Gemma 3 27B
GoogleLLM자연어 처리컴퓨터 비전오디오 처리131K 토큰
2025년 3월 12일Gemma
Google DeepMind가 2025년 3월에 공개한 Gemma 3 27B는 27.4B 파라미터의 오픈 웨이트 멀티모달 모델이다. Gemini 2.0의 기술을 기반으로 하면서도 단일 GPU에서 실행 가능하도록 설계된, Google의 가장 야심 찬 오픈소스 프로젝트다.
주요 특징
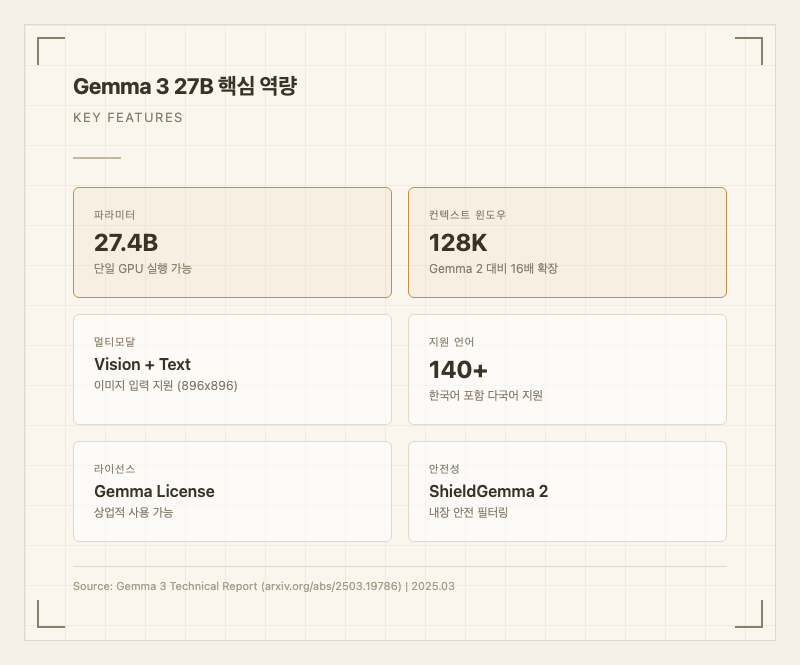
Gemma 3 27B가 전작 Gemma 2에서 가장 크게 달라진 점은 다섯 가지다.
첫째, 멀티모달 지원이 추가됐다. 텍스트만 처리하던 Gemma 2와 달리 이미지 입력을 처리할 수 있다. 896x896 해상도 이미지를 256 토큰으로 인코딩하며, 문서 분석(DocVQA 85.6), 차트 해석(ChartQA 76.3) 등에서 실용적인 성능을 보여준다.
둘째, 컨텍스트 윈도우가 8K에서 128K로 16배 확장됐다. 다만 실사용자들은 이 128K 전체를 효과적으로 활용하기 어렵다고 보고한다. Fixstars의 테스트에서는 5,200줄 C 코드를 분석할 때 마지막 250줄 정도만 제대로 처리하는 한계가 확인됐다.
셋째, 140개 이상 언어를 지원한다. Gemini 2.0의 SentencePiece 토크나이저(262K 항목)를 사용해 한국어, 중국어, 일본어 텍스트의 토큰 효율이 개선됐다. 한국어 사용자 테스트에서 삼행시, 방언 해석, 영한 번역, 격식체 변환 등이 가능한 것으로 확인됐다(출처: wikidocs.net).
넷째, 단일 GPU 실행이 가능하다. QAT(Quantization-Aware Training) 양자화를 적용하면 24GB VRAM GPU에서 구동할 수 있다. Ollama, vLLM 등으로 로컬 배포가 가능해 개인 개발자도 접근할 수 있다.
다섯째, LMSys Chatbot Arena에서 ELO 1338을 기록해 오픈 모델 중 최상위권에 올랐다. DeepSeek-V3(1318), Llama 3 405B(1257)를 상회하는 수치다(출처: 공식 블로그).
