Gemma 2 9B
GoogleLLM자연어 처리컴퓨터 비전오디오 처리8K 토큰
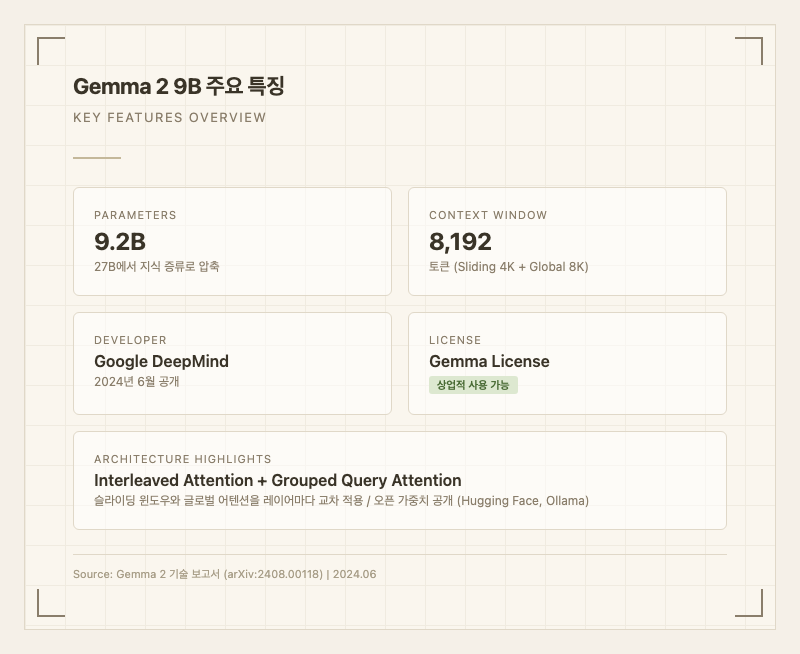
2024년 6월 28일Gemma License
한줄 소개
Gemma 2 9B는 Google DeepMind가 2024년 6월에 공개한 9.2B 파라미터 오픈소스 언어 모델이다. 더 큰 모델(27B)에서 지식 증류(Knowledge Distillation) 기법으로 핵심 추론 능력을 압축한 것이 특징으로, 출시 당시 10B 미만 모델 중 최고 성능을 기록했다. Gemma License로 상업적 사용이 가능하며, 로컬 환경에서 소비자 GPU로 구동할 수 있는 실용적인 모델이다.
주요 특징
Gemma 2 9B의 가장 큰 차별점은 지식 증류다. 27B 모델의 추론 능력을 9B 크기에 압축하면서 Gemini Pro 추론 성능의 약 92%를 유지한다(출처: localaimaster.com). 같은 파라미터 대비 Llama 3 8B나 Mistral 7B보다 벤치마크 점수가 전반적으로 높고, 특히 MMLU 71.3%는 출시 당시 동급 최고 수치였다(출처: Gemma 2 기술 보고서).
아키텍처 면에서는 Interleaved Attention이 독특하다. 슬라이딩 윈도우 어텐션(4,096 토큰)과 글로벌 어텐션(8,192 토큰)을 레이어마다 교차 적용해서, 가까운 문맥과 전체 문맥을 동시에 효율적으로 처리한다. Grouped Query Attention(GQA)도 적용되어 추론 속도가 빠르다.
실사용자들이 체감하는 차이는 시스템 프롬프트 반응성이다. Hacker News 사용자 의견에 따르면 "시스템 프롬프트로 모델 행동을 상당히 제어할 수 있다"는 평가가 있었고, 불필요한 서두("Sure, I can help you") 없이 바로 코드를 작성해주는 점도 호평을 받았다(출처: Hacker News).
한국어 지원 면에서는 동급 로컬 모델 중 가장 나은 편이다. 한국 커뮤니티에서 "체감상 GPT-3.5보다 살짝 상위호환"이라는 평가가 나왔고, 9B 크기에서 한국어를 이 정도로 하는 모델이 드물다는 반응이다(출처: DCInside 특이점이 온다 갤러리). 다만, 구체적인 질문에 영어로 답변하는 경우가 간혹 있다는 지적도 있었다(출처: 아카라이브).
할 수 있는 것
Gemma 2 9B는 텍스트 전용 LLM으로, 대화, 코드 생성, 요약, 질의응답, 콘텐츠 작성 등 범용 텍스트 작업에 적합하다.
실사용자들이 실제로 해본 것을 보면, 코드 생성에서 꽤 쓸 만하다는 평가가 많다. 코드 요청 시 군더더기 없이 바로 코드를 작성하고 그 뒤에 설명을 붙이는 방식이 개발자들에게 호평받았다. 다만 "프로그래밍 태스크에서는 꽤 별로"라는 반대 의견도 있어서, 복잡한 멀티파일 프로젝트보다는 단일 함수나 스크립트 수준의 코드 생성에 강하다고 보는 것이 정확하다(출처: Hacker News).
다국어 작업에서도 활용 가능하다. 27B 모델이 "여러 비주류 언어에서 거의 완벽"하다면, 9B는 "완벽하지는 않지만 쓸 수 있는 수준"이라는 평가다(출처: Hacker News). 한국어로 통화 요약 서비스를 파인튜닝해서 실제 프로덕션에 배포한 사례도 있다 - 리턴제로가 Gemma 2 기반으로 고품질 통화 요약 서비스를 개발했다(출처: Google Developers Korea Blog).
반면, 할 수 없는 것도 명확하다. 8K 토큰 컨텍스트 윈도우는 "금붕어 수준의 기억력"이라는 혹평을 받았고(출처: Hacker News), 컨텍스트가 포화 상태에 가까워지면 "완전히 엉뚱한 방향으로 간다"는 보고가 있다. 긴 문서 분석이나 복잡한 멀티턴 대화에는 부적합하다. 이미지, 오디오 등 멀티모달 입력은 지원하지 않는다.
성능
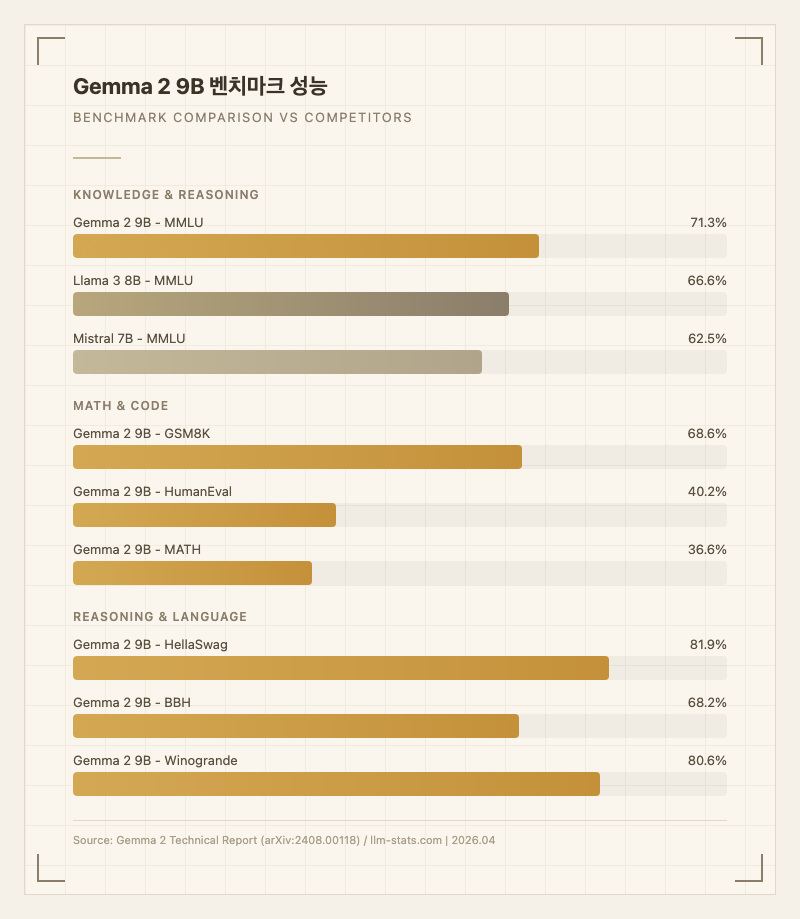
벤치마크 수치를 보면, Gemma 2 9B는 출시 당시 10B 미만 모델의 새 기준을 세웠다.
| 벤치마크 | Gemma 2 9B | Llama 3 8B | Mistral 7B |
|---|---|---|---|
| MMLU (5-shot) | 71.3% | 66.6% | 62.5% |
| GSM8K (5-shot) | 68.6% | - | - |
| HumanEval (pass@1) | 40.2% | - | - |
| MATH (4-shot) | 36.6% | - | - |
| BBH (3-shot, CoT) | 68.2% | - | - |
| HellaSwag (10-shot) | 81.9% | - | - |
| Winogrande (5-shot) | 80.6% | - | - |
| ARC-C (25-shot) | 68.4% | - | - |
| GPQA | 28.8% | - | - |
| MMLU-PRO | 38.8% | - | - |
| IFEval | 88.4% | - | - |
(출처: Gemma 2 기술 보고서 arXiv:2408.00118, llm-stats.com)
MMLU 71.3%는 동급에서 압도적이고, IFEval 88.4%는 지시사항 따르기 능력이 뛰어남을 보여준다. GPQA 28.8%와 MATH 36.6%는 대학원 수준 추론과 고급 수학에서는 한계가 있음을 의미한다.
실사용 체감은 벤치마크와 약간 다르다. LMSys Chatbot Arena에서 Arena Elo 1265를 기록했는데, 이는 Llama 3 70B보다 높고 GPT-4/Claude 3 Sonnet에 근접한 수준이다(출처: Hacker News). 크기 대비 실사용 만족도가 벤치마크 이상이라는 뜻이다. 다만 이에 대해 "Arena 프롬프트에 맞춰 RLHF 학습을 한 것 아니냐"는 의심도 있었다.
속도 면에서는 Q4_K_M 양자화 기준 약 52 tok/s로, Llama 3.1 8B보다 1.16배 빠르다(출처: localaimaster.com). 모바일 CPU에서도 Gemma 1 대비 25% 빠른 추론이 가능하다.
단점도 분명하다. 컨텍스트가 길어질수록 성능이 급격히 하락하며, 코드 생성에서 반복적으로 같은 설명을 늘어놓는 현상이 보고되었다. 일부 사용자는 "Llama 3 8B가 추론 일부 테스트에서 Gemma 2 27B보다 나았다"고 보고하기도 했다(출처: Hacker News).
사용 방법
Gemma 2 9B는 오픈소스 모델이므로 여러 경로로 사용할 수 있다.
로컬 실행 (일반 사용자)
가장 간단한 방법은 Ollama다. 설치 후 터미널에서 ollama run gemma2:9b 명령어 한 줄로 바로 실행 가능하다. RTX 3060 12GB 또는 Mac M1 16GB 이상이면 원활하게 구동된다. Q4_K_M 양자화 기준 VRAM 5.7GB만 필요하므로, 8GB VRAM GPU에서도 돌릴 수 있다.
최적화 팁으로, 환경변수 OLLAMA_FLASH_ATTENTION=1을 설정하면 어텐션 연산이 빨라지고, OLLAMA_NUM_PARALLEL을 CPU 코어 수에 맞게 조정하면 추가 성능 향상이 가능하다.
API 사용 (개발자) Google AI Studio에서 무료로 사용 가능하며, Vertex AI를 통해 프로덕션 API로도 제공된다. 또한 OpenRouter, DeepInfra, Groq, NVIDIA NIM 등 다양한 서드파티 추론 서비스에서 API를 제공한다.
파인튜닝
Hugging Face에 모델 가중치가 공개되어 있어(google/gemma-2-9b-it), LoRA 등의 방식으로 도메인 특화 파인튜닝이 가능하다. 한국어 도메인 파인튜닝 사례는 SK DevOcean 블로그와 올리브영 테크블로그에서 확인할 수 있다.
가격Gemma 2 9B의 가장 큰 장점 중 하나는 가격이다.
API 가격 (OpenRouter 기준)
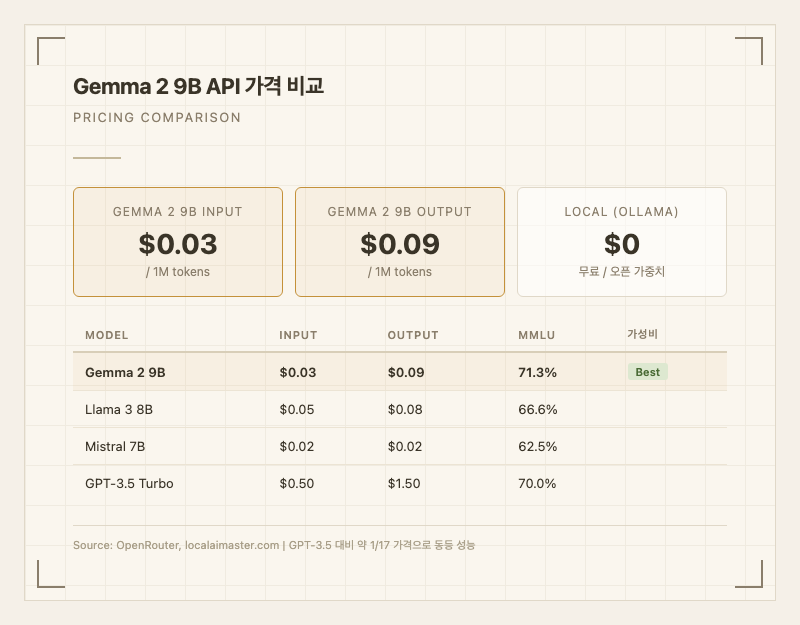
- 입력: $0.03 / 1M 토큰
- 출력: $0.09 / 1M 토큰
이 가격은 GPT-3.5 Turbo(입력 1.50/1M)의 약 1/17 수준이다. MMLU 성능은 GPT-3.5와 거의 동등(71.3% vs 70%)하니, 가성비가 압도적이다.
로컬 실행 시 무료 Ollama, vLLM, llama.cpp 등으로 로컬 실행하면 API 비용이 아예 없다. localaimaster.com 추산에 따르면, 백만 사용자 규모 서비스 기준으로 월 약 $4,200의 API 비용을 절감할 수 있다.
한국어 토큰 효율 Gemma 2의 토크나이저는 한국어에 최적화되어 있지 않다. 후속 모델인 Gemma 3에서 중국어/일본어/한국어 텍스트 인코딩이 크게 개선되었다는 점에서, Gemma 2의 한국어 토큰 효율은 영어 대비 불리할 수 있다(출처: Hugging Face Gemma 3 블로그). 구체적인 한국어 토큰 효율 수치는 미공개다.
경쟁 모델과 비교하면, Mistral 7B가 입력 0.02로 더 저렴하지만 MMLU가 62.5%로 낮고, Llama 3 8B는 입력 0.08으로 약간 비싸면서 MMLU도 66.6%로 낮다. 성능 대비 가격에서 Gemma 2 9B가 가장 균형 잡힌 선택이다.
기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 | 9.2B |
| 컨텍스트 윈도우 | 8,192 토큰 |
| 어텐션 메커니즘 | Grouped Query Attention + Interleaved (Sliding Window 4K / Global 8K) |
| 학습 데이터 | 8조 토큰 (웹, 코드, 수학) |
| 학습 방법 | 지식 증류 (27B -> 9B) |
| Logit Soft-capping | 적용 |
| 출시일 | 2024년 6월 27일 |
| 라이선스 | Gemma License (상업적 사용 가능) |
| VRAM (FP16) | 약 20GB |
| VRAM (Q4_K_M) | 약 5.7GB |
| 추론 속도 | 약 52 tok/s (Q4_K_M 기준) |
| 최소 하드웨어 | 12GB RAM, 8GB 스토리지, 6+ CPU 코어 |
| 지원 프레임워크 | Ollama, vLLM, TGI, llama.cpp, Hugging Face Transformers |
(출처: Gemma 2 기술 보고서 arXiv:2408.00118, localaimaster.com, apxml.com)
후속 모델로 Gemma 3 시리즈(1B/4B/12B/27B)가 2025년에 출시되었고, 2026년에는 Gemma 4가 공개되었다. 새 프로젝트에는 Gemma 3 이상을 권장하지만, 파인튜닝 자산이 Gemma 2 생태계에 묶여 있거나 이미 검증된 파이프라인이 있다면 Gemma 2 9B도 여전히 유효한 선택이다.

참고 자료






스펙
컨텍스트 윈도우
8K 토큰
라이선스
Gemma License
출시일
2024년 6월 28일
학습 마감일
2024년 6월 30일
가성비 지수
47.0
API 가격 (혼합)
입력 $0.030/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.03 / 1M 토큰
출력 (Completion)
$0.09 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
88.4
복잡한 지시사항 이해 및 수행
코딩
40.2
코드 생성, 버그 수정, 소프트웨어 엔지니어링
수학/추론
39.1
수학, 과학, 논리적 추론
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 43.5
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1265.0 | elo |
| BBH |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemma 2 9B | 43.5 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |