딥러닝 입문 완전 가이드: 티처블 머신에서 프로덕션 AI까지
딥러닝이란?
"딥러닝을 배우려면 수학 박사가 필요하다"는 말은 2026년 현재 완전히 틀렸다. 딥러닝은 인공 신경망을 여러 층으로 쌓아 데이터에서 패턴을 학습하는 머신러닝의 한 분야다. 이미지 인식, 음성 인식, 자연어 처리 등 오늘날 대부분의 AI 서비스가 딥러닝 위에서 돌아간다.
왜 지금 배워야 하는가? 2026년 기준 미국 기업의 72%가 이미 ML을 표준 운영에 사용하고 있으며(Flowygo), 머신러닝 시장 규모는 2025년 503B으로 성장할 전망이다. 더 중요한 것은 진입 장벽이 극적으로 낮아졌다는 점이다. 브라우저에서 클릭 몇 번으로 딥러닝 모델을 만들 수 있는 No-Code 도구가 무료로 제공되고, LLM API를 통해 딥러닝 모델을 직접 학습시키지 않고도 AI 기능을 구현할 수 있는 시대가 됐다.
이 글의 대상과 난이도
- 대상 독자: 딥러닝에 관심은 있지만 어디서부터 시작해야 할지 모르는 입문자. 비전공자, 학생, 기획자, 주니어 개발자 모두 포함.
- 난이도: 입문 (Level 0에서 시작해 Level 4까지 로드맵 제시)
- 예상 소요시간: 읽기 15분 / 전체 로드맵 실행 3-6개월
- 사전 지식: 없음. 코드를 한 줄도 모르는 상태에서 시작 가능.
전체 구조

이 가이드는 코드 없이 시작해서 프로덕션 AI까지 이르는 5단계 로드맵을 따른다. Level 0(직관적 이해)과 Level 1(No-Code ML)은 코딩 없이 진행할 수 있다. Level 2부터 Python을 사용하며, Level 4(LLM API)는 코딩 경험과 무관하게 지금 바로 시작할 수 있다. 이 구조를 채택한 이유는 Reddit r/MachineLearning과 DeepLearning.AI 커뮤니티에서 반복적으로 확인되는 조언 - "만들면서 배워라(learn by building)" - 에 기반한다. Fast.ai 창립자 Jeremy Howard도 "이론부터 시작하면 대부분 포기한다. 무언가 동작하는 것을 먼저 만들어야 한다"고 강조한 바 있다.
도구 선택
이 가이드에서는 Level 0의 첫 도구로 Teachable Machine을 선택했다. 이유는 세 가지다. 첫째, 완전 무료이며 설치가 필요 없다(브라우저만 있으면 된다). 둘째, Google의 MobileNet을 기반으로 전이학습(Transfer Learning)을 수행하므로 "진짜 딥러닝"을 체험할 수 있다. 셋째, TensorFlow.js, TensorFlow Lite, 표준 TensorFlow 세 가지 포맷으로 모델을 내보낼 수 있어 학습 이후 실제 프로젝트에 투입 가능하다.
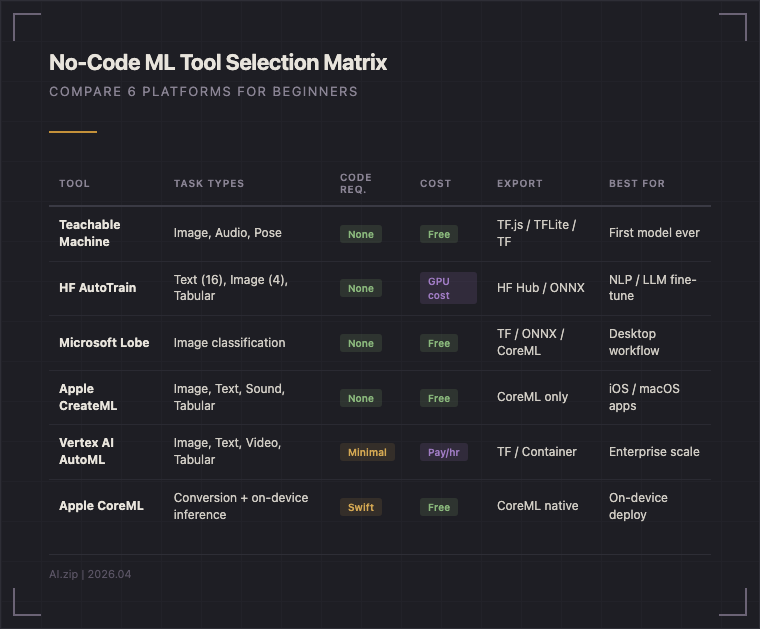
Level 1에서 텍스트/LLM 작업이 필요하다면 Hugging Face AutoTrain이 적합하다. AutoTrain은 16가지 텍스트 태스크(LLM 파인튜닝, 텍스트 분류, 토큰 분류, Seq2Seq 등)와 4가지 이미지 태스크를 지원하며, Apache 2.0 오픈소스로 무료다(GPU 비용만 별도). 경쟁 도구인 Google Cloud AutoML이나 Amazon SageMaker Autopilot에 비해 지원 태스크 범위가 넓고, Hugging Face Hub의 수십만 모델과 직접 연동된다는 점이 차별화 포인트다.
실전 사용법
Step
1: Teachable Machine으로 첫 모델 만들기 (현재 1/5단계 | ~10분)
Google이 무료로 제공하는 Teachable Machine(teachablemachine.withgoogle.com)으로 시작한다. 이 도구는 내부적으로 전이학습을 사용한다. Google의 MobileNet이 수백만 장의 이미지로 사전 학습한 가중치를 가져오고, 사용자가 제공한 데이터로 마지막 분류 레이어만 재학습(파인튜닝)한다.
실전 절차:
- teachablemachine.withgoogle.com 접속 후 "Image Project" 선택 (30초)
- 클래스 2개 이상 생성. 예: "고양이" / "강아지". 각 클래스에 웹캠으로 30-50장 이상 촬영. 각도, 거리, 조명을 다양하게 변경해서 촬영하는 것이 핵심 (4분)
- "Train Model" 클릭. 브라우저에서 TensorFlow.js가 로컬로 학습 진행. 평균 60-120초 소요 (2분)
- "Preview" 패널에서 실시간 테스트. 각 클래스의 신뢰도(confidence) 백분율 확인 (3분)
- "Export Model" 클릭. 웹사이트용 TF.js, 모바일용 TFLite, Python용 TF 중 선택 (1분)
체크포인트: Preview에서 새로운 이미지를 보여줬을 때 올바른 클래스가 70% 이상 신뢰도로 표시되면 성공.
만약 정확도가 낮다면: 클래스당 이미지 수를 200장 이상으로 늘리고, 배경 다양성을 확보한다. Flowygo에 따르면 "데이터 품질이 알고리즘 선택보다 10배 중요하다." 클래스 간 이미지 수 균형도 맞춰야 한다.
MIT Media Lab은 Teachable Machine을 AI 윤리 커리큘럼 개발에 활용했으며, 제조 현장에서는 불량품 감지에 적용해 92% 정확도를 달성한 사례가 보고됐다(Flowygo). ALS 환자를 위한 안구 움직임 기반 커뮤니케이션 시스템에도 Teachable Machine이 활용됐는데, 하드웨어 비용이 $50 미만이었다.
Step
2: 딥러닝 개념 잡기 (현재 2/5단계 | ~1-2주)
Teachable Machine에서 "Train" 버튼을 누를 때 내부에서 무슨 일이 일어나는지 이해하는 단계다.
핵심 학습 자료:
- 3Blue1Brown의 "Neural Networks" 시리즈 (YouTube, 무료): 뉴럴 네트워크가 어떻게 학습하는지 시각적 애니메이션으로 설명한다. 역전파(Backpropagation)를 수학 공식 없이 직관적으로 이해할 수 있다. Reddit r/MachineLearning에서 입문자에게 가장 많이 추천되는 자료다.
- Andrew Ng의 AI For Everyone (Coursera, 무료 청강): 비기술직 종사자도 들을 수 있는 AI 개론. 기술 세부사항보다 "AI가 무엇을 할 수 있고, 우리 조직에 어떻게 적용하는가"에 초점을 맞춘다.
