Gemini 2.5 Flash
GoogleLLM자연어 처리컴퓨터 비전오디오 처리1.0M 토큰
2025년 6월 18일Proprietary
한줄 소개
Gemini 2.5 Flash는 Google DeepMind가 개발한 가성비 추론 모델이다. Sparse Mixture-of-Experts(MoE) 트랜스포머 아키텍처 기반으로, 저렴한 가격에 사고(thinking) 기반 추론 능력을 탑재한 최초의 경량급 모델이다. 2025년 6월 프리뷰 출시 후 2026년 1월 GA(정식) 버전이 안정화되었으며, 이후에도 지속적으로 품질과 토큰 효율이 개선되고 있다.
주요 특징
Gemini 2.5 Flash의 핵심은 "조절 가능한 추론(Controllable Thinking)"이다. thinking budget 파라미터를 통해 추론 깊이를 0에서 최대까지 실시간으로 조절할 수 있어, 개발자가 품질-비용-지연 시간 사이의 트레이드오프를 직접 제어한다. 추론을 끄면 330 t/s까지 속도가 올라가고, 켜면 복잡한 수학이나 코딩 문제에서 프리미엄 모델에 근접하는 정확도를 보여준다.
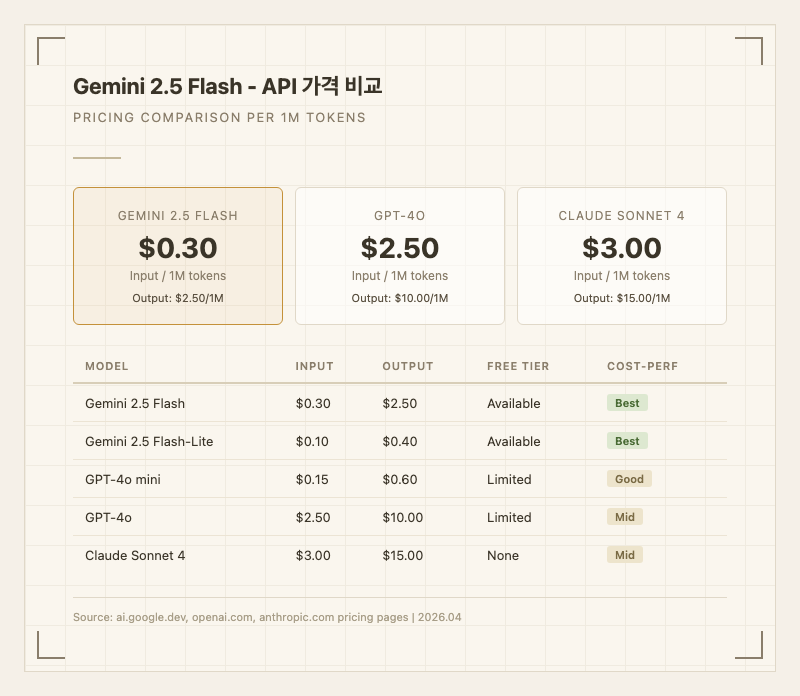
실사용자들이 가장 많이 언급하는 차별점은 가격 대비 성능이다. 입력 2.50/1M 토큰이라는 가격은 GPT-4o(10.00)나 Claude Sonnet 4(15.00) 대비 입력 기준 약 1/8~1/10 수준이다. Reddit과 Hacker News에서는 "개인 프로젝트라면 Flash 하나로 충분하다", "Pro 쓸 이유가 줄었다"는 반응이 많다.
1M(100만) 토큰 컨텍스트 윈도우와 최대 66K 토큰 출력을 지원하며, 텍스트, 이미지, 오디오, 비디오를 네이티브로 처리하는 멀티모달 모델이다. Function Calling, Web Search, Code Execution 등 네이티브 도구도 지원한다.
다만 2026년 초 업데이트에서 출력 토큰이 약 24% 줄어들면서 효율은 좋아졌지만, 일부 사용자는 응답이 중간에 끊기는 현상을 보고하고 있다. 이는 모델이 완료 신호를 잘못 보내는 P2급 버그로 GitHub에 문서화되어 있다.

