Gemini 2.5 Pro
GoogleLLM자연어 처리컴퓨터 비전오디오 처리1.0M 토큰
2025년 6월 17일Proprietary
한줄 소개
Gemini 2.5 Pro는 Google DeepMind가 개발한 플래그십 추론 모델로, 2025년 3월 실험 버전 공개 후 6월 GA(정식 출시)를 거쳐 현재까지 Google의 가장 강력한 AI 모델 자리를 지키고 있다. "thinking model"이라는 이름답게 응답 전에 내부 추론 과정을 거치며, 텍스트-이미지-오디오-비디오 4종 입력을 네이티브로 처리하는 멀티모달 모델이다.
주요 특징
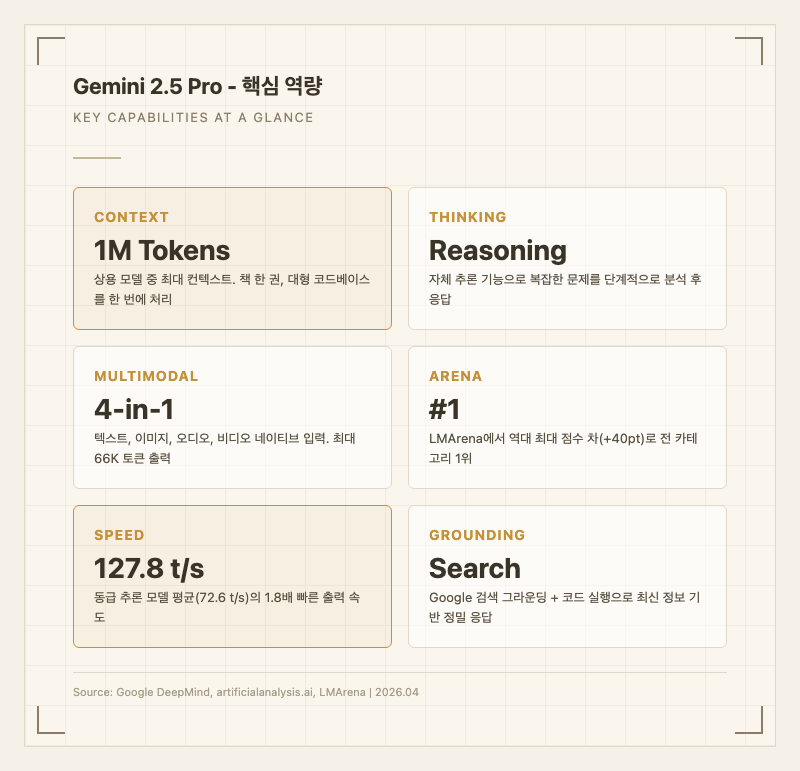
Gemini 2.5 Pro의 가장 눈에 띄는 차별점은 다음 다섯 가지다.
첫째, 1M 토큰 컨텍스트 윈도우. 상용 모델 중 최대 규모로, Claude Opus 4.6(200K)의 5배, GPT-5(128K)의 8배에 달한다. 책 한 권 전체나 대형 코드베이스를 한 번에 넣고 분석할 수 있다는 점에서 특정 워크로드에서는 압도적인 이점이 있다. 실사용자들 사이에서도 "긴 문서 분석은 Gemini가 답"이라는 평가가 자리 잡았다.
둘째, 자체 추론(thinking) 기능. 복잡한 질문에 대해 내부적으로 단계를 밟아가며 사고한 뒤 응답을 생성한다. 이 덕분에 LMArena(구 LMSYS Chatbot Arena) 리더보드에서 역대 최대 점수 차(+40pt)로 전 카테고리 1위를 달성했다. 수학, 창작 글쓰기, 지시 따르기 모두에서 1위를 기록한 유일한 모델이다.
셋째, 네이티브 멀티모달 입력. 텍스트뿐 아니라 이미지, 오디오, 비디오를 별도 전처리 없이 직접 이해한다. 특히 비디오 네이티브 이해는 경쟁 모델 대비 확실한 강점이다. Reddit 사용자들은 "이미지 분석은 Gemini가 GPT보다 훨씬 정확하다"는 평가를 자주 남긴다.
넷째, 출력 속도. artificialanalysis.ai 기준 127.8 tokens/sec로, 동급 추론 모델 평균(72.6 t/s)의 약 1.8배다. 추론 모델이면서도 체감 속도가 빠른 편이라는 점이 실사용에서 큰 장점으로 작용한다.