주의: Reddit 사용자들이 반복적으로 경고하는 실수가 있다. 이 단계에서 선형대수, 미적분, 확률론을 완벽하게 마스터하려 하면 대부분 포기한다. 수학은 필요할 때 필요한 만큼만 배우는 것이 효과적이다. DeepLearning.AI 커뮤니티에서도 "2026년에 프로그래밍을 배우는 입문자에게 가장 중요한 것은 이론과 실습을 동시에 진행하는 것"이라는 의견이 주류다.
Step
3: No-Code ML 도구로 실전 문제 해결 (현재 3/5단계 | ~2-4주) - MVE 완성
이 단계가 최소 동작 버전(MVE)의 완성 지점이다. 코드 없이도 실제 비즈니스 문제를 해결할 수 있게 된다.
Hugging Face AutoTrain 사용법:
- huggingface.co/autotrain 접속
- 태스크 유형 선택 (예: 텍스트 분류, 이미지 분류)
- 데이터셋 업로드 (CSV, JSONL, ZIP 지원)
- 베이스 모델 선택 (Hugging Face Hub의 수십만 모델 중 선택)
- 학습 파라미터 설정 후 시작. 분산 GPU 학습을 자동으로 처리한다
체크포인트: AutoTrain으로 BERT 분류기를 파인튜닝하는 데 약 15분 소요. 같은 작업을 코드로 직접 작성하면 약 3시간이 걸린다(Hugging Face 공식 문서). 학습 완료 후 Hugging Face Hub에 모델이 자동 배포된다.
Apple CreateML (Mac 사용자 전용): Xcode에 내장된 CreateML은 이미지 인식, 텍스트 분류, 사운드 분류, 정형 데이터 예측 모델을 드래그 앤 드롭으로 만들 수 있다. 만든 모델은 CoreML 포맷으로 내보내져 iOS/macOS 앱에 직접 탑재된다. CreateML 자체는 무료지만, App Store 배포를 위해서는 Apple Developer Program($99/년)이 필요하다.
Step
4: Python + 코드 기반 ML (현재 4/5단계 | ~1-3개월)
No-Code 도구의 한계를 넘어서려면 코드가 필요하다. 커스텀 데이터 전처리, 모델 아키텍처 수정, 하이퍼파라미터 튜닝 등은 코드 없이는 불가능하다.
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2
)
model = RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
print(f"정확도: {model.score(X_test, y_test):.2%}")
체크포인트: 위 코드를 Google Colab에 붙여넣고 실행했을 때 "정확도: 95%" 이상이 나오면 성공. 약 5분 소요.
추천 학습 경로: Kaggle의 "Intro to Machine Learning" 무료 과정으로 시작해서, Andrew Ng의 Machine Learning Specialization(Coursera, 무료 청강)으로 확장한다. Reddit r/MachineLearning에서 입문자들이 반복적으로 추천하는 조합이다. 다만 Reddit 사용자들은 "fast.ai나 Stanford CS229를 기초 없이 바로 시작하면 너무 가파르다"고 경고한다.
이후 PyTorch로 넘어가면 전이학습, 파인튜닝, GPU 학습을 직접 코드로 제어할 수 있다:
import torch
from torchvision import models
model = models.resnet50(pretrained=True)
num_classes = 2
model.fc = torch.nn.Linear(model.fc.in_features, num_classes)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
이 코드는 Teachable Machine이 내부에서 하는 것과 본질적으로 같은 작업이다. 사전 학습된 ResNet50을 가져와서 마지막 분류 레이어만 교체한 뒤, 사용자 데이터로 파인튜닝한다.