할 수 있는 것
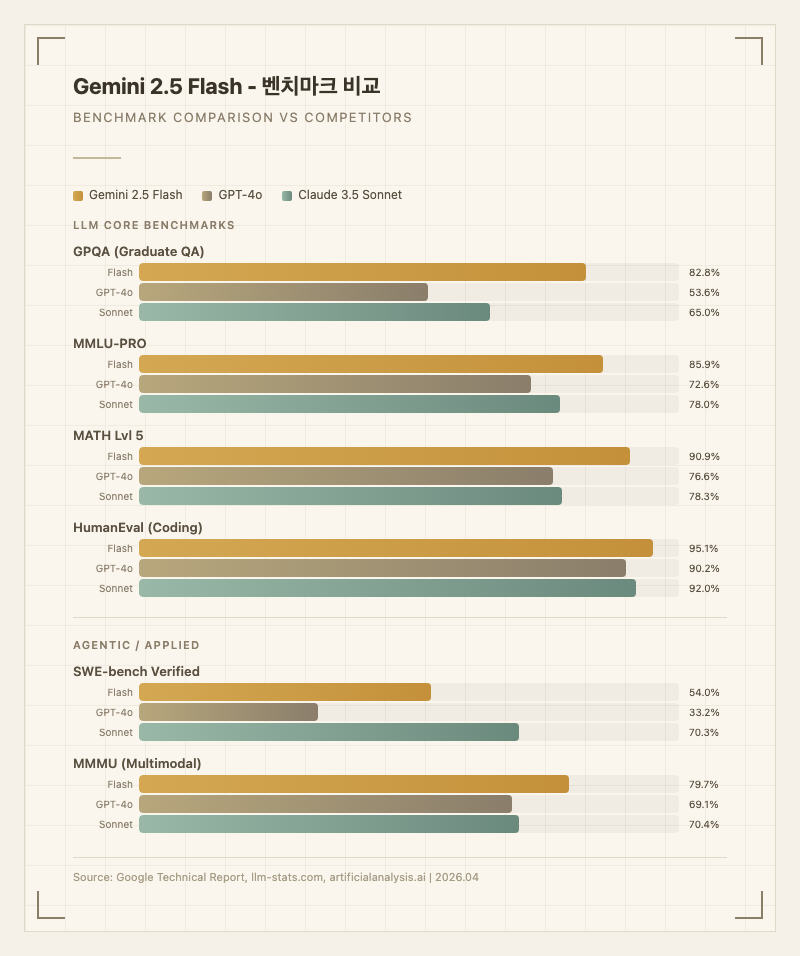
코딩 작업에서 Flash는 상당히 강력하다. HumanEval 95.1%로 대부분의 플래그십 모델을 능가하며, 실사용자들은 "이전에 작성했던 종류의 코드를 빠르게 생성하는 데는 Flash가 최적"이라고 평가한다. 다만 "디버깅처럼 깊은 이해가 필요한 작업에서는 Pro나 Claude Sonnet이 더 낫다"는 의견도 많다.
수학과 과학 추론에서도 두각을 나타낸다. MATH Lvl 5에서 90.9%, GPQA(대학원 수준 과학 QA)에서 82.8%를 기록했다. AIME 2024에서 88.0%를 달성한 것은 경량 모델로서는 이례적인 성과다.
멀티모달 활용도 실용적이다. 이미지 속 텍스트 인식, 차트 분석, 비디오 요약 등이 가능하며, MMMU 79.7%로 멀티모달 이해에서도 GPT-4o(69.1%)를 크게 앞선다. Google AI Studio의 Gemini 2.5 Flash Image 버전은 이미지 생성까지 지원한다.
1M 토큰 컨텍스트를 활용한 대규모 문서 분석에도 적합하다. 커뮤니티에서는 "긴 PDF 분석이나 코드베이스 전체를 넣고 질문하는 용도로 가장 가성비가 좋다"는 평이 많다.
반면 SWE-bench Verified 54.0%로, 실제 코드 저장소에서의 멀티스텝 에이전틱 작업에서는 Claude 3.5 Sonnet(70.3%)에 비해 확실히 뒤처진다. TerminalBench Hard 13.6%도 터미널 기반 에이전트 작업에서의 한계를 보여준다.
성능
| 벤치마크 | 점수 | 비고 |
|---|---|---|
| GPQA | 82.8% | 대학원 수준 과학 QA (출처: Google 기술 보고서) |
| MMLU-PRO | 85.9% | 전문 영역 지식 (출처: llm-stats.com) |
| MATH Lvl 5 | 90.9% | 고급 수학 추론 (출처: Google 기술 보고서) |
| IFEval | 92.0% | 지시 따르기 (출처: Google 기술 보고서) |
| HumanEval | 95.1% | 코드 생성 (출처: Google 기술 보고서) |
| SWE-bench Verified | 54.0% | 에이전틱 코딩 (출처: Google 블로그) |
| MMMU | 79.7% | 멀티모달 이해 (출처: Google 기술 보고서) |
| MMLU | 88.4% | 일반 지식 (출처: llm-stats.com) |
| AIME 2024 | 88.0% | 수학 경시 (출처: llm-stats.com) |
| AIME 2025 | 73.3% | 수학 경시 최신 (출처: llm-stats.com) |
| Arena Elo | 1412 | 사용자 선호도 (출처: lmsys.org) |
벤치마크상 Gemini 2.5 Flash는 경량 모델 중에서는 압도적이고, 다수의 지표에서 GPT-4o를 넘어선다. 특히 GPQA(+29.2%p), MMLU-PRO(+13.3%p), MATH Lvl 5(+14.3%p)에서 GPT-4o 대비 큰 격차를 보인다.
그러나 실사용 체감은 벤치마크와 다른 면이 있다. r/Bard 커뮤니티에서는 "벤치마크 점수가 높아도 실제 복잡한 멀티턴 대화에서는 Pro가 훨씬 안정적"이라는 의견이 많다. 특히 긴 대화에서 맥락을 놓치거나, 복잡한 지시를 단순화해서 따르는 경향이 있다는 지적이 있다. SWE-bench Verified 54%는 최근 업데이트로 48.9%에서 5%p 개선된 수치지만, Claude Sonnet 대비 여전히 16%p 뒤처진다.
속도 면에서는 확실한 강점이 있다. 217.9 t/s라는 출력 속도는 동급 모델 평균(89 t/s) 대비 2.4배 빠르며, Artificial Analysis 기준으로도 "well above average"라는 평가를 받고 있다.
사용 방법
일반 사용자: Gemini 앱(gemini.google.com) 또는 Google AI Studio(aistudio.google.com)에서 무료로 사용 가능하다. Gemini 앱에서는 채팅 인터페이스로 바로 이용할 수 있으며, Google Workspace(Gmail, Docs 등)에도 통합되어 있다. 무료 티어에서 Flash 모델에 접근할 수 있으나, rate limit가 있다.
개발자: Google AI Studio의 API 키를 발급받아 Gemini API로 호출하거나, Google Cloud Vertex AI를 통해 프로덕션 환경에서 사용할 수 있다. 모델명은 gemini-2.5-flash이며, GA 안정 버전은 gemini-2.5-flash-001이다. OpenRouter 등 서드파티 API 게이트웨이를 통해서도 접근 가능하다.
POST https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent
Thinking 모드를 제어하려면 요청에 thinkingConfig 파라미터를 추가하면 된다. Firebase AI Logic을 통한 모바일/웹 앱 직접 연동도 지원한다.
가격
Google AI Studio에서 무료 티어를 제공하며, rate limit 내에서 Gemini 2.5 Flash를 테스트할 수 있다. 유료 API 가격은 입력 2.50/1M 토큰이다. 더 저렴한 옵션이 필요하면 Gemini 2.5 Flash-Lite(입력 0.40/1M)를 사용할 수 있다.
경쟁 모델과 비교하면 가격 우위가 명확하다. GPT-4o는 입력 10.00/1M으로 Flash 대비 입력 8.3배, 출력 4배 비싸다. Claude Sonnet 4는 입력 15.00/1M으로 입력 10배, 출력 6배 비싸다. GPT-4o mini(0.60)가 입력 기준으로는 더 싸지만, 성능 차이를 감안하면 Flash의 가성비가 월등하다.
커뮤니티 반응을 보면 "고 처리량(high throughput) 작업에서 토큰 사용량이 20-30% 줄어들어 실질 비용이 더 낮아졌다"는 평이 있다. 반면 "추론 모드를 켜면 thinking 토큰이 별도로 과금되어 실제 비용이 표시 가격보다 높을 수 있다"는 점도 지적된다.
한국어 토큰 효율 데이터는 공식적으로 미공개 상태다. 다만 Gemini 시리즈는 한국어를 포함한 다국어를 네이티브로 지원하며, 한국어 사용자들은 "한국어 처리가 ChatGPT와 비슷하거나 약간 나은 수준"이라고 평가하고 있다.
기술 사양
| 항목 | 상세 |
|---|---|
| 개발사 | Google DeepMind |
| 아키텍처 | Sparse Mixture-of-Experts (MoE) Transformer |
| 모달리티 | 텍스트, 이미지, 오디오, 비디오 (입력) / 텍스트 (출력) |
| 컨텍스트 윈도우 | 1,048,576 토큰 (1M) |
| 최대 출력 | 65,536 토큰 (66K) |
| 학습 데이터 기준일 | 2025-01-31 |
| 출시일 | 2025-06-18 (프리뷰: 2025-03) |
| GA 안정 버전 | 2026-01-07 |
| 라이선스 | Proprietary (Google ToS) |
| 추론 모드 | Controllable thinking budget |
| 출력 속도 | 217.9 t/s (비추론: 330 t/s) |
| API 입력 가격 | $0.30 / 1M 토큰 |
| API 출력 가격 | $2.50 / 1M 토큰 |
| 네이티브 도구 | Function Calling, Web Search, Code Execution |
Sparse MoE 아키텍처는 입력 토큰마다 전체 파라미터 중 일부 전문가(experts)만 활성화하는 방식으로, 전체 모델 용량과 실제 연산/서빙 비용을 분리한다. 이 덕분에 Flash는 높은 성능을 유지하면서도 프리미엄 모델 대비 훨씬 낮은 비용과 지연 시간을 달성한다.
2025년 12월 발표된 Google DeepMind 기술 보고서(arxiv:2507.06261)에서 Gemini 2.5 시리즈의 아키텍처와 학습 방법론이 상세히 공개되었다.

참고 자료





스펙
컨텍스트 윈도우
1.0M 토큰
라이선스
Proprietary
출시일
2025년 6월 18일
학습 마감일
2025년 1월 31일
가성비 지수
3.0
API 가격 (혼합)
입력 $0.300/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.30 / 1M 토큰
출력 (Completion)
$2.50 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
92.0
복잡한 지시사항 이해 및 수행
수학/추론
86.8
수학, 과학, 논리적 추론
일반지식
85.9
다양한 분야 지식 및 이해
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1412.0 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemini 2.5 Flash | 87.8 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |