Gemma 4
GoogleLMM시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)262K 토큰
2026년 4월 2일Apache 2.0
Google DeepMind이 2026년 4월 2일 공개한 오픈 웨이트 멀티모달 AI 모델 패밀리. Gemini 3 연구를 기반으로 구축되었으며, Apache 2.0 라이선스로 배포되어 상업적 활용이 완전히 자유롭다. E2B(2.3B), E4B(4.5B), 26B A4B(MoE), 31B Dense 4가지 크기로 제공되며, "파라미터당 최고 지능"을 표방한다. 출시 이틀 만에 Hacker News 1,700+ 포인트, Hugging Face 80K+ 다운로드를 기록하며 오픈 모델 역사상 가장 뜨거운 반응을 이끌어냈다.
주요 특징
Apache 2.0 완전 자유 라이선스 - Gemma 4의 가장 큰 변화는 라이선스다. 이전 Gemma 시리즈의 제한적 라이선스에서 Apache 2.0으로 전환하여 MAU 제한, 사용 정책 등 어떤 제약도 없다. Llama 4의 700M MAU 제한, Qwen의 사용 정책과 비교하면 확실한 차별점이다. 한 커뮤니티 사용자의 평가: "구글이 결국 판을 바꿨다. 이제 기업들도 데이터 외부 유출 걱정 없이 자체 AI를 직접 구축할 수 있게 됐다." (출처: Threads @choi.openai)
네이티브 멀티모달 - 텍스트, 이미지, 비디오, 오디오를 통합 처리한다. 오픈 모델 중 이 네 가지를 모두 네이티브로 지원하는 것은 Gemma 4가 유일하다. GUI 요소 감지, 오브젝트 검출, 비디오 이해, 오디오 전사 및 Q&A까지 가능. (출처: 공식 블로그)
Codeforces Elo 2150 - Gemma 3의 110에서 2150으로, 역대 오픈 모델 세대 간 최대 도약. 코딩 능력이 근본적으로 달라졌다. (출처: Google model card)
Arena Elo 1452 (31B) - 31B Dense가 Arena AI 텍스트 리더보드 오픈 모델 3위. 26B MoE도 1441로 6위. 4B 활성 파라미터로 1441을 달성한 것은 효율성 측면에서 놀라운 수치다. (출처: lmarena.ai)
온디바이스 실행 - E2B/E4B는 Android AICore에서 직접 실행 가능. NVIDIA Jetson부터 RTX GPU, AMD ROCm, Google TPU까지 폭넓은 하드웨어 지원. Django 공동 창시자 Simon Willison은 "노트북에서 돌아가는 모델 중 최고의 결과물을 뽑아냈다"고 평가. (출처: Hacker News)

할 수 있는 것
로컬 AI 에이전트 구축
네이티브 함수 호출(Function Calling)과 구조화된 JSON 출력을 지원하여, 외부 API 없이 로컬에서 멀티스텝 에이전트 워크플로우를 구축할 수 있다. 26B MoE 모델은 3.8B 활성 파라미터로 빠르게 동작하면서도 높은 품질을 유지한다. 실사용자 평가: "6개월 전에 40GB VRAM이 필요했던 수준의 추론 능력을 이제 노트북에서 실행할 수 있다." (출처: Reddit)
다만 초기 버전에서 26B MoE가 프롬프트 규칙을 무시하고 도구를 할루시네이션하는 문제가 보고되었다. Hacker News 사용자: "도구를 안 쓰는 게 할루시네이션하며 쓰는 것보다 낫다." Ollama, vLLM 등 서드파티 구현체의 토크나이저/양자화 호환 문제도 출시 직후 발견되었으므로, 프로덕션 도입 전 충분한 테스트가 필요하다. (출처: Hacker News)
코딩 어시스턴트
LiveCodeBench v6 80.0%, Codeforces Elo 2150으로 오픈 모델 중 최고 수준의 코딩 능력. Python, JavaScript 생성 속도가 20% 향상되었으며, 이미지/스크린샷 기반 코드 자동 생성도 가능. 140개 이상 프로그래밍 언어를 지원한다. 4090에서 150 tok/s로 Qwen 3.5 대비 50% 빠른 출력 속도를 보여준다. (출처: Google model card, Reddit)
멀티모달 분석
비디오 이해, 오디오 전사, 이미지 OCR, 차트 분석을 하나의 모델에서 처리. 회의 녹음 분석, 제품 이미지 분류, 문서 디지털화 등에 활용 가능. MMMU Pro 76.9%로 비전 추론에서도 오픈 모델 최고 수준. 단, 오디오 입력은 소형 E2B/E4B 모델에서만 지원되며 26B/31B에서는 불가하다. (출처: Google model card)
온디바이스/프라이버시 중심 AI
데이터를 외부로 전송하지 않고 기기 내에서 처리. 의료, 금융, 법률 등 데이터 보안이 중요한 분야에서 핵심적. E2B/E4B는 Android 기기에서 오프라인 실행하며 배터리 60% 절감. NVIDIA도 "RTX에서 Gemma 4로 로컬 에이전트 AI를 구현하라"며 적극적으로 지원하고 있다. (출처: NVIDIA 블로그, Android Developers Blog)
안 되는 것
- 중국 오픈 모델 대비 일부 영역 열세: Qwen 3.5는 MMLU-PRO(86.1% vs 85.2%), GPQA(85.5% vs 84.3%)에서 근소하게 앞서고, CJK 언어(일본어 87.8% vs 76.2%)와 대규모 모델(397B)에서 확실한 우위. (출처: ai.rs)
- 26B MoE의 장문 컨텍스트 약점: 128K 이상 장문 컨텍스트 처리에서 31B Dense(66.4%) 대비 크게 낮은 44.1%를 기록. 긴 문서 작업에는 31B Dense를 사용해야 한다. (출처: Google model card)
- 26B MoE 속도 이슈: 일부 하드웨어에서 MoE 모델이 예상보다 느리다는 보고. "Gemma 4 26B-A4B에서 11 tok/s인데 같은 하드웨어에서 Qwen 3.5 35B-A3B는 60+ tok/s" (출처: Hacker News)
- Extended thinking은 31B 모델에서만 활성화된다.
