습 최적화 |
| ChemCrow | 도구 연동 자율 실행 | 신규 발색단 발견 (Nature Mach. Intel.) | API 비용 | 화학 전용 |
| AutoML/NAS | 파라미터 탐색만 | 아키텍처 최적화 (고정 공간) | 중간 | ML 파이프라인 |
| 인간 연구자 | 완전 자율 | 최고 (창의적 도약 가능) | 높음 | 모든 분야 |
AI Scientist v2의 핵심 성과는 AI가 생성한 3편의 논문을 ICLR 워크숍에 제출했을 때, 1편이 인간 평균 수락 점수를 초과한 것입니다(arXiv:2504.08066). 이는 완전 자동 생성 논문이 피어 리뷰를 통과한 최초 사례입니다. 다만 이는 워크숍 수준이며, 본 학회(main conference) 수준은 아직 달성되지 않았습니다.
Execution-Grounded 방식에서는 post-training 과제에서 기존 GRPO baseline 대비 44.6% 성능 향상(48.0% -> 69.4%)을 10회 탐색 에포크 만에 달성했고, pre-training에서는 nanoGPT 학습 시간을 35.9분에서 19.7분으로 45% 단축했습니다(arXiv:2601.14525).
실무 해석: Auto Research는 하이퍼파라미터 튜닝이나 기존 방법 변형 같은 '점진적 개선' 연구에서 인간 대비 10-100배 빠른 처리량을 보이지만, 패러다임 전환적 발견에서는 아직 인간 연구자를 대체하지 못합니다.
장점과 한계
장점:
- 24/7 무중단 실험 실행: 인간이 하루 1-5개 실험을 할 때 50-500개를 수행 (AI Scientist 기준, arXiv:2408.06292)
- 논문 1편 약 $15의 극저비용으로 아이디어 탐색 범위를 극대화 (Sakana AI 공식 발표)
- 코드 템플릿 없이도 범용 ML 도메인에서 작동 (v2 기준, arXiv:2504.08066)
- 자동 피어 리뷰가 인간 리뷰어에 근접한 정확도를 보여 품질 필터링 가능 (arXiv:2408.06292)
- 방대한 문헌을 컨텍스트로 활용하여 인간이 놓치는 연결고리 탐색
한계:
- 재현성 문제: AI 모델이 독점적 알고리즘과 비공개 데이터셋에 의존하면 실험 재현이 어려움. 해결 방향: 오픈소스 모델 + 실험 로그 전체 기록 (Nature, 2026)
- LLM 환각으로 인한 잘못된 가설 생성: 존재하지 않는 논문 인용, 부정확한 수치 사용 가능. 해결 방향: Execution-Grounded 방식으로 실행 결과 기반 검증 (arXiv:2601.14525)
- 시각화 품질 미흡: v1에서 읽을 수 없는 그래프 생성 빈번. 해결 방향: v2의 VLM 피드백 루프로 개선 중 (arXiv:2504.08066)
- 윤리적 우려: 저작권 귀속 불명확, 논문 공장(paper mill) 악용 가능성. 학술 커뮤니티에서 AI 생성 연구의 공저자 인정 기준이 아직 정립되지 않음 (Nature, 2026; Pubrica, 2026)
- 창의적 도약의 부재: 기존 방법론의 변형과 조합에는 강하지만, 완전히 새로운 패러다임 제시는 아직 관찰되지 않음. 치명적 시나리오: 새로운 이론적 프레임워크가 필요한 기초 과학 연구
- RL 기반 최적화의 모드 붕괴: 강화학습으로 연구 방향을 학습시킬 때, 평균 보상은 증가하지만 단순한 아이디어에 수렴하는 현상 관찰 (arXiv:2601.14525)
실무 적용 가이드
적합한 시나리오:
- ML 모델의 하이퍼파라미터/아키텍처 탐색 (정량적 지표로 자동 평가 가능할 때)
- 프롬프트 엔지니어링 전략 자동 탐색
- 데이터 증강 기법 비교 실험
- 화학/신약 분야 합성 경로 탐색 (ChemCrow 스타일)
- 기존 논문의 재현 실험 자동화
부적합한 시나리오:
- 정성적 평가가 핵심인 연구 (사용자 경험, 인터뷰 기반)
- 완전히 새로운 이론적 프레임워크 구축
- 윤리 심사(IRB)가 필요한 인체 대상 연구
- 하드웨어/물리적 실험이 필요한 연구 (로봇 연동 없이)
도입 판단 기준:
- 실험당 평가 지표가 자동 산출 가능하면 Auto Research 적합
- GPU 예산이 실험 1회당 1 수준으로 확보되면 비용 효율적
- 탐색 공간이 넓고 반복 실험이 10회 이상 필요한 경우 효과 극대화
- 연구 결과의 재현성이 필수인 경우, 실험 로그 전체를 기록하는 프레임워크 필수
추천 설정:
python
config = {
'max_iterations': 50,
'timeout_per_experiment': 3600,
'sandbox_enabled': True,
'human_review_threshold': 0.8,
'cost_limit_usd': 100,
'rollback_enabled': True,
}
형제 방법론: Agentic Research Loop은 문헌 조사와 지식 탐색에 특화된 반면, Auto Research는 코드 실행과 실험까지 포함한 전체 연구 사이클을 자동화합니다. Plan Mode Workflow는 단발성 작업 계획에 초점을 맞춥니다.

