비교2026년 4월 5일
Cursor vs Claude Code vs Copilot: 2026 AI 코딩 어시스턴트 최종 비교
## Cursor vs Claude Code vs GitHub Copilot: 핵심 차이 한줄 요약
일상 코딩 편집은 Cursor, 복잡한 아키텍처 설계와 디버깅은 Claude Code, 최소 비용으로 시작하려면 GitHub Copilot. 2026년 Q2 기준, 가장 생산적인 개발자들은 하나만 쓰지 않는다. Cursor + Claude Code 조합이 가장 흔한 스택이 되었다.
## 한눈에 보는 비교
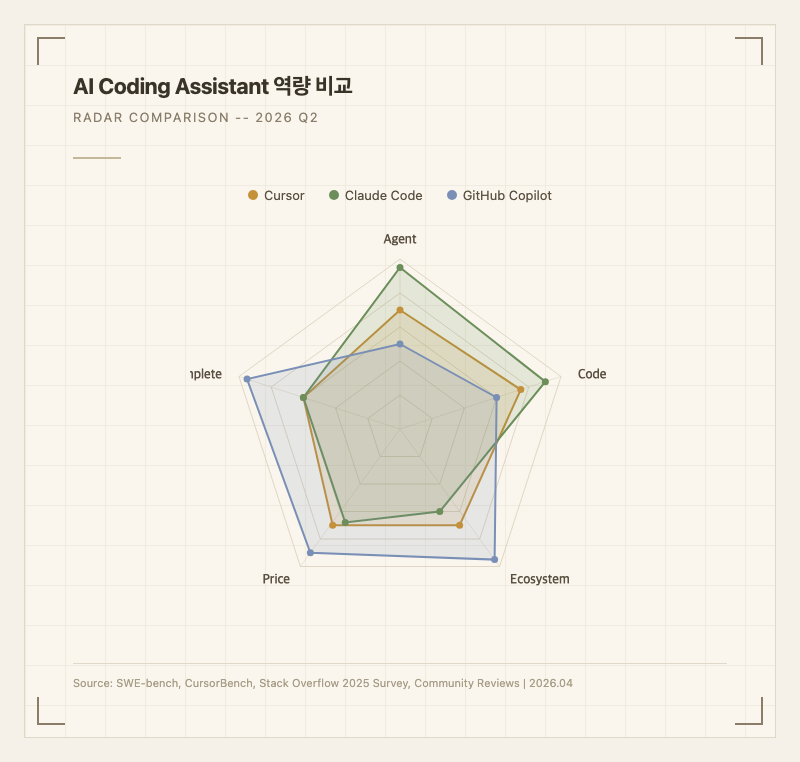
위 레이더 차트는 SWE-bench 벤치마크 점수, UX/IDE 통합도, 생태계 확장성, 컨텍스트 윈도우 크기, 에이전트 자율성 5개 축으로 세 도구를 비교한 것이다. 점수 산출 근거는 다음과 같다.
**SWE-bench**: Claude Code의 핵심 모델인 Opus 4.6이 SWE-bench Verified에서 80.8%를 기록했다. 이는 실제 GitHub 이슈를 자동으로 해결하는 능력을 측정하는 벤치마크로, 현존 AI 코딩 모델 중 최고 점수다. Cursor는 자체 CursorBench에서 Composer 2가 61.3점을 기록했고, SWE-bench Multilingual에서 73.7%를 달성했다. GitHub Copilot은 자체 벤치마크를 공개하지 않아 직접 비교가 어렵다.
**UX/IDE 통합**: Cursor는 VS Code 포크 기반으로 기존 VS Code 사용자가 즉시 적응할 수 있고, Supermaven 인라인 자동완성이 업계에서 가장 빠르다는 평가를 받는다. GitHub Copilot은 VS Code, JetBrains, Neovim 등 10개 이상 IDE를 지원하는 유일한 도구다. Claude Code는 터미널 네이티브 CLI 도구로, IDE 통합은 VS Code 확장 등을 통해 간접적으로 제공된다. GUI 없이 터미널에서 작업하는 것을 선호하는 개발자에게는 장점이지만, 일반적인 IDE 워크플로우에서는 별도 창을 오가야 하는 단점이 있다.