다섯째, Google 검색 그라운딩과 코드 실행. API에서 Google 검색을 도구로 호출해 최신 정보 기반 응답을 생성하고, 코드 실행 기능으로 계산 정밀도를 높일 수 있다.
할 수 있는 것
Gemini 2.5 Pro는 범용 모델이지만, 실사용자들이 특히 높이 평가하는 분야가 있다.
긴 문서 분석: 1M 컨텍스트를 활용해 수백 페이지짜리 논문, 법률 문서, 기술 문서를 통째로 넣고 요약-질의응답이 가능하다. 실제로 한 사용자는 "계약서 100페이지를 한 번에 넣고 특정 조항을 찾아달라고 했더니 정확히 짚어줬다"고 보고했다.
코딩 및 개발: 웹 앱 개발에서 강한 면모를 보인다. Google 공식 블로그에서도 "rich, interactive web apps" 개발 능력을 강조했으며, 사용자들은 "프론트엔드 코드 생성은 Gemini가 Claude보다 디자인 감각이 좋다"는 의견을 남긴다. 다만 복잡한 멀티파일 리팩토링에서는 Claude Opus가 더 안정적이라는 평가도 있다.
창작 글쓰기: 커뮤니티에서 "purple prose"라고 표현될 만큼 풍부한 어휘와 감정적 깊이를 가진 글을 생성한다. Reddit의 롤플레이/스토리텔링 커뮤니티에서는 Gemini 2.5 Pro가 "가장 인간적인 글을 쓰는 모델"로 꼽히기도 한다. 후속 모델 Gemini 3.0이 나온 뒤에도 창작 쪽은 2.5 Pro가 더 낫다는 의견이 많다.
과학/수학 추론: GPQA 84%, AIME 2025 86.7% 등 과학-수학 벤치마크에서 최상위권을 유지한다. 한 한국 사용자는 코딩 경험 없이 Gemini 2.5 Pro만으로 "고체 로켓의 시간별 추력 예측 코드"를 완성했다고 공유했다(출처: 한국어 커뮤니티 후기).
안 되는 것: SWE-bench Verified 63.8%로 실무 코딩 자동화에서는 Claude Opus(약 70%)에 미치지 못한다. TerminalBench Hard 26.5%로 복잡한 터미널 작업에서도 한계를 보인다. 또한 텍스트 전용 출력이라 이미지 생성은 불가하다.
성능
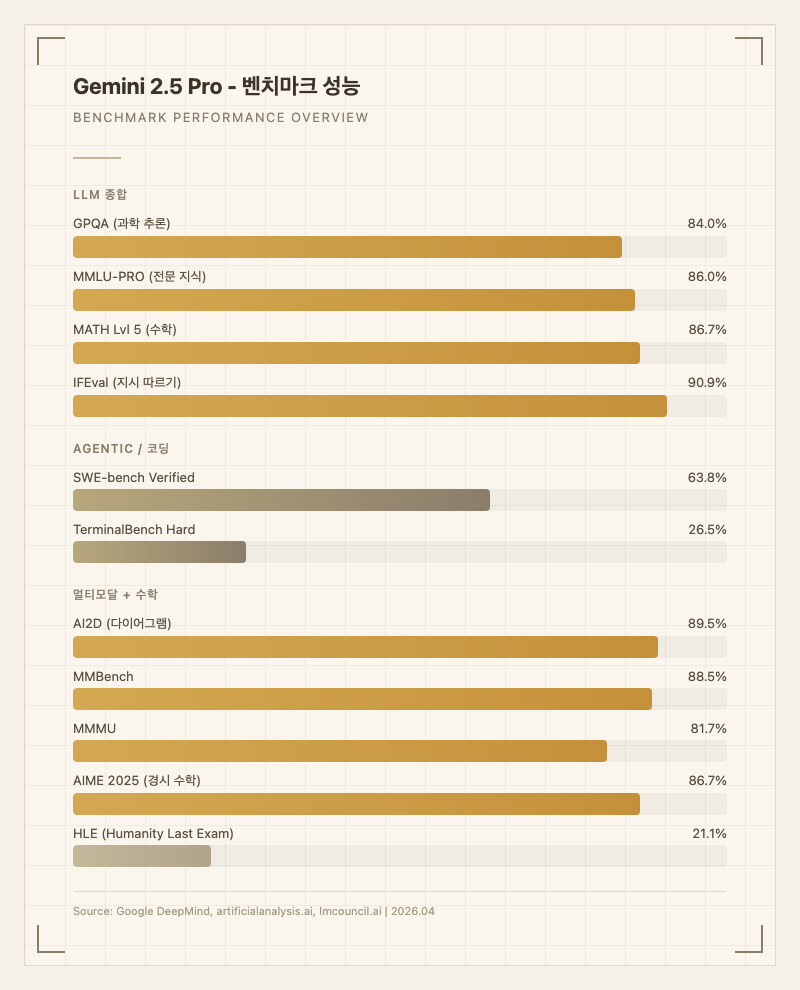
벤치마크 수치와 실사용 체감 사이에는 항상 간극이 있다. Gemini 2.5 Pro의 주요 벤치마크 결과를 정리하면 다음과 같다.
