GPT-5.4 vs Claude Opus 4.6 vs Gemini 2.5 Pro: 코딩이면 Claude, 가성비면 Gemini, 범용 속도면 GPT
2026년 4월 기준, AI 모델 3강 구도가 확실해졌다. OpenAI는 3월 11일 GPT-5.4를 출시했고, Anthropic은 2월 5일 Claude Opus 4.6을, Google DeepMind는 2월 말 Gemini 2.5 Pro를 내놓았다. 셋 다 전작 대비 눈에 띄는 성능 향상을 보여주지만, 강점 영역이 명확히 갈린다. 결론부터 말하면: 복잡한 소프트웨어 엔지니어링과 한국어 콘텐츠 생성에는 Claude Opus 4.6, API 비용 효율과 멀티모달 처리에는 Gemini 2.5 Pro, 빠른 응답 속도와 성숙한 도구 생태계가 필요하면 GPT-5.4다.
한눈에 보는 비교
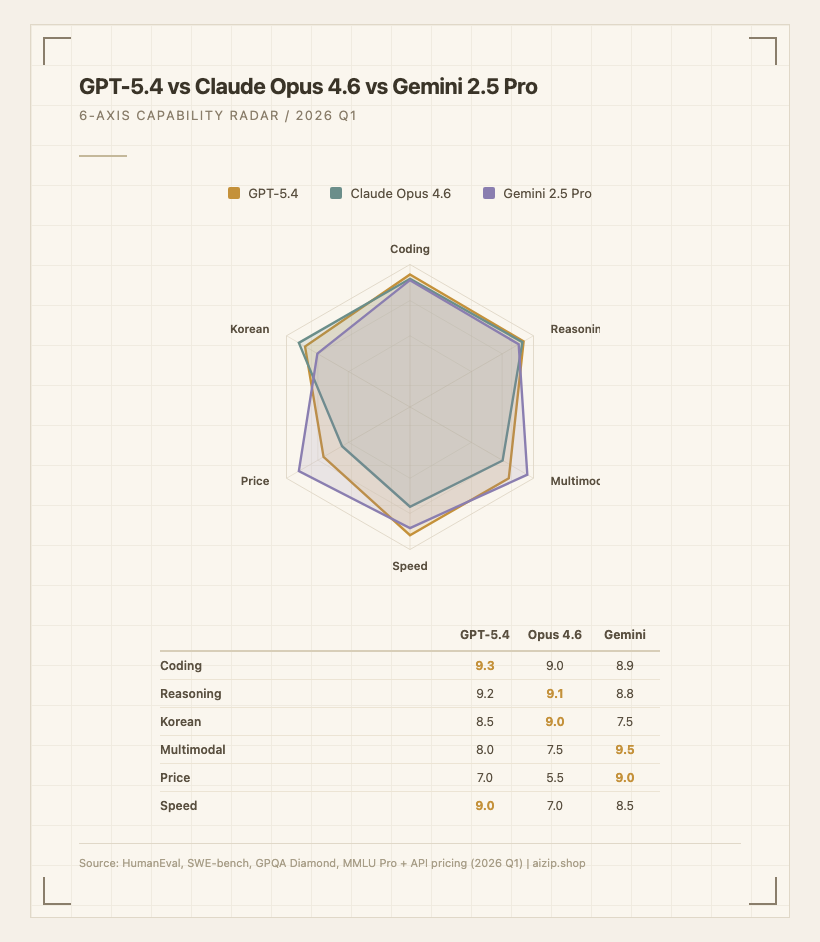
위 레이더 차트의 점수는 아래 벤치마크와 실측 데이터에서 도출했다. 각 축의 근거를 정리하면 다음과 같다.
Coding (GPT-5.4: 9.3 / Opus 4.6: 9.0 / Gemini: 8.9) - HumanEval Pass@1에서 GPT-5.4가 93.1%로 1위, Claude Opus 4.6이 90.4%, Gemini 2.5 Pro가 89.2%를 기록했다. 다만 SWE-bench Verified(실제 GitHub 이슈 해결)에서는 Claude Opus 4.6이 80.8%로 역전한다. HumanEval은 단일 함수 생성 능력을, SWE-bench는 멀티파일 코드베이스 이해와 수정 능력을 측정하는데, 실무에서는 후자가 더 중요하다.
Reasoning (GPT-5.4: 9.2 / Opus 4.6: 9.1 / Gemini: 8.8) - GPQA Diamond(대학원 수준 과학 추론)에서 Opus 4.6이 87.4%로 GPT-5.4(83.9%)를 3.5포인트 앞선다. 반면 MMLU Pro에서는 GPT-5.4가 92.3%로 근소하게 리드. MATH 벤치마크는 GPT-5.4 94.8%, Gemini 94.6%, Opus 94.1%로 사실상 동급이다.
Korean (GPT-5.4: 8.5 / Opus 4.6: 9.0 / Gemini: 7.5) - Claude Opus 4.6은 한국어 구조적 글쓰기(보고서, 분석, 존댓말/반말 전환)에서 가장 일관된 품질을 보인다. GPT-5.4는 자연스러운 구어체와 비즈니스 문서에 강하지만 간혹 번역투가 섞인다. Gemini 2.5 Pro는 한국어 생성보다 검색 기반 요약에 더 적합하며, 직역투가 가장 자주 나타난다.
Multimodal (GPT-5.4: 8.0 / Opus 4.6: 7.5 / Gemini: 9.5) - Gemini 2.5 Pro는 네이티브 비디오 이해(최대 3시간 영상을 단일 프롬프트로 처리), 오디오 처리, Google 검색 그라운딩을 지원한다. GPT-5.4와 Claude는 이미지 입력은 지원하지만 네이티브 비디오/오디오 처리가 없다.
Price (GPT-5.4: 7.0 / Opus 4.6: 5.5 / Gemini: 9.0) - 1M 토큰당 입력/출력 기준으로 Gemini 2.5 Pro(10)가 가장 저렴하고, GPT-5.4(15)가 중간, Claude Opus 4.6(25)이 가장 비싸다. Opus 4.6은 이전 세대(Opus 4.1의 75) 대비 67% 인하됐지만 여전히 프리미엄 가격대다.
Speed (GPT-5.4: 9.0 / Opus 4.6: 7.0 / Gemini: 8.5) - 출력 토큰/초 기준 GPT-5.4가 약 80 TPS로 가장 빠르고, Gemini 2.5 Pro가 약 75 TPS, Claude Opus 4.6이 약 55 TPS로 가장 느리다.
항목별 상세 비교
코딩: Claude가 실전에서 앞선다
벤치마크 숫자만 보면 GPT-5.4가 HumanEval에서 2.7포인트 앞서지만, 실무 개발자에게 더 중요한 SWE-bench Verified에서는 Claude Opus 4.6이 80.8%로 GPT-5.4(52.7%)를 크게 앞선다. SWE-bench는 실제 GitHub 이슈를 모델이 코드 수정으로 해결하는 테스트인데, 멀티파일 코드 이해와 일관된 수정 능력이 핵심이다.
GPT-5.4는 Terminal-Bench 2.0(명령줄 자동화 및 DevOps 태스크)에서 75.1%로 에이전틱 실행 태스크에서 강점을 보인다. 복잡한 API 오케스트레이션 작업에서도 GPT-5.4가 더 안정적이라는 평가가 다수다.
Gemini 2.5 Pro는 코딩 벤치마크 전반에서 두 모델보다 약간 뒤처진다. 다만 200만 토큰 컨텍스트 윈도우 덕분에 대규모 코드베이스를 한 번에 읽어서 분석하는 데는 유일한 선택지다.
결론적으로 코딩 에이전트(멀티파일 리팩터링, 자기 교정 워크플로우)에는 Claude Opus 4.6이, DevOps 자동화와 API 연동에는 GPT-5.4가, 초대형 코드베이스 분석에는 Gemini가 각각 적합하다.
추론 능력: 미묘한 차이, 분야별 강점
수학적 추론(MATH 94.8% vs 94.1%)에서는 GPT-5.4가 근소하게 앞서고, 과학 추론(GPQA Diamond 87.4% vs 83.9%)에서는 Claude Opus 4.6이 3.5포인트 차로 리드한다. MMLU Pro(종합 지식)에서는 GPT-5.4가 92.3%로 0.6포인트 앞선다.
실사용 관점에서 보면, GPT-5.4는 복잡한 체인 오브 쏘트(chain-of-thought) 추론과 수학적 증명에서 강하고, Claude Opus 4.6은 뉘앙스가 있는 텍스트 해석과 지시사항 정확도에서 강점이 있다. 두 모델 모두 일반적인 추론 태스크에서는 사실상 동급이며, 차이가 나는 것은 극한 난이도의 전문 영역뿐이다.
가격: 시나리오별 월 비용 시뮬레이션
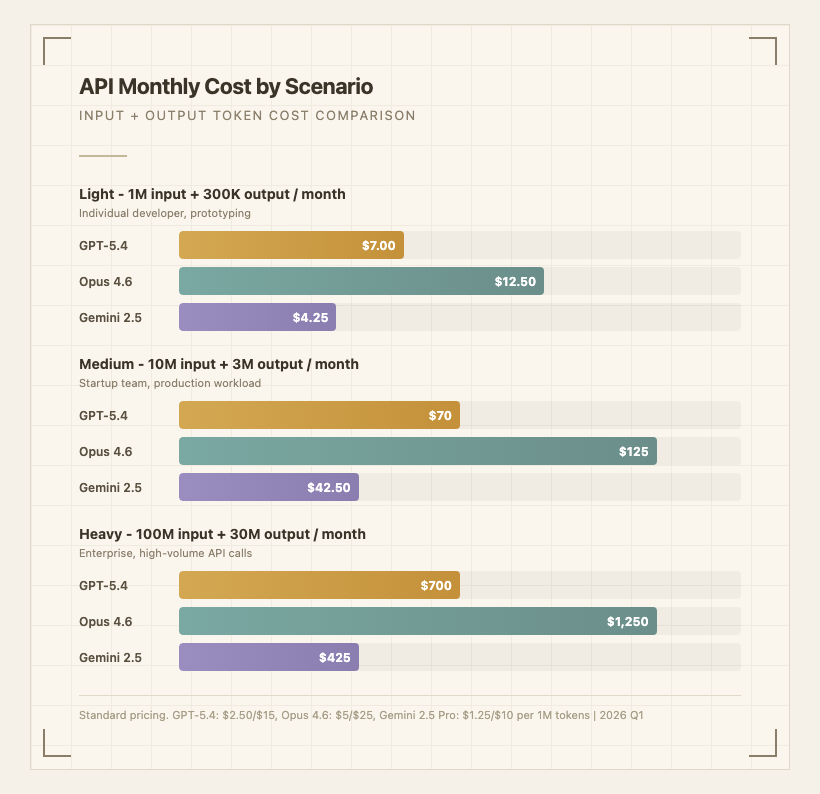
위 차트는 배치/캐싱 할인을 적용하지 않은 표준 가격 기준이다. 각 시나리오의 가정과 숨겨진 비용을 살펴보면:
Light (개인 개발자, 프로토타이핑) - 월 1M 입력 + 300K 출력 토큰 사용 시 Gemini 2.5 Pro가 7.00)의 60%, Opus 4.6($12.50)의 34% 수준이다. 개인 개발자가 실험 단계에서 비용을 최소화하려면 Gemini가 압도적이다.
Medium (스타트업 팀, 프로덕션) - 월 10M 입력 + 3M 출력 기준 Gemini 70, Opus 4.6 0.50/1M으로 90% 줄어든다. 반복 컨텍스트가 많은 워크로드라면 실제 비용 격차가 상당히 줄어든다.
Heavy (엔터프라이즈) - 월 100M 입력 + 30M 출력 규모에서는 Gemini 700 vs Opus $1,250으로 격차가 절대적이다. 다만 세 제공사 모두 배치 처리 시 약 50% 할인을 제공하므로, 실시간 응답이 필요 없는 워크로드는 배치로 전환하면 비용을 절반으로 줄일 수 있다.
추가로 고려해야 할 숨겨진 비용: OpenAI Assistants API는 스레드 스토리지 비용이 별도로 발생하고, Claude는 200K 이상 컨텍스트 사용 시 입출력 가격이 2배로 뛴다. Gemini도 200K 이상에서 입력 15로 올라간다.
한국어 사용자 특화 비교
세 모델 모두 2026년 기준 한국어를 "잘" 처리하지만, 뉘앙스 차이가 분명하다.
Claude Opus 4.6은 한국어 구조적 글쓰기에서 가장 안정적이다. 보고서, 분석문, 공식 문서 작성 시 논리 흐름과 문단 구성이 자연스럽고, 존댓말/반말 전환 요청에 정확히 반응한다. 긴 문서 요약에서도 핵심을 놓치지 않는 경향이 있다.
GPT-5.4는 구어체 한국어와 비즈니스 이메일에 강하다. 한국 문화 맥락 이해도가 높아서 상황에 맞는 표현을 잘 골라 쓴다. 다만 기술 문서 번역에서 간간이 영어 표현을 그대로 옮긴 듯한 문장이 나온다.
Gemini 2.5 Pro는 Google 검색 그라운딩 덕분에 최신 한국어 정보 검색과 요약에서 강점이 있지만, 한국어 생성 품질 자체는 두 모델에 미치지 못한다. 번역투가 가장 빈번하게 나타나며, 긴 한국어 글 작성에는 부적합하다.
국내 결제 편의성 측면에서는 ChatGPT(원화 결제 지원)와 Gemini(Google Workspace 통합)가 Claude(달러 결제만 가능)보다 유리하다.
실사용자는 뭐라고 하나
커뮤니티 의견을 종합하면 "도구(IDE/환경)가 모든 것을 결정한다"는 공감대가 형성되어 있다. 모델 자체의 차이보다 어떤 환경에서 쓰느냐가 체감 품질을 더 크게 좌우한다는 뜻이다.
코딩 분야 사용자 의견 - Composio의 실제 코딩 태스크 3건 테스트에서 Claude Opus 4.6이 복잡한 멀티파일 작업에서 일관성 있게 수정을 유지하는 반면, GPT-5.4는 단일 파일 태스크에서 더 빠르고 정확했다. Sonar의 코드 품질 분석에서도 세 모델 모두 첫 시도에 동작하는 코드를 생성하지만, 코드 품질(중복, 보안 취약점) 측면에서 Claude가 가장 깔끔한 코드를 생산한다는 결과가 나왔다. (출처: Composio 블로그, Sonar 코드 품질 리포트)
콘텐츠 생성 사용자 의견 - xFunnel의 비교 리뷰에 따르면, Claude Opus 4.6은 장문 콘텐츠에서 지시사항을 가장 정확히 따르며 일관된 글을 생산하는 반면, GPT-5.4는 마케팅 카피에서 강하지만 블로그 글쓰기에서는 기대에 못 미친다는 평가를 받았다. Gemini는 Google 검색 연동이 필요한 실시간 정보 기반 콘텐츠에서 차별화된다. (출처: xFunnel AI 블로그)
비용 대비 가치 의견 - 다수의 리뷰에서 Claude Opus 4.6이 대화당 GPT-5.4 대비 약 3배 비용이 드는 것으로 나타났다. 품질 차이가 비용 프리미엄을 정당화하느냐는 용도에 따라 갈린다. 코딩 에이전트처럼 정확성이 곧 시간 절약인 영역에서는 정당화되지만, 일반 질의응답에서는 과한 투자라는 의견이 많다. (출처: AI Magicx, LemonData 비교 리뷰)
누가 뭘 쓰면 되나 (Editor's Pick)
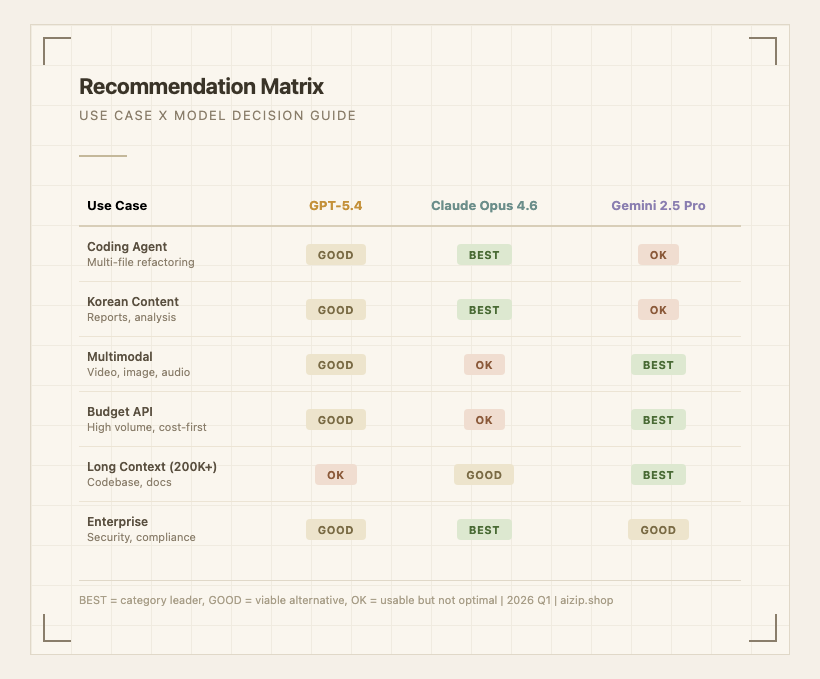
각 추천의 근거와 예외 조건:
코딩 에이전트 -> Claude Opus 4.6 - SWE-bench 80.8%로 실제 코드 수정 능력 1위. 멀티파일 리팩터링, 자기 교정 워크플로우에서 가장 안정적. 예외: DevOps 자동화/CLI 태스크 위주라면 GPT-5.4의 Terminal-Bench 75.1%가 더 적합하다.
한국어 콘텐츠 -> Claude Opus 4.6 - 보고서, 분석문, 구조적 글쓰기에서 가장 자연스러운 한국어 품질. 예외: 짧은 마케팅 카피나 구어체 대화에는 GPT-5.4도 충분하다.
멀티모달 -> Gemini 2.5 Pro - 네이티브 비디오/오디오 처리 지원. 3시간 영상을 단일 프롬프트로 분석 가능. 다른 두 모델에는 이 기능이 없다.
예산 우선 API -> Gemini 2.5 Pro - 동일 워크로드 기준 Claude 대비 1/3, GPT 대비 60% 비용. 품질 차이가 크지 않은 범용 태스크에서는 가장 합리적.
초대형 컨텍스트 -> Gemini 2.5 Pro - 200만 토큰 컨텍스트는 GPT-5.4(128K)의 15배, Claude(200K)의 10배. 500K+ 토큰이 필요한 워크로드에서는 사실상 유일한 선택지.
엔터프라이즈/컴플라이언스 -> Claude Opus 4.6 - Anthropic의 보안 우선 설계 철학, 명확한 버전 정책(날짜 고정 버전 유지), 엔터프라이즈 고객 지원이 강점. 예외: GCP 기반 인프라라면 Vertex AI 통합이 되는 Gemini가 운영 부담이 적다.
승자 선언: 용도를 모르겠으면 Claude Opus 4.6을 기본으로 쓰고, 비용이 부담되면 Gemini 2.5 Pro로 대체하라. GPT-5.4는 이미 OpenAI 생태계에 깊이 들어간 팀에게 최적이다.
6개월 후 재평가이 비교가 뒤집힐 수 있는 조건 3가지:
1. GPT-6 또는 Claude 5 출시 - OpenAI와 Anthropic 모두 2026년 하반기 차세대 모델을 예고하고 있다. 현재 비교는 2026년 Q1 기준이며, 새 모델이 나오면 벤치마크 순위가 완전히 재편될 수 있다. 특히 OpenAI가 SWE-bench 격차를 줄이면 코딩 영역 판도가 바뀐다.
2. Gemini의 한국어 품질 개선 - Google이 한국어 파인튜닝에 투자를 확대하면 Gemini가 가격+한국어 품질 모두에서 우위를 점할 가능성이 있다. 현재 Gemini의 약점은 한국어 생성 품질인데, 이것만 해결되면 가성비 측면에서 압도적 1위가 된다.
3. 오픈소스 모델의 추격 - Llama 4, Qwen 3 등 오픈소스 모델이 프론티어 모델과의 격차를 빠르게 좁히고 있다. 자체 호스팅 비용이 API 비용보다 낮아지는 시점이 오면, 세 제공사 모두 가격 인하 압박을 받게 된다.