할 수 있는 것
Gemma 3 27B는 함수 수준의 작업에서 강점을 보인다. Fixstars의 실제 비즈니스 테스트에서 코드 요약과 문서 생성은 "GitHub Copilot이나 o3-mini보다 상세한 답변을 출력"한다는 평가를 받았다. 양자화 알고리즘 설명 같은 기술 문서 작성에서 경쟁 모델이 놓치는 세부 사항까지 포착했다.
멀티모달 측면에서는 문서 이미지 분석(DocVQA 85.6), 차트 읽기(ChartQA 76.3), 일반 이미지 질의(VQAv2 72.9)가 가능하다(출처: HuggingFace 모델 카드). 다만 시각적 유머 인식이나 역사적 이미지 해석처럼 맥락 이해가 필요한 비전 작업에서는 아직 부족하다는 사용자 후기가 있다.
한국어로는 창작 글쓰기(삼행시, 오행시), 텍스트 교정, 격식체/비격식체 변환, 경상도 방언 해석이 가능하다. 한국어 커뮤니티에서는 "Qwen3보다 한국어를 더 잘한다"는 평가와 함께 "소와 말을 잘 구분한다"(형태소 분리 능력)는 구체적 사례도 보고됐다(출처: arca.live).
반면 대규모 코드 리팩토링, 복잡한 환경 설정 디버깅, 의존성 해결 같은 복합 작업에서는 "지속적인 인간 개입이 필수"라는 한계가 확인됐다(출처: Fixstars). 에이전트 프레임워크(Cline)에서 소규모 코드 수정은 가능하지만, 대규모 설계 변경은 어렵다.
성능
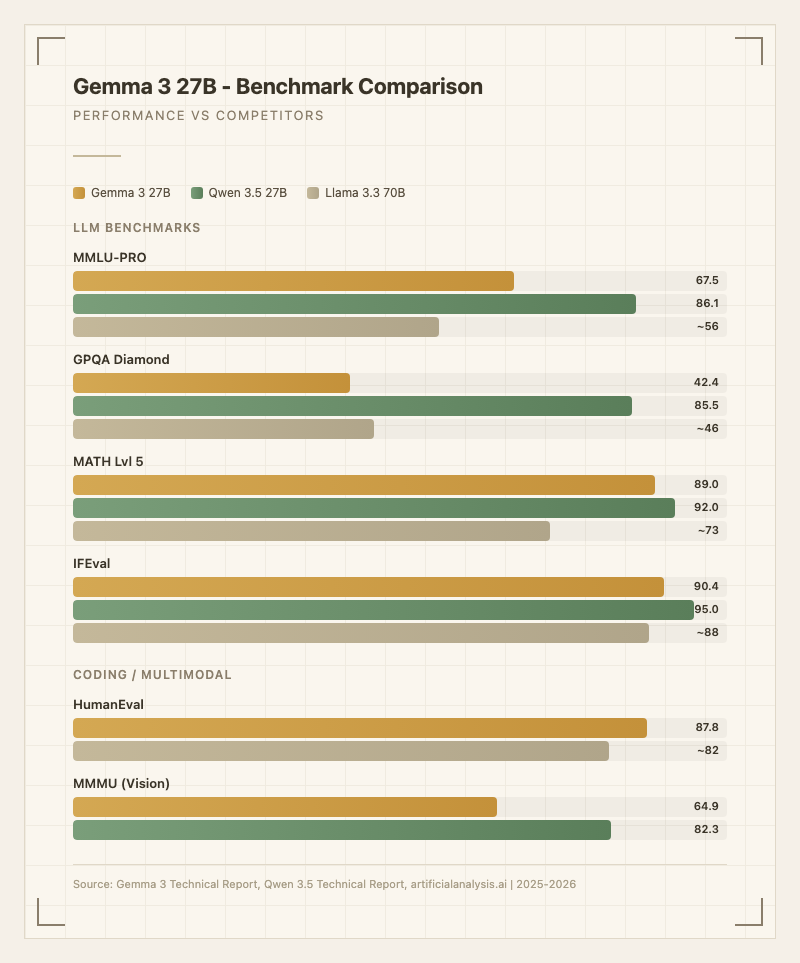
| 벤치마크 | Gemma 3 27B | Qwen 3.5 27B | 비고 |
|---|---|---|---|
| MMLU-PRO | 67.5 | 86.1 | 출처: 기술 보고서 |
| GPQA Diamond | 42.4 | 85.5 | 43점 차이 |
| MATH Lvl 5 | 89.0 | 92.0 | 근접 |
| IFEval | 90.4 | 95.0 | 지시 따르기 |
| HumanEval | 87.8 | - | 코딩 |
| MMMU | 64.9 | 82.3 | 멀티모달 |
| LiveCodeBench | 29.7 | 80.7 | 실시간 코딩 |
| GSM8K | 95.9 | - | 수학 기초 |
(출처: Gemma 3 Technical Report arxiv.org/abs/2503.19786, Qwen 3.5 Technical Report)
벤치마크 수치만 보면 Gemma 3 27B는 수학(MATH 89.0, GSM8K 95.9)과 코딩(HumanEval 87.8), 지시 따르기(IFEval 90.4)에서 강하다. 하지만 GPQA(42.4)와 LiveCodeBench(29.7)에서 드러나듯 깊은 과학적 추론과 실시간 코딩 문제 해결에는 뚜렷한 한계가 있다.
Qwen 3.5 27B와의 비교가 현실적이다. 같은 27B 크기에서 Qwen은 GPQA에서 43점, LiveCodeBench에서 51점 차이로 앞선다. 다만 Qwen은 2026년 2월 출시로 약 1년의 개발 격차가 있으므로 직접 비교에는 주의가 필요하다.
실사용자 체감으로는, 벤치마크에서 높은 점수를 받는 수학과 코딩 영역에서도 복잡한 문제로 가면 할루시네이션이 발생한다. Fixstars 테스트에서 양자화 기법을 잘못 설명하는 등 "주의 깊은 검증이 필요"하다는 결론이 나왔다. API 속도도 아쉬운 부분인데, Google API 기준 28.6 tokens/s로 동급 오픈 모델 중간값(98 t/s)의 3분의 1 수준이다(출처: artificialanalysis.ai).
사용 방법
일반 사용자는 Google AI Studio(aistudio.google.com)에서 무료로 바로 사용할 수 있다. 웹 브라우저에서 채팅 형태로 텍스트와 이미지를 입력하면 된다.
개발자는 여러 경로로 접근 가능하다. Google AI Studio API를 통해 직접 호출하거나, HuggingFace Transformers 라이브러리로 로컬 실행할 수 있다. Ollama를 이용한 로컬 배포도 간단하다. ollama run gemma3:27b 명령 한 줄로 시작할 수 있다. OpenRouter, DeepInfra, Parasail, NVIDIA NIM 등 서드파티 API 제공업체를 통해서도 사용 가능하다.
로컬 실행 시 최소 18GB RAM이 필요하며, 최적 성능을 위해서는 24GB 이상의 VRAM을 권장한다. Grouped Query Attention으로 메모리 대역폭을 40% 줄이고, RMSNorm으로 연산 속도를 높이는 최적화가 적용돼 있다.
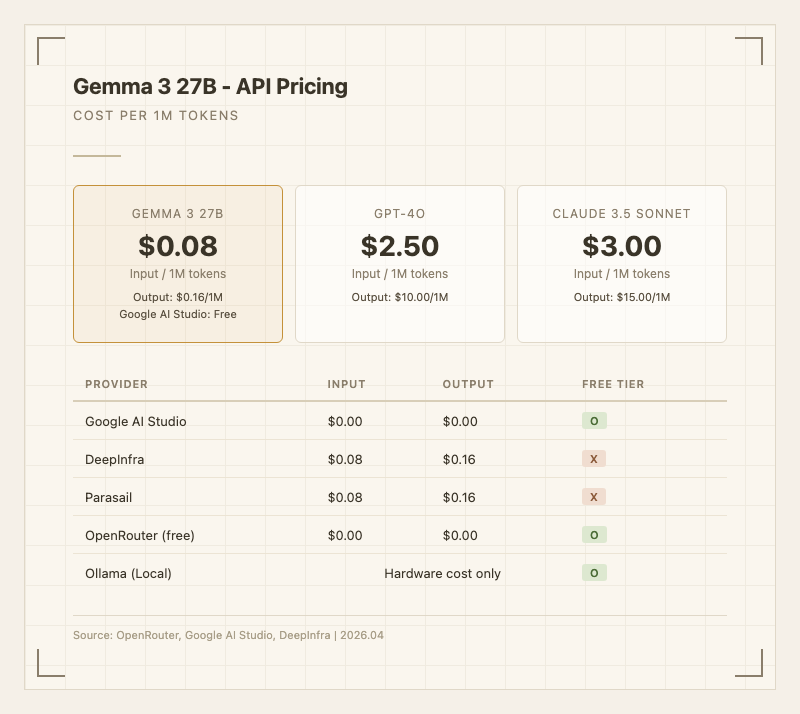
가격Gemma 3 27B의 가격 경쟁력은 압도적이다.
Google AI Studio에서는 완전 무료로 사용할 수 있다. 유료 API 기준으로도 입력 0.16/1M 토큰으로, GPT-4o(입력 10.00)의 30분의 1 수준이다. OpenRouter에서는 무료 티어도 제공된다.
다만 실사용자들 사이에서는 "싸긴 싼데 성능이 그만큼"이라는 평가가 지배적이다. Artificial Analysis의 분석에 따르면 이 모델은 "지능은 평균 이하지만 가격은 잘 책정됐다"는 포지션이다(출처: artificialanalysis.ai). 프로덕션에서 비용 최적화가 중요하고, 최고 수준의 추론 능력이 필요하지 않은 경우에 적합하다.
한국어 토큰 효율 데이터는 공식적으로 미공개다. 다만 Gemini 2.0과 동일한 SentencePiece 262K 토크나이저를 사용하며, CJK 텍스트 인코딩 효율이 이전 버전 대비 개선된 것으로 알려져 있다(출처: HuggingFace 블로그).
기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 | 27.4B |
| 아키텍처 | Dense Transformer (GQA) |
| 컨텍스트 윈도우 | 128K 입력 / 8K 출력 |
| 학습 토큰 | 14T tokens |
| 토크나이저 | SentencePiece 262K (Gemini 2.0 공유) |
| 데이터 타입 | BF16 |
| 멀티모달 | Vision + Text (896x896, 256 tokens/image) |
| 지원 언어 | 140+ |
| 학습 데이터 기준일 | 2024년 8월 |
| 라이선스 | Gemma License (상업적 사용 가능, 일부 제한) |
| 학습 하드웨어 | TPUv4p, TPUv5p, TPUv5e |
| 학습 소프트웨어 | JAX + ML Pathways |
(출처: Gemma 3 Technical Report, HuggingFace 모델 카드)

참고 자료




스펙
컨텍스트 윈도우
131K 토큰
라이선스
Gemma
출시일
2025년 3월 12일
학습 마감일
2024년 8월 31일
가성비 지수
37.5
API 가격 (혼합)
입력 $0.080/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.08 / 1M 토큰
출력 (Completion)
$0.16 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
90.4
복잡한 지시사항 이해 및 수행
코딩
87.8
코드 생성, 버그 수정, 소프트웨어 엔지니어링
멀티모달
74.7
이미지, 비디오 등 멀티모달 이해
일반지식
67.5
다양한 분야 지식 및 이해
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 69.7
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| AI2D | 84.5 | % |
| GPQA |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemma 3 27B | 69.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |