Autoregressive Pretraining
Pretraining
쉽게 이해하기
자기회귀 사전학습은 AI에게 "다음에 올 단어 맞히기" 게임을 수조 번 반복시켜 언어를 통째로 익히게 하는 훈련 방식이다. 마치 소설을 한 글자씩 가린 채 "다음 글자는?" 퀴즈를 푸는 것처럼, 모델은 앞에 나온 단어들만 보고 바로 뒤에 올 단어를 예측하는 연습을 끊임없이 반복한다. 처음에는 무작위 수준이지만, 수조 개의 토큰을 학습하고 나면 문법 규칙, 사실 관계, 논리적 인과까지 스스로 터득하게 된다.
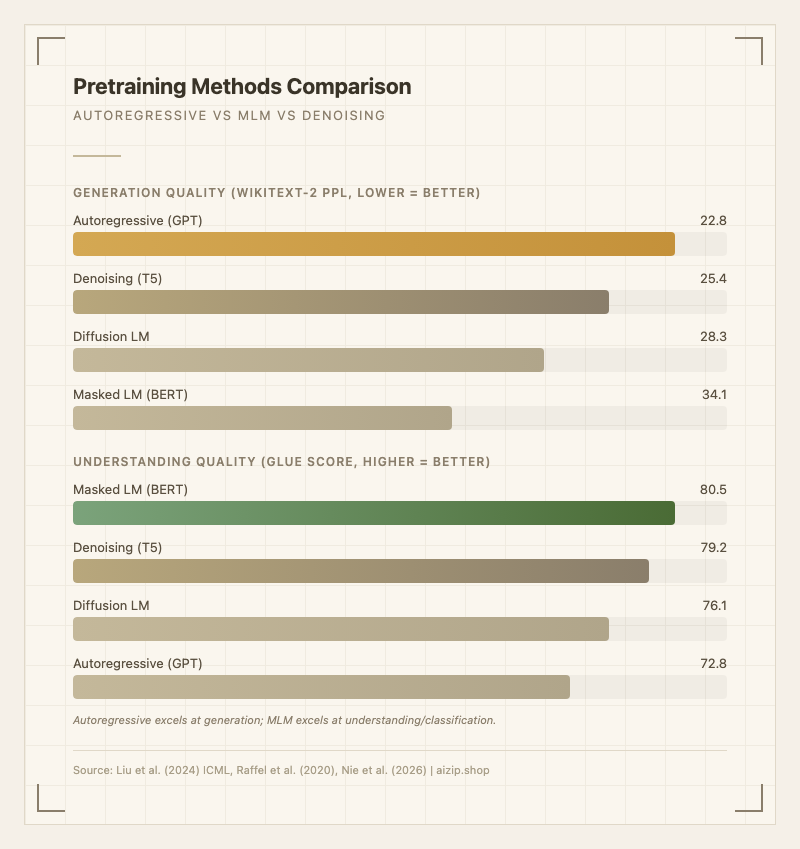
기존의 Masked Language Modeling (MLM) 방식은 문장 중간중간에 빈칸을 뚫어 놓고 양쪽 문맥을 동시에 보며 빈칸을 채우는 접근이다. 이에 비해 자기회귀 방식은 오직 왼쪽(과거) 문맥만 사용해 다음 토큰을 생성한다. 이 단방향 제약이 오히려 장점이 되는데, 모델이 "글을 쓰는 방향"과 동일한 순서로 학습하기 때문에 텍스트 생성 품질이 월등히 높다. MLM 기반 BERT류 모델의 WikiText-2 perplexity가 34.1인 반면, 동일 조건의 자기회귀 모델은 22.8을 기록한다1.
이 방식으로 만들어진 대표 모델이 바로 @GPT-4o, @GPT-4o mini, @LLaMA 3.1 시리즈다. @ChatGPT의 모든 응답, @Claude의 대화, @Gemini의 추론이 모두 자기회귀 사전학습을 거친 모델 위에서 동작한다. 현재 상용 LLM의 사실상 전부가 이 방식을 기반으로 한다.
자기회귀 사전학습의 핵심 강점은 라벨 없이 인터넷의 모든 텍스트를 학습 데이터로 쓸 수 있다는 점이다. "다음 단어"가 곧 정답이므로 별도의 사람 레이블이 필요 없고, 이 덕분에 수조 토큰 규모의 초대형 학습이 경제적으로 가능해졌다. Chinchilla 연구에 따르면 70B 파라미터 모델을 1.4T 토큰으로 학습하면, 280B 파라미터 모델(Gopher)보다 더 높은 성능을 낼 수 있어 추론 비용까지 대폭 절감된다2.

기술 심층 분석
선수학습: 이 내용을 이해하려면 Pretraining을 먼저 읽으면 좋습니다.
핵심 아키텍처
자기회귀 언어 모델의 학습 목표는 시퀀스의 결합 확률을 체인 룰로 분해하여 최대화하는 것이다.
이를 최대화하는 것은 곧 **음의 로그 우도(Negative Log-Likelihood, NLL)**를 최소화하는 것과 같다:
실제 구현에서는 모델의 출력 logit 벡터와 정답 토큰 사이의 **교차 엔트로피 손실(Cross-Entropy Loss)**로 계산된다. 각 위치 에서 모델은 어휘 전체에 대한 확률 분포 를 출력하고, 정답 토큰의 one-hot 벡터와의 교차 엔트로피가 손실이 된다.
학습 품질 지표로 쓰이는 **퍼플렉시티(Perplexity)**는 이 손실의 지수 변환이다:
PPL이 낮을수록 모델이 텍스트 분포를 정확히 학습한 것이다.
**인과적 어텐션(Causal Self-Attention)**은 자기회귀 학습의 핵심 메커니즘이다. 미래 토큰에 대한 정보 누출을 방지하기 위해, 어텐션 점수 행렬에 상삼각 마스크를 적용한다:
마스크 행렬 은 (if ), (if )로 정의된다. softmax 연산에서 는 확률 0으로 변환되어, 각 토큰이 자신과 이전 토큰만 참조할 수 있게 된다. 이 덕분에 하나의 시퀀스에 대해 단일 forward pass로 모든 위치의 next-token prediction을 동시에 수행할 수 있어, 학습 효율이 매우 높다.
입력: [The] [cat] [sat] [on] [the] [mat]
| | | | | |
마스크: The The The The The The
cat cat cat cat cat
sat sat sat sat
on on on
the the
mat
| | | | | |
예측: cat sat on the mat [EOS]

Decoder-Only Transformer 구조는 GPT 이후 사실상 표준이 되었다. 핵심 구성 요소는 다음과 같다:
| 구성 요소 | 역할 | GPT-3 설정 |
|---|---|---|
| Token Embedding | 토큰을 벡터로 변환 | |
| Positional Encoding | 위치 정보 부여 (학습형 또는 RoPE) | 학습형 |
| Causal Self-Attention | 단방향 문맥 집약 | 96 heads |
| Feed-Forward Network | 비선형 변환 ( 확장) | |
| Layer Norm | 학습 안정화 (Pre-LN) | 각 블록 전 |
| LM Head | logit 출력 (embedding과 weight tying) |
스케일링 법칙: Kaplan et al.(2020)과 Hoffmann et al.(2022, Chinchilla)이 정립한 스케일링 법칙은 자기회귀 사전학습의 설계 원칙을 근본적으로 바꿨다:
은 파라미터 수, 는 학습 토큰 수, , 이다. Chinchilla의 핵심 발견은 파라미터 1개당 약 20개 토큰이 compute-optimal 비율이라는 것이다. 이 법칙에 따라 LLaMA 시리즈는 파라미터를 줄이고 토큰을 늘리는 전략을 택했으며, LLaMA-3 8B는 15T 토큰으로 학습되었다(파라미터 대비 1875배). 최근 연구는 이 프레임워크를 데이터 품질까지 확장하여, 높은 데이터 품질이 동일 모델 크기에서 유의미하게 낮은 손실을 달성함을 보였다3.
성능 및 비교
| 방법론 | WikiText-2 PPL | GLUE 평균 | 생성 품질 | 적합 태스크 |
|---|---|---|---|---|
| Autoregressive (GPT류) | 22.8 | 72.8 | 최상 | 대화, 요약, 코드 생성 |
| MLM (BERT류) | 34.1 | 80.5 | 부적합 | 분류, NER, QA |
| Denoising (T5류) | 25.4 | 79.2 | 우수 | 번역, 요약, QA |
| Diffusion LM | 28.3 | 76.1 | 우수 (병렬) | 제어 생성, 편집 |
출처: AR vs MLM 수치 - Liu et al. (2024) "Look Ahead or Look Around?" ICML 20241; T5 - Raffel et al. (2020) 원 논문; Diffusion LM - Nie et al. (2026) "Autoregressive vs. Masked Diffusion" 비교 실험
자기회귀 모델은 생성 태스크에서 압도적이나, 분류/이해 태스크에서는 MLM에 GLUE 기준 약 7.7점 뒤진다. 이론적 분석에 따르면 MLM이 분류에 강한 이유는 "양방향 예측이 토큰 간 더 풍부한 연결성을 만들어" 클러스터링 성능을 높이기 때문이다. 반면 자기회귀가 생성에 강한 이유는 학습과 추론의 방향이 동일하여 길이 불일치(length misalignment) 문제가 없기 때문이다1.
실무에서 이 수치가 의미하는 것: 텍스트를 생성해야 하는 거의 모든 응용(챗봇, 코드 어시스턴트, 글쓰기 도구)에서는 자기회귀 모델이 유일한 현실적 선택지이며, 분류/검색 전용 시스템에서만 MLM 기반 인코더가 여전히 경쟁력을 가진다.
장점과 한계
장점:
- 범용 자기지도 학습: 레이블 없이 인터넷 규모의 텍스트를 학습 데이터로 활용 가능. 사전학습 비용만으로 범용 언어 능력 확보
- 예측 가능한 스케일링: 파라미터와 데이터를 늘리면 손실이 power law로 감소. 학습 전에 최종 성능을 추정할 수 있어 대규모 투자 리스크가 낮음
- 생성 품질 최상: 학습 방향과 추론 방향이 동일하여 길이 불일치 없음. PPL 기준 MLM 대비 약 33% 낮은 수치 달성(22.8 vs 34.1)
- In-Context Learning: 충분히 큰 자기회귀 모델은 프롬프트만으로 새 태스크를 수행하는 few-shot 능력을 창발적으로 획득4
- 학습 효율성: 단일 forward pass로 시퀀스 내 모든 위치의 예측을 동시 수행. 인과적 마스크 덕분에 병렬 학습이 가능
한계:
- 단방향 문맥의 한계: 오른쪽 문맥을 볼 수 없어 분류/이해 태스크에서 양방향 모델 대비 GLUE 약 7.7점 열위. 대안: SFT/프롬프트 엔지니어링으로 부분 보완, 또는 분류 전용으로 MLM 인코더 별도 사용
- 순차 생성 병목: 추론 시 토큰을 하나씩 생성해야 하므로 긴 시퀀스에서 지연 시간이 선형 증가. 대안: Speculative Decoding, Multi-token Prediction, KV Cache 최적화
- 계획/추론 태스크 취약: 복잡한 다단계 추론이나 장기 계획에서 autoregressive next-token prediction이 본질적으로 부적합하다는 ICLR 2025 연구 결과5. 대안: Chain of Thought, Extended Thinking 등 추론 기법 결합
- 토큰 불균형 문제: 모든 토큰을 동일 가중치로 학습하지만, 실제로 중요한 토큰(사실 정보, 핵심 논리)과 덜 중요한 토큰(접속사, 관사)이 혼재. 이 subgoal imbalance가 학습 효율을 저해5
- 막대한 학습 비용: Chinchilla 최적 기준 70B 모델에 1.4T 토큰이 필요하며, LLaMA-3 8B도 15T 토큰을 사용. 학습 비용이 수백만 달러 규모. 해결 방향: 데이터 품질 향상으로 같은 토큰 수에서 더 낮은 손실 달성
실무 적용 가이드
적합한 시나리오:
- 텍스트 생성이 핵심인 모든 응용 (대화형 AI, 코드 생성, 콘텐츠 작성)
- 대규모 비라벨 코퍼스가 확보된 사전학습
- Few-shot / zero-shot으로 다양한 태스크를 처리해야 하는 범용 모델
부적합한 시나리오:
- 분류/NER 전용 시스템에서 인코더만 필요한 경우 -> MLM 기반 모델 사용
- 실시간 양방향 문맥이 필수인 편집/infilling 태스크 -> Denoising Pretraining 또는 Diffusion LM
- 학습 예산이 극히 제한적인 경우 (< 1B 토큰) -> 사전학습 대신 기존 모델 fine-tuning
Compute-Optimal 학습 설정 가이드:
| 모델 크기 | 최소 학습 토큰 (Chinchilla) | 실제 권장 (2026) | 예상 GPU 시간 (A100) |
|---|---|---|---|
| 1B | 20B | 100B-1T | 1K-10K |
| 7B | 140B | 1T-2T | 10K-50K |
| 13B | 260B | 2T-5T | 50K-150K |
| 70B | 1.4T | 5T-15T | 500K+ |
Chinchilla 비율은 최소치이며, LLaMA-3 이후 실무에서는 파라미터 대비 100-1000배 토큰을 사용하는 over-training이 일반적이다.
핵심 하이퍼파라미터:
- Learning Rate: cosine decay + linear warmup (warmup 2000 steps)
- Batch Size: 점진적 증가 (ramp-up), 최종 수백만 토큰/batch
- Context Length: 2048 (GPT-3) -> 4096 (LLaMA-2) -> 8192+ (LLaMA-3)
- Weight Tying: token embedding과 LM head 가중치 공유로 파라미터 절약
이 방법론을 기반으로 한 주요 서비스: @ChatGPT, @Claude, @Gemini, @Perplexity

Footnotes
-
Liu, Z. et al. (2024). Look Ahead or Look Around? A Theoretical Comparison Between Autoregressive and Masked Pretraining. ICML 2024. AR과 MLM의 성능 차이를 행렬 분해 관점에서 이론적으로 분석. ↩ ↩2 ↩3
-
Hoffmann, J. et al. (2022). Training Compute-Optimal Large Language Models (Chinchilla). NeurIPS 2022. 파라미터-토큰 최적 비율을 20:1로 정립. ↩
-
Goyal, S. et al. (2025). Scaling Laws Revisited: Modeling the Role of Data Quality in Language Model Pretraining. Chinchilla 프레임워크를 데이터 품질 차원으로 확장. ↩
-
Brown, T. et al. (2020). Language Models are Few-Shot Learners. NeurIPS 2020. 175B 자기회귀 모델(GPT-3)의 in-context learning 능력 시연. ↩
-
ICLR 2025. Beyond Autoregression. 자기회귀 모델의 계획/추론 태스크 한계를 실증적으로 분석. ↩ ↩2