**생태계/통합**: Copilot은 GitHub Actions, GitHub Issues, Pull Request 리뷰까지 이어지는 Microsoft/GitHub 생태계와의 통합이 압도적이다. 2026년 3월부터 에이전트 코드 리뷰가 GA되면서, 코드 작성부터 리뷰까지 한 플랫폼에서 가능해졌다. Cursor는 멀티모델 지원(Claude Opus 4.6, GPT-5.4 등)과 Background Agents로 사용자가 다른 작업을 하는 동안 자율적으로 코드를 작성하는 기능이 있다. Claude Code는 Agent Teams 기능으로 복수 에이전트가 협업하는 구조를 지원하고, git과 깊이 통합되어 커밋, 브랜치, PR 생성을 자동화한다.
**컨텍스트 윈도우**: Claude Code는 100만 토큰 컨텍스트 윈도우를 지원한다. 대규모 코드베이스의 여러 파일을 한 번에 이해하는 데 결정적인 이점이다. Cursor와 Copilot은 128K 토큰 수준으로, 대형 프로젝트에서는 컨텍스트가 잘리는 경험을 하게 된다.
**에이전트 자율성**: Claude Code는 "결과를 설명하면 AI가 코드를 작성하는" 방식으로 작동한다. Cursor는 Composer 기능으로 멀티파일 편집을 처리하지만, 여전히 사용자가 편집 방향을 주도한다. Copilot의 에이전트 모드는 GitHub Issue를 자동으로 PR로 변환하는 기능을 제공하지만, 복잡한 아키텍처 변경에서는 Claude Code에 비해 추론 깊이가 부족하다는 평가가 많다.
## 항목별 상세 비교
### 인터랙션 모델: 근본적으로 다른 세 가지 접근
GitHub Copilot은 반응형 자동완성이 핵심이다. 코드를 쓰는 도중에 다음 줄을 예측해서 제안한다. 2026년 기준으로도 인라인 자동완성만 놓고 보면 가장 빠르고 자연스럽다. Stack Overflow 2025 개발자 설문에서 "일상적 자동완성에 가장 많이 사용하는 도구"로 51%의 선택을 받았다. 단순 반복 코드를 빠르게 작성하는 데는 여전히 최적이지만, 복잡한 멀티파일 변경에서는 한계가 명확하다.
Cursor는 협업형 AI 에디터다. 코드베이스 전체를 인덱싱해서 개발자의 코딩 패턴을 학습하고, 기존 코드 스타일에 맞는 제안을 한다. Reddit의 한 시니어 개발자(5년차 풀스택)는 "Cursor가 내 코드 패턴을 이해하고 제안하는 수준이 인턴 수준에서 주니어 수준으로 올라갔다"고 평가했다. Composer 2는 여러 파일에 걸친 리팩토링을 한 번의 지시로 처리하며, CursorBench 점수가 이전 버전 대비 37% 향상되었다(출처: Cursor 공식 블로그).
Claude Code는 자율형 에이전트다. 개발자가 "이 API 엔드포인트에 인증 미들웨어를 추가하고 테스트를 작성해"라고 지시하면, Claude Code가 관련 파일을 탐색하고, 코드를 작성하고, 테스트를 돌리고, 에러를 수정하는 전 과정을 자율적으로 처리한다. Faros AI의 엔지니어링 팀은 Claude Code를 "다른 도구가 실패했을 때 꺼내는 최종 병기"로 사용한다고 밝혔다(출처: Faros AI 블로그). 한 개발자는 8개월간 100억 토큰을 사용했는데, 월 $100 정액제가 아니었다면 API 요금만 $15,000에 달했을 것이라고 계산했다.
### 코드 품질과 추론 능력
"복잡한 태스크(멀티파일 리팩토링, 아키텍처 설계, 하드 디버깅)에 어떤 도구를 사용하느냐"는 질문에 Claude Code가 44%로 1위, GitHub Copilot 28%, ChatGPT 19% 순이었다(출처: 2026 개발자 설문, 15,000명 대상). Claude Code가 아키텍처적으로 가장 건전한 코드를 생성한다는 평가는 여러 비교 리뷰에서 반복된다. "시스템을 설계해달라고 하면 에지 케이스, 에러 핸들링, 유지보수성까지 고려하는 수준이 시니어 엔지니어와 작업하는 느낌"이라는 DEV Community의 30일 비교 리뷰가 대표적이다.
반면 Cursor는 기존 코드 패턴에 맞는 코드를 생성하는 데 강하다. 새로운 아키텍처를 제안하는 것보다, 이미 정해진 패턴 안에서 코드를 빠르고 일관되게 작성하는 데 최적화되어 있다. Copilot의 에이전트 모드는 "적절한 수준"이라는 평가를 받지만, 파워 유저들은 "Claude Code 대비 추론 깊이가 부족하다"고 지적한다(출처: Faros AI).
다만, AI 생성 코드의 정확성에 대한 우려도 커지고 있다. Stack Overflow 2025 설문에서 46%의 개발자가 AI 생성 코드의 정확성을 불신한다고 응답했고, 66%가 "거의 맞지만 완전히 맞지 않은 AI 솔루션"을 가장 큰 불만으로 꼽았다. 이 문제는 세 도구 모두에 해당하지만, 컨텍스트 이해 능력이 높은 Claude Code와 Cursor가 할루시네이션 비율에서 상대적으로 나은 편이다.
### 가격: 시나리오별 비교
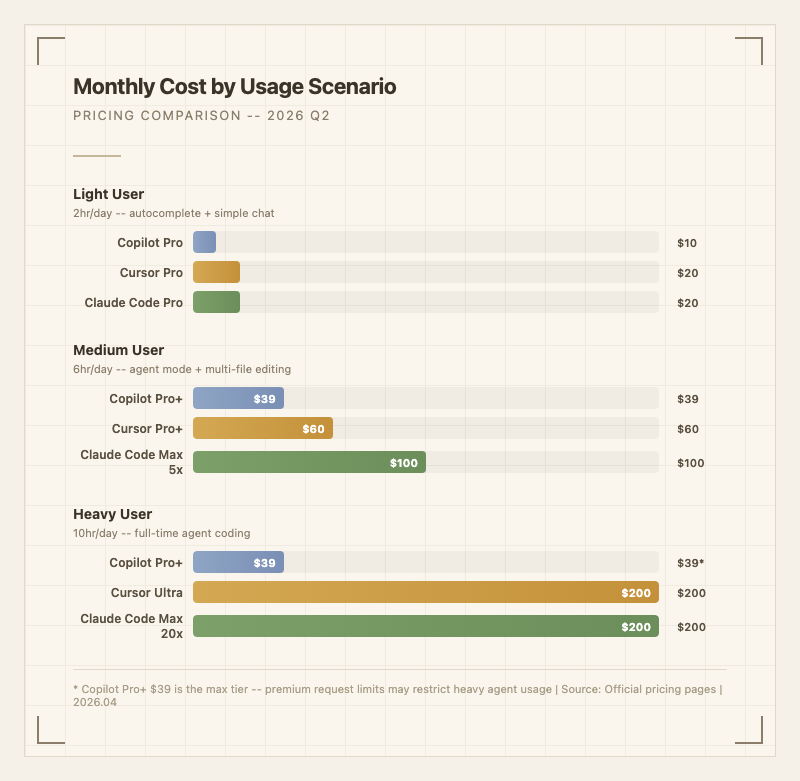
**라이트 사용자** (하루 2시간, 자동완성 + 간단한 채팅): GitHub Copilot Pro가 $10/월로 가장 저렴하다. 2,000회 자동완성과 50회 채팅이 포함되며, 가벼운 사용에는 충분하다. Windsurf Pro $15, Cursor Pro와 Claude Code Pro가 각각 $20이다. Copilot Free 티어(2,000회 자동완성, 50회 채팅)도 이 사용 패턴에서는 무료로 버틸 수 있다.
**미디엄 사용자** (하루 6시간, 에이전트 모드 + 멀티파일 편집): Copilot Pro+가 $39/월이지만 프리미엄 요청 한도가 있다. Windsurf Teams $30, Cursor Pro+ $60. Claude Code Max 5x가 $100/월인데, 정액제라 토큰 단위로 과금되지 않는 것이 장점이다. 이 구간에서는 "얼마나 자주 에이전트 모드를 쓰느냐"가 비용을 결정한다.
**헤비 사용자** (하루 10시간, 전일 에이전트 코딩): Cursor Ultra, Claude Code Max 20x, Windsurf Max 모두 $200/월로 수렴한다. Copilot은 Pro+ $39가 최고 티어인데, 프리미엄 요청 한도 때문에 실제 헤비 사용에서는 제한이 걸린다. 이 구간의 실질적 선택지는 Cursor Ultra vs Claude Code Max 20x다.
**숨겨진 비용**: Cursor Business는 개발자당 $40/월이지만 10명 팀 연간 $4,800. Claude Code Teams는 개발자당 $150/월로 10명 팀 연간 $18,000. GitHub Copilot Business는 $19/월로 10명 팀 연간 $2,280. 팀 규모가 클수록 Copilot의 가격 경쟁력이 두드러진다.
### 한국어 사용자 특화 비교
세 도구 모두 인터페이스 언어는 영어 기반이다. 한국어 프롬프트 성능은 사용하는 LLM 모델에 의존한다. Claude Code는 Claude Opus 4.6을 사용하며, Cursor는 Claude Opus 4.6과 GPT-5.4를 선택할 수 있고, Copilot은 내부적으로 모델을 자동 선택한다. 한국어 코드 주석, 변수명, 문서 생성 측면에서 Claude 계열 모델이 상대적으로 자연스러운 한국어를 생성한다는 커뮤니티 평가가 있으나, 체계적인 벤치마크는 확인되지 않았다.
결제 편의성 측면에서는 세 서비스 모두 해외 신용카드 결제가 가능하다. GitHub Copilot은 GitHub 계정에 통합되어 기존 GitHub 유료 플랜 사용자에게 가장 편리하다.
## 실사용자는 뭐라고 하나
**Reddit r/programming의 풀스택 개발자(경력 7년)**: "Cursor에서 Claude Code로 중간에 전환했다. Cursor는 일상적인 기능 구현과 리팩토링에서 훌륭하지만, 100개 이상 파일에 걸친 마이그레이션 작업에서는 컨텍스트가 잘렸다. Claude Code로 같은 작업을 하니 전체 코드베이스를 한 번에 이해하고 일관된 변경을 적용했다. 결국 Cursor(일상) + Claude Code(복잡한 작업) 조합으로 정착했다." (출처: Reddit r/programming)
**DEV Community의 30일 비교 리뷰어**: "Copilot은 AI 코딩 도구의 Toyota Camry다. 신뢰할 수 있고, 어디서든 쓸 수 있지만, 특출나지는 않다. Cursor는 사용하면 할수록 내 코드 패턴을 이해하는 게 느껴진다. Claude Code는 어려운 문제를 던졌을 때 가장 인상적인 결과를 낸다." (출처: DEV Community)
**Reddit에서의 Cursor 비용 불만**: "Cursor: 더 내고, 덜 받고, 어떻게 작동하는지 묻지 마라"라는 댓글이 높은 추천을 받았다. Cursor의 가격 모델 변경에 대한 비판이 커뮤니티에서 반복적으로 등장한다. 반면 Claude Code의 정액제 Max 플랜에 대해서는 "토큰 걱정 없이 쓸 수 있어서 좋다"는 평가가 많지만, Anthropic이 백그라운드 연속 실행 사용자에 대한 속도 제한을 도입하면서 "작업 중간에 한도에 걸려 잠기는" 경험에 대한 불만도 나오고 있다. (출처: Reddit, Faros AI)
## 누가 뭘 쓰면 되나 (Editor's Pick)
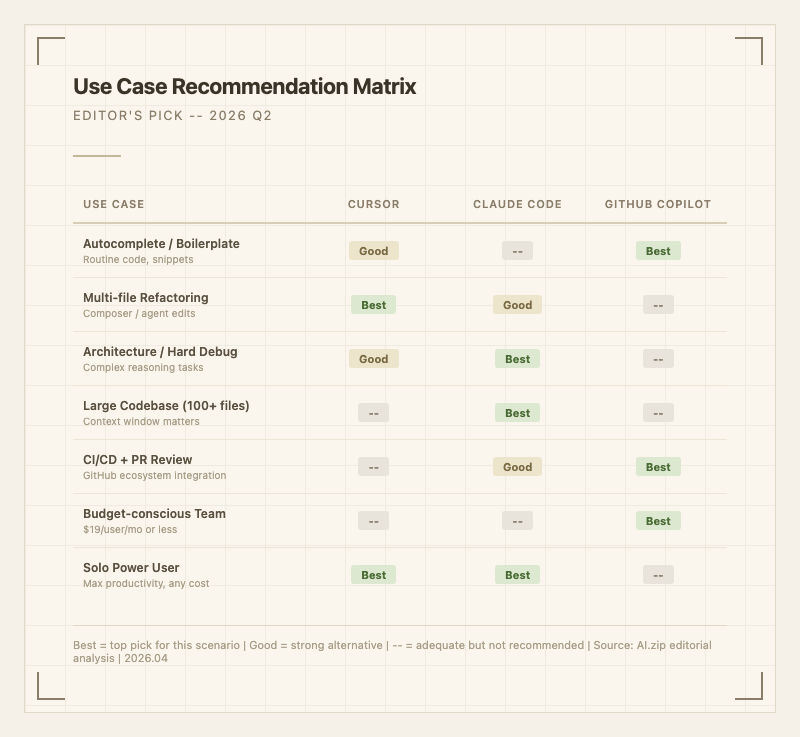
**입문/주니어 + 저예산**: GitHub Copilot Pro ($10/월). 학습 곡선이 가장 낮고, VS Code/JetBrains 어디서든 바로 쓸 수 있다. 무료 티어만으로도 충분히 AI 코딩을 체험할 수 있다.
**중급 개발자 + 일상 생산성**: Cursor Pro ($20/월). Composer로 멀티파일 편집을 경험하면 다른 도구로 돌아가기 어렵다. 코드베이스 인덱싱 덕분에 프로젝트가 커질수록 Cursor의 강점이 부각된다.
**시니어/아키텍트 + 복잡한 코드베이스**: Cursor Pro ($20) + Claude Code Pro ($20) = $40/월 조합. 일상 편집은 Cursor에서, 아키텍처 변경이나 대규모 리팩토링은 Claude Code에서 처리하는 것이 2026년 현시점 가성비 최적 조합이다. McKinsey의 2026년 2월 조사에 따르면, AI 코딩 도구는 루틴 코딩 시간을 평균 46% 줄여준다. 이 생산성 향상의 가장 큰 부분을 차지하는 것이 "적재적소에 맞는 도구 조합"이다.
**헤비 유저/풀타임 AI 코딩**: Cursor Ultra ($200) 또는 Claude Code Max 20x ($200). 하루 10시간 이상 에이전트 모드로 코딩한다면 이 구간의 투자가 필요하다. 둘 중 하나를 고르라면, IDE 내 경험을 중시하면 Cursor Ultra, 터미널 기반 자율 에이전트를 선호하면 Claude Code Max다.
**승자 선언**: 단일 도구로 하나만 고른다면 Cursor. IDE 통합, 자동완성 속도, 멀티파일 편집, 모델 선택의 균형이 가장 좋다. 하지만 2026년에 "하나만 써야 한다"는 전제 자체가 비현실적이다. Cursor + Claude Code 조합이 사실상 표준이 되어가고 있다.
## 6개월 후 재평가이 비교가 뒤집힐 수 있는 조건 3가지:
1. **Copilot의 모델 업그레이드**: GitHub Copilot이 현재의 자동 모델 선택 대신 Claude Opus급 모델을 기본 탑재하고, 에이전트 모드의 추론 깊이를 개선하면, $10의 가격 경쟁력과 결합되어 판세가 달라질 수 있다. 이미 Copilot은 Claude Opus 4.6을 모델 옵션으로 포함하고 있어, 추론 품질보다는 에이전트 워크플로우의 성숙도가 관건이다.
2. **Google Antigravity / Gemini CLI의 부상**: Google이 Antigravity(멀티에이전트 오케스트레이션 + 내장 Chromium 브라우저)와 Gemini CLI를 적극 밀고 있다. Gemini 3.1 Pro가 코딩 벤치마크에서 Claude Opus급 성능을 달성하면, Google 생태계(Android Studio, Firebase, GCP)와의 통합이 새로운 변수가 된다.
3. **오픈소스 에이전트의 약진**: Cline, Aider, RooCode 같은 오픈소스/BYOM(Bring Your Own Model) 도구가 "모델은 내가 고르고, 에이전트 프레임워크만 제공받는" 방식으로 성장 중이다. 특히 Cline은 VS Code 네이티브 확장으로 모델 선택의 자유도가 높고, RooCode는 대규모 멀티파일 변경에서 "에이전트 스래싱(불필요한 반복 편집)"이 적다는 평가를 받고 있다. 이 도구들이 UX를 개선하면 Cursor의 시장 지배력에 도전할 수 있다.
```references
https://lushbinary.com/blog/ai-coding-agents-comparison-cursor-windsurf-claude-copilot-kiro-2026/
https://www.faros.ai/blog/best-ai-coding-agents-2026
https://dev.to/dextralabs/claude-code-vs-cursor-vs-github-copilot-honest-comparison-after-30-days-1030
https://survey.stackoverflow.co/2025/ai
https://blog.logrocket.com/ai-dev-tool-power-rankings/
https://www.nxcode.io/resources/news/cursor-vs-claude-code-vs-github-copilot-2026-ultimate-comparison
https://chatforest.com/guides/ai-coding-assistants-compared/
https://www.amplifilabs.com/post/2026-round-up-the-top-10-ai-coding-assistants-compared-features-pricing-best-use-cases
```