Step
5: LLM API + 프로덕션 AI (현재 5/5단계 | 지금 바로 가능)
2026년 현재, 딥러닝 모델을 직접 학습시키지 않아도 GPT나 Claude의 API를 활용해 강력한 AI 기능을 만들 수 있다. 이 단계는 Level 0-4 순서와 무관하게 지금 바로 시작 가능하다.
from anthropic import Anthropic
client = Anthropic()
def analyze_content(text: str) -> str:
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
messages=[{"role": "user", "content": f"다음 텍스트를 분석해주세요:
{text}"}]
)
return response.content[0].text
LLM API의 강점은 학습 데이터 준비, 모델 학습, GPU 인프라 없이도 텍스트 분석, 분류, 요약, 코드 생성 등 다양한 AI 기능을 즉시 구현할 수 있다는 점이다. 모델을 직접 학습시키는 Level 2-3과 LLM API를 활용하는 Level 4는 상호 배타적이 아니다. 예를 들어 이미지 분류는 직접 학습시킨 모델이 더 정확하고 저렴할 수 있고, 텍스트 이해/생성은 LLM API가 압도적으로 편리하다.
트러블슈팅

모델 정확도가 낮을 때
가장 흔한 원인은 데이터 부족이다. Flowygo에 따르면 ML 프로젝트의 85%가 부적절한 데이터로 인해 실패한다. 해결 순서:
- 클래스당 최소 200장 이상의 데이터를 확보한다 (Teachable Machine은 30장으로도 동작하지만, 프로덕션 수준의 정확도를 원한다면 200장 이상이 필요하다)
- 배경, 조명, 각도의 다양성을 확보한다. 같은 배경에서만 촬영하면 모델이 배경을 학습해버린다(배경 과적합)
- 클래스 간 데이터 수 균형을 맞춘다. A 클래스 500장, B 클래스 50장이면 모델은 무조건 A로 분류하는 편향을 학습한다
- 신뢰도 임계값을 70% 이상으로 설정해서 불확실한 예측을 걸러낸다
과적합(Overfitting) 발생 시
학습 정확도는 99%인데 새로운 데이터에 대한 정확도가 60% 이하라면 과적합이다. 초보자가 수백 개 데이터로 복잡한 신경망을 학습시킬 때 흔히 발생한다(Exxact). 해결법:
- 데이터 증강(augmentation) 적용: 이미지를 회전, 반전, 크롭해서 학습 데이터를 인위적으로 늘린다
- Dropout 레이어 추가: 학습 중 무작위로 뉴런을 비활성화해서 특정 패턴에 과도하게 의존하는 것을 방지한다
- 조기 종료(Early Stopping) 설정: 검증 손실이 더 이상 줄어들지 않으면 학습을 자동 중단한다
Python 환경 관련 에러
ModuleNotFoundError:pip install {패키지명}으로 누락된 패키지 설치. 가상환경(venv) 활성화 여부도 확인한다- CUDA 관련 에러: GPU 드라이버 버전과 PyTorch CUDA 버전의 호환성을 확인한다.
torch.cuda.is_available()이False를 반환하면 CPU 모드로 전환한다 - Shape 불일치 에러: 입력 데이터의 차원(shape)이 모델이 기대하는 것과 다를 때 발생한다.
tensor.shape로 차원을 확인하고reshape()또는unsqueeze()로 조정한다
LLM API 호출 실패
- 401/403 에러: API 키가 올바르게 환경변수에 설정됐는지 확인한다
- 429 에러 (Rate Limit): 지수 백오프(exponential backoff)로 재시도한다. 대부분의 SDK에 내장 재시도 로직이 있다
- 413 에러: 입력 텍스트가 모델의 컨텍스트 윈도우를 초과했다. 텍스트를 분할해서 전송한다
더 알아보기
- 심화 학습 경로: Fast.ai의 "Practical Deep Learning for Coders"는 이 가이드의 Level 2-3을 깊이 다룬다. 기본 코딩 경험이 있다면 바로 시작 가능하다. Andrew Ng의 Deep Learning Specialization(Coursera)은 이론적 기초를 탄탄히 다지고 싶을 때 적합하다.
- 관련 도구/서비스: Kaggle(데이터셋 + 무료 GPU + 커뮤니티), Google Colab(무료 Jupyter 노트북 + GPU), Hugging Face Hub(사전학습 모델 + 데이터셋 + 배포)
- 공식 문서: Teachable Machine, PyTorch 튜토리얼, Hugging Face AutoTrain, scikit-learn 공식 문서