| 벤치마크 | 점수 | 분류 | 출처 |
|---|---|---|---|
| GPQA | 84.0% | 과학 추론 | 공식 블로그 |
| MMLU-PRO | 86.0% | 전문 지식 | 공식 블로그 |
| MATH Lvl 5 | 86.7% | 고급 수학 | 공식 블로그 |
| IFEval | 90.9% | 지시 따르기 | 공식 블로그 |
| SWE-bench Verified | 63.8% | 실무 코딩 | 공식 블로그 |
| TerminalBench Hard | 26.5% | 터미널 작업 | lmcouncil.ai |
| HLE | 21.1% | 최고난도 시험 | lmcouncil.ai |
| AIME 2025 | 86.7% | 경시 수학 | 공식 블로그 |
| MMMU | 81.7% | 멀티모달 이해 | 공식 블로그 |
| MMBench | 88.5% | 멀티모달 | artificialanalysis.ai |
| AI2D | 89.5% | 다이어그램 이해 | artificialanalysis.ai |
| MMStar | 73.6% | 멀티모달 | artificialanalysis.ai |
| MMVet | 83.3% | 멀티모달 | artificialanalysis.ai |
| MMLU | 89.8% | 일반 지식 | 공식 블로그 |
| Arena Elo | 1460 | 사용자 선호도 | LMArena |
실제 사용 체감은 벤치마크와 다소 다르다. 커뮤니티에서 반복적으로 나오는 평가를 정리하면:
- "상식이 GPT-5보다 좋다" - 맥락 파악과 뉘앙스 이해에서 우위
- "코딩은 Claude가 한 수 위" - 특히 복잡한 디버깅이나 대규모 리팩토링에서 Claude Opus 4.6이 더 안정적
- "긴 컨텍스트는 Gemini가 독보적" - 1M 윈도우의 실용적 가치를 체감하는 사용자가 많음
- "한국어 수능 최상위 문제에서 일부 한계" - 한국어 논리 퍼즐 성격이 강한 문제에서는 완벽하지 않다는 보고
경쟁 모델과 비교하면, 프리미엄 3사(GPT-5, Claude Opus 4.6, Gemini 2.5 Pro)의 추론 성능 차이는 대부분의 실용적 작업에서 노이즈 수준이다. 차이가 나는 영역은 코딩(Claude 우세), 멀티모달(Gemini 우세), 범용성(GPT-5 우세)이다.
사용 방법
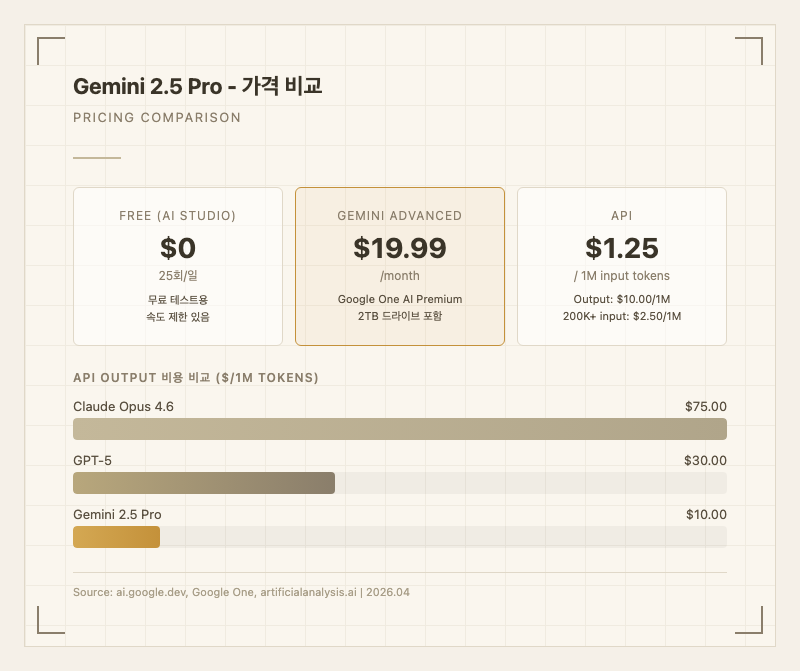
일반 사용자 (웹/앱): gemini.google.com에서 무료로 사용 가능하다. 모델 드롭다운에서 "2.5 Pro"를 선택하면 된다. 모바일 앱(iOS/Android)에서도 동일하게 이용 가능. Gemini Advanced 구독($19.99/월, Google One AI Premium)을 하면 더 높은 사용량 한도와 우선 접근이 가능하다.
개발자 (API): Google AI Studio(ai.google.dev)에서 API 키를 발급받아 사용한다. 공식 SDK는 Python, Node.js, Go, Dart 등을 지원한다. Vertex AI를 통한 엔터프라이즈 배포도 가능하며, 2025년 6월부터 GA 안정 버전으로 운영 환경에서 사용할 수 있다.
pip install google-genai
Google AI Studio에서 하루 25회까지 무료로 테스트할 수 있으며, 본격적인 프로덕션 사용시 유료 API 키로 전환하면 된다.
가격Gemini 2.5 Pro의 가격 체계는 세 단계로 나뉜다.
무료 티어: Google AI Studio에서 하루 25회 무료 요청. 속도 제한이 있지만 테스트 용도로 충분하다.
Gemini Advanced: $19.99/월 (Google One AI Premium). 2TB Google Drive 저장공간과 Workspace AI 기능이 포함된다. 일반 사용자에게는 이 플랜이 가장 실용적이다.
API 가격: 입력 2.50/1M tokens (200K 초과). 출력 $10.00/1M tokens. 프리미엄 모델 중에서는 상당히 합리적인 가격이다(출처: ai.google.dev).
경쟁 모델과 비교하면 가격 차이가 극적이다. Claude Opus 4.6의 출력 가격이 30/1M tokens인 반면 Gemini 2.5 Pro는 $10/1M tokens에 불과하다. 실사용자들 사이에서도 "성능 대비 가격은 Gemini가 압도적"이라는 평가가 지배적이다(출처: artificialanalysis.ai).
한국어 토큰 효율에 대해서는 공식 데이터가 미공개 상태다. Gemini의 SentencePiece 토크나이저(256K vocab)는 CJK 문자에 대해 약 0.82 characters/token의 효율을 보이는 것으로 추정되며, 이는 DeepSeek 토크나이저(2.02 chars/token) 대비 약 2.5배 비효율적이다(출처: apiyi.com 실측 비교). 즉, 같은 한국어 텍스트를 처리할 때 Gemini가 토큰을 더 많이 소모하므로 실질 비용이 영어 대비 높아진다.
기술 사양
| 항목 | 사양 |
|---|---|
| 개발사 | Google DeepMind |
| 모델 유형 | 멀티모달 LLM (Thinking Model) |
| 컨텍스트 윈도우 | 1,048,576 tokens (1M) |
| 최대 출력 토큰 | 65,536 tokens (66K) |
| 입력 모달리티 | 텍스트, 이미지, 오디오, 비디오 |
| 출력 모달리티 | 텍스트 |
| 출력 속도 | 127.8 tokens/sec (출처: artificialanalysis.ai) |
| 학습 데이터 기준일 | 2025년 1월 |
| GA 출시일 | 2025년 6월 17일 |
| 라이선스 | Proprietary |
| 토크나이저 | SentencePiece (256K vocab) |
| 지원 기능 | Function calling, Google 검색 그라운딩, 코드 실행 |
| 한국어 토큰 효율 | CJK ~0.82 chars/token (추정, 공식 데이터 미공개) |

참고 자료






스펙
컨텍스트 윈도우
1.0M 토큰
라이선스
Proprietary
출시일
2025년 6월 17일
학습 마감일
2025년 1월 31일
가성비 지수
0.7
API 가격 (혼합)
입력 $1.25/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$1.25 / 1M 토큰
출력 (Completion)
$10.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
90.9
복잡한 지시사항 이해 및 수행
일반지식
86.0
다양한 분야 지식 및 이해
멀티모달
83.3
이미지, 비디오 등 멀티모달 이해
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 |
|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemini 2.5 Pro | 86.1 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |