AutoML
쉽게 이해하기
머신러닝 모델을 만드는 과정은 마치 수천 가지 재료와 조리법이 있는 주방에서 최고의 요리를 만들어내는 것과 비슷합니다. 어떤 재료(알고리즘)를 선택하고, 얼마나 넣을지(하이퍼파라미터), 어떤 순서로 조리할지(파이프라인) 결정하는 데 숙련된 셰프(데이터 과학자)의 경험과 직관이 필요합니다. AutoML(Automated Machine Learning, 자동 기계학습)은 이 전체 과정을 자동화하는 '로봇 셰프'입니다. 수천 가지 조합을 체계적으로 시도해서 주어진 재료(데이터)로 만들 수 있는 가장 맛있는 요리(최적 모델)를 찾아줍니다.
기존 머신러닝 개발 방식에서는 데이터 전처리, 피처 엔지니어링, 알고리즘 선택, 하이퍼파라미터 튜닝, 모델 평가 등 각 단계를 전문가가 수동으로 수행해야 했습니다. 한 번의 실험 사이클에 수일에서 수주가 걸리고, 최적의 조합을 찾기 위해 수십-수백 번의 반복이 필요했습니다. AutoML은 이 전체 파이프라인을 자동으로 탐색합니다. 데이터를 입력하면 전처리부터 최종 모델 선택까지 자동으로 수행하여, 전문가 수준의 결과를 비전문가도 얻을 수 있게 해줍니다1.
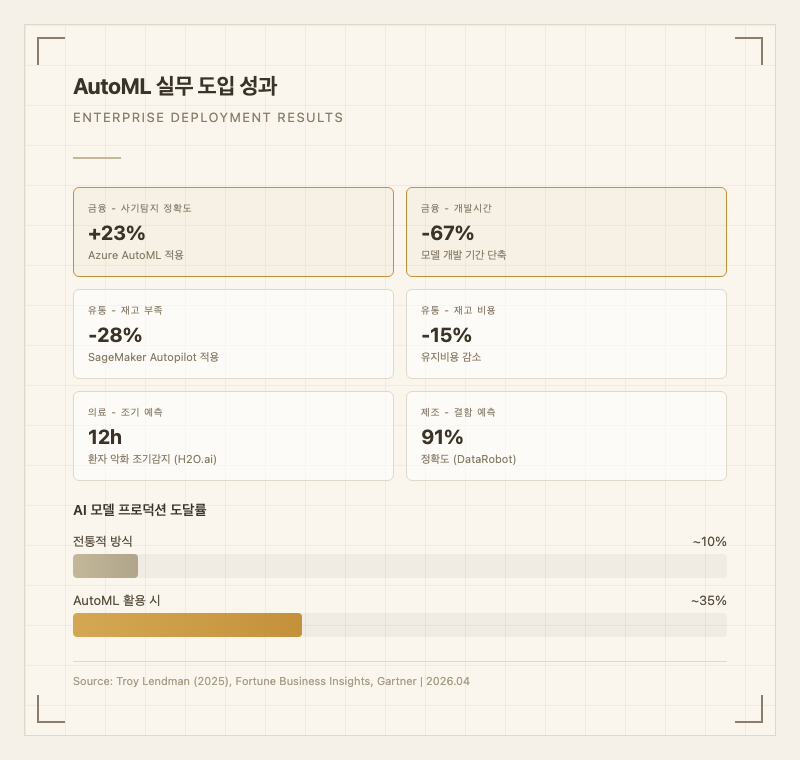
실제로 @Google Cloud AutoML은 이미지를 업로드하면 분류 모델을 자동으로 생성하고, Amazon의 AutoGluon은 CSV 파일 하나로 테이블 데이터 분류/회귀 모델을 4줄의 코드만으로 완성합니다. @H2O.ai는 의료 분야에서 환자 악화를 기존 방식보다 12시간 먼저 예측하는 모델을 자동으로 구축했습니다(Troy Lendman, 2025). AutoML 시장은 연평균 48.3%의 성장률로 확대되고 있으며, 2034년까지 $231.5B 규모에 이를 것으로 전망됩니다(Fortune Business Insights, 2024).
기술 심층 분석
선수학습: 이 내용을 이해하려면 Hyperparameter Optimization (HPO)과 Neural Architecture Search (NAS)를 먼저 읽으면 좋습니다.
핵심 아키텍처
AutoML의 핵심은 CASH(Combined Algorithm Selection and Hyperparameter optimization) 문제를 해결하는 것입니다. 주어진 데이터셋 에 대해 알고리즘 와 하이퍼파라미터 의 최적 조합을 자동으로 찾는 것이 목표입니다.
여기서 는 후보 알고리즘 집합, 는 알고리즘 의 하이퍼파라미터 공간, 은 손실 함수, 는 교차 검증 폴드 수입니다(Thornton et al., 2013; Feurer et al., 2015).
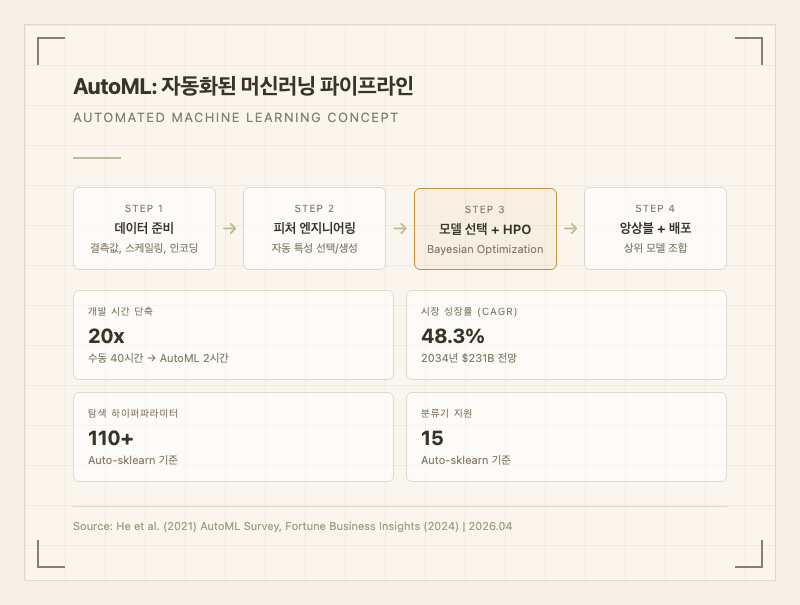
[AutoML 전체 파이프라인]
원본 데이터
|
v
1. 데이터 전처리 자동화
- 결측값 대치 (mean, median, mode)
- 수치 변수: 표준화, 정규화
- 범주 변수: 원-핫 인코딩, 타겟 인코딩
|
v
2. 피처 엔지니어링
- 자동 특성 선택 (상관관계, 중요도 기반)
- 자동 특성 생성 (다항식, 상호작용)
- 차원 축소 (PCA, 피처 해싱)
|
v
3. 모델 선택 + HPO (핵심)
- 후보 모델: LightGBM, XGBoost, RF, SVM, NN 등 15종+
- 탐색 전략: Bayesian Optimization (SMAC, TPE)
- 메타러닝: 유사 데이터셋의 과거 실험 결과로 초기값 설정
|
v
4. 앙상블 + 최종 모델
- 상위 N개 모델의 가중 앙상블
- 스태킹(stacking) 기반 조합
Bayesian Optimization은 AutoML에서 가장 널리 사용되는 HPO 전략입니다. 대리 모델(surrogate model)로 목적 함수를 근사하고, 획득 함수(acquisition function)로 다음 탐색 지점을 결정합니다:
여기서 는 Expected Improvement(EI) 등의 획득 함수이고, 은 이전 회 평가 결과입니다. Auto-sklearn은 이 위에 메타러닝을 추가해서, 140개 이상의 데이터셋에서 축적된 경험을 기반으로 좋은 초기 설정을 추천합니다(Feurer et al., 2015).
python
# AutoGluon - 4줄로 테이블 데이터 AutoML 실행
from autogluon.tabular import TabularPredictor
predictor = TabularPredictor(label='target').fit(train_data, time_limit=600)
predictions = predictor.predict(test_data)
leaderboard = predictor.leaderboard(test_data)
python
# Optuna - 커스텀 탐색 공간으로 HPO 실행
import optuna
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
def objective(trial):
params = {
'n_estimators': trial.suggest_int('n_estimators', 50, 500),
'max_depth': trial.suggest_int('max_depth', 2, 32),
'min_samples_split': trial.suggest_int('min_samples_split', 2, 20),
'max_features': trial.suggest_categorical('max_features', ['sqrt', 'log2', None]),
}
model = RandomForestClassifier(**params, random_state=42)
return cross_val_score(model, X_train, y_train, cv=5, scoring='f1').mean()
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
기존 수동 ML과의 구조적 차이점: 수동 방식에서는 전문가의 경험과 직관에 의존해 알고리즘을 선택하고 파라미터를 조정하는 반면, AutoML은 구조화된 탐색 공간에서 수학적으로 최적의 조합을 탐색합니다. 특히 메타러닝을 통해 '이 데이터셋과 비슷한 과거 데이터셋에서 어떤 알고리즘이 잘 작동했는지' 경험을 재활용하는 점이 핵심적인 차별점입니다.

성능 및 비교
| 플랫폼 | 특징 | 정형 데이터 성능 | 비용 | 출처 |
|---|---|---|---|---|
| Auto-sklearn | scikit-learn 기반, 15 분류기, 110+ HP, 메타러닝 + 앙상블 | 표준 벤치마크 상위권 | 오픈소스 | Feurer et al. (2015) |
| AutoGluon | AWS 개발, 멀티모달 지원, 앙상블 자동화 | 정확도-속도 균형 우수 | 오픈소스 | AWS (2020) |
| H2O AutoML | 분산 처리, 리더보드 자동 생성, 스태킹 앙상블 | 대규모 데이터 강점 | 오픈소스/상용 | H2O.ai |
| Google Cloud AutoML | 노코드, Vision/NLP/Tables, 전이학습 | Vision/NLP 강점 | 종량제 | Google (2018) |
| TPOT | 유전 프로그래밍 기반 파이프라인 최적화 | 높은 정확도, 느린 속도 | 오픈소스 | Olson et al. (2016) |
| DataRobot | 엔터프라이즈, 거버넌스, 설명 가능성 도구 | 제조 결함 예측 91% 정확도 | 엔터프라이즈 | DataRobot |
AutoML vs 수동 ML 비교 (Google ML Crash Course 기준):
- 시간: 수동 튜닝 40시간 vs AutoML 2시간 (약 20배 단축)
- 모델 품질: 표준 태스크에서 AutoML이 수동과 동등하거나 약간 낮음. 전문 도메인에서는 수동 튜닝이 우위
- 재현성: AutoML은 실행마다 다른 탐색 경로를 탐색할 수 있어 결과가 달라질 수 있음(Google ML Crash Course)
- 접근성: AutoML은 비전문가도 사용 가능, 수동 ML은 전문가 필수
이 수치가 실무에서 의미하는 것: 표준적인 분류/회귀 문제에서 AutoML은 전문가 수준의 성능을 1/20의 시간으로 달성할 수 있으나, 고도로 전문화된 도메인에서는 여전히 전문가의 수동 최적화가 필요합니다.

장점과 한계
장점:
- 개발 시간 대폭 단축: 모델 개발 시간을 평균 67% 단축 (금융 서비스 사례, Azure AutoML 기준, Troy Lendman 2025)
- 비전문가 접근성: ML 전문 지식 없이도 도메인 전문가(의사, 변호사, 마케터 등)가 직접 모델을 개발할 수 있음
- 인간이 놓치는 조합 발견: 110개 이상의 하이퍼파라미터와 15종 이상의 알고리즘을 체계적으로 탐색하여 인간의 직관으로는 발견하기 어려운 최적 조합을 찾음(Auto-sklearn 기준)
- 데이터셋 사전 검증: 모델 개발에 앞서 데이터셋에 충분한 신호가 있는지 빠르게 검증하는 "smoke test" 용도로 활용 가능(Google ML Crash Course)
- 앙상블 자동 구축: 상위 모델들의 가중 평균 앙상블을 자동으로 구성하여 단일 모델 대비 안정적인 성능 확보
한계:
- 전문 도메인에서 품질 제한: AutoML이 생성한 모델은 전문가의 수동 최적화보다 낮은 품질일 수 있음. 해결 방향: AutoML 결과를 baseline으로 사용하고 전문가가 미세 조정
- 높은 계산 비용: 수백-수천 번의 모델 학습이 필요하여 GPU/CPU 리소스 소모가 큼. NAS의 경우 수천 GPU-hours가 필요할 수 있음. 해결 방향: 메타러닝으로 초기 탐색 범위를 좁히거나, early stopping 전략 적용
- 블랙박스 문제: 모델 선택 과정이 불투명하여 규제 산업(금융, 의료)에서 설명 가능성 요구를 충족하기 어려움. 해결 방향: DataRobot, IBM Watson AutoAI 등 설명 가능성 도구가 내장된 플랫폼 사용
- 데이터 품질 의존성: "Garbage In, Garbage Out" 원칙이 AutoML에도 그대로 적용됨. 탐색 공간 설계와 데이터 전처리가 여전히 핵심. 해결 방향: 데이터 품질 검증 파이프라인을 AutoML 앞단에 배치
- LLM 시대의 위치: 딥러닝/LLM 파인튜닝을 위한 AutoML 도구는 아직 미성숙. LoRA, QLoRA 등의 파인튜닝 파이프라인을 완전 자동화하는 도구는 제한적. 대안: Hugging Face AutoTrain
한계가 치명적인 시나리오: 의료 진단, 자율주행, 금융 거래 등 모델의 의사결정 과정을 반드시 설명해야 하는 고위험 도메인에서는 AutoML의 블랙박스 특성이 규제 준수를 어렵게 만듭니다.
실무 적용 가이드
적합한 시나리오:
- 정형 데이터(테이블) 기반 분류/회귀 문제
- ML 전문가 없이 빠르게 baseline 모델이 필요한 경우
- 데이터셋의 예측 가능성을 빠르게 검증하고 싶은 경우
- 반복적인 모델 재학습이 필요한 프로덕션 파이프라인
부적합한 시나리오:
- 고도로 커스터마이즈된 딥러닝 아키텍처가 필요한 경우
- 설명 가능성이 법적으로 요구되는 규제 산업 (단, DataRobot 등 설명 가능성 도구 내장 플랫폼은 예외)
- LLM 파인튜닝 (아직 AutoML 도구가 미성숙)
- 매우 작은 데이터셋 (수백 건 미만, 전이학습 기반 AutoML 제외)
도입 판단 기준:
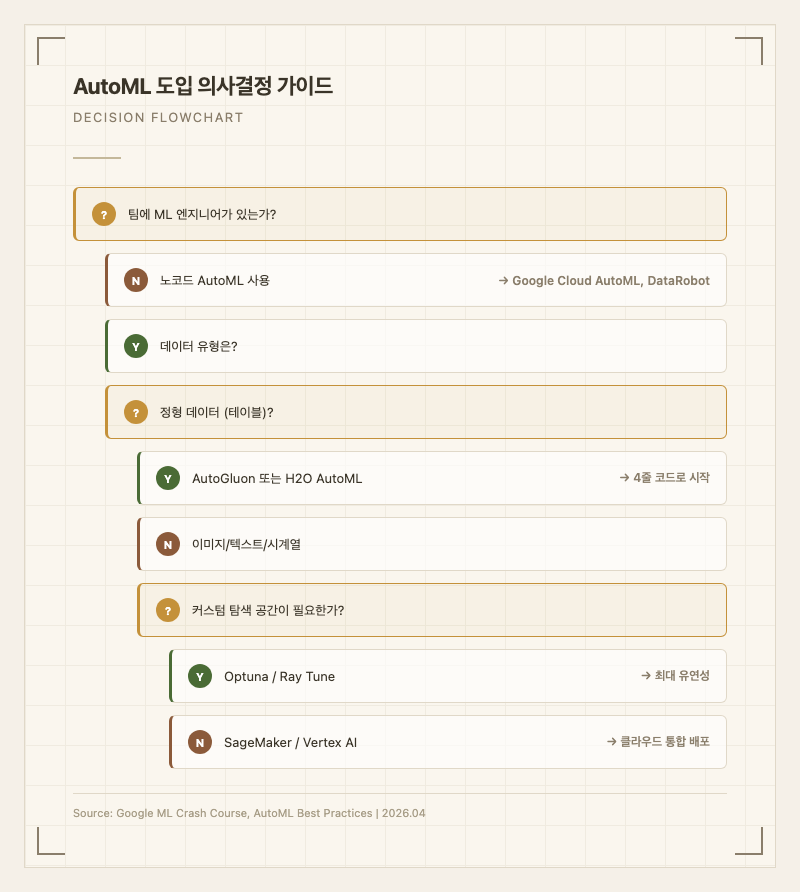
- 데이터가 1,000건 이상이면 AutoML 시도 가치 있음
- ML 엔지니어가 팀에 없으면 노코드 AutoML(Google Cloud AutoML, DataRobot) 권장
- 정형 데이터 + Python 환경이면 AutoGluon 또는 H2O AutoML로 시작 (4줄 코드)
- 커스텀 탐색 공간이 필요하면 Optuna 또는 Ray Tune
주요 AutoML 플랫폼별 추천:
| 상황 | 추천 도구 | 이유 |
|---|---|---|
| 정형 데이터, 빠른 시작 | AutoGluon | 오픈소스, 4줄 코드, 정확도-속도 균형 |
| 대규모 분산 처리 | H2O AutoML | 분산 처리, 리더보드 자동화 |
| 노코드/비전문가 | Google Cloud AutoML | GUI 기반, Vision/NLP 전이학습 |
| 엔터프라이즈 거버넌스 | DataRobot | 설명 가능성, 규제 준수 |
| 최대 유연성/커스텀 | Optuna + Ray Tune | 사용자 정의 탐색 공간 |
Footnotes
-
AutoML의 개념은 2013년 Auto-WEKA(Thornton et al.)에서 체계화되었으며, 2015년 Auto-sklearn(Feurer et al.)이 Bayesian Optimization + 메타러닝 + 앙상블 조합으로 AutoML Challenge에서 우승하며 실용성을 입증했습니다. ↩