- Lazy 출력 경향: 일부 사용자가 "Gemma 4 is Quite Lazy"라며 응답 길이가 짧거나 세부 사항을 생략하는 경향을 지적했다. (출처: Reddit)
성능
벤치마크 결과 (31B Dense 기준)
| 벤치마크 | 점수 | 카테고리 |
|---|---|---|
| MMLU-PRO | 85.2% | 지식 (출처: Google model card) |
| GPQA Diamond | 84.3% | 추론 (출처: Google model card) |
| AIME 2026 | 89.2% | 수학 (출처: Google model card) |
| HumanEval | 94.1% | 코딩 (출처: Google model card) |
| LiveCodeBench v6 | 80.0% | 코딩 (출처: Google model card) |
| tau-bench (avg) | 76.9% | 에이전트 (출처: Google model card) |
| MMMU Pro (Vision) | 76.9% | 멀티모달 (출처: Google model card) |
| HLE (no tools) | 19.5% | 추론 (출처: Google model card) |
| GSM8K | 96.2% | 수학 (출처: Google model card) |
| MRCR v2 (128K) | 66.4% | 장문 컨텍스트 (출처: Google model card) |
| MMLU | 88.4% | 지식 (출처: Google model card) |
| Codeforces Elo | 2150 | 코딩 (출처: Google model card) |
| Arena Elo | 1452 | 사용자 선호도 (출처: lmarena.ai) |
벤치마크는 이런데 실제로는
코딩 능력 도약은 실제로 체감된다. Codeforces Elo가 110에서 2150으로 뛴 것은 과장이 아니다. Reddit 사용자들도 "역대 최고 오픈소스 모델"이라는 평가를 내놓고 있다. 속도와 프라이버시를 중시하는 개발자들에게 특히 인기가 높다.
31B vs 프론티어 모델 격차는 존재한다. MMLU-PRO 85.2%는 Gemini 3.1 Pro의 90.5%와 비교하면 선방이지만, SWE-bench Verified 같은 에이전트 코딩에서는 프론티어 모델(80%+)과 상당한 격차가 있다. Artificial Analysis Intelligence Index에서 31B(Reasoning)는 39점으로, 프론티어 모델들(60+)과는 확실한 차이를 보인다. (출처: artificialanalysis.ai)
커뮤니티에서 Qwen 3.5와 비교가 활발하다. ai.rs 비교에 따르면, 소형~중형 모델에서는 Gemma 4가 리드하지만, 대규모 모델과 CJK 언어 성능에서는 Qwen 3.5가 앞선다. 독일어, 아랍어, 베트남어, 프랑스어 등 비영어 유럽/동남아 언어에서는 Gemma 4가 "다른 차원"이라는 평가를 받고 있다. (출처: ai.rs, Hacker News)
E2B 모델의 성능이 놀랍다. 2.3B 파라미터 모델이 Gemma 3 27B의 대부분 벤치마크를 이긴다. 이 점은 여러 커뮤니티에서 반복적으로 언급되는 핵심 포인트다. (출처: latent.space, DEV Community)
한국어는 오픈 모델 중 최고 수준이다. "상업적 이용이 가능한 로컬 모델 중에서 가장 한국어를 잘 이해한다"는 평가가 있다. 한국어 토큰 효율 관련 구체적 수치는 미공개이나, Gemma 3부터 도입된 새 토크나이저가 CJK 텍스트 인코딩 효율을 크게 개선했다는 점이 공식적으로 확인된다. 다만 일본어 벤치마크(76.2%)에서 Qwen 3.5(87.8%)에 뒤지는 만큼, 한국어에서도 유사한 격차가 있을 가능성은 있다. (출처: Hugging Face 블로그, ai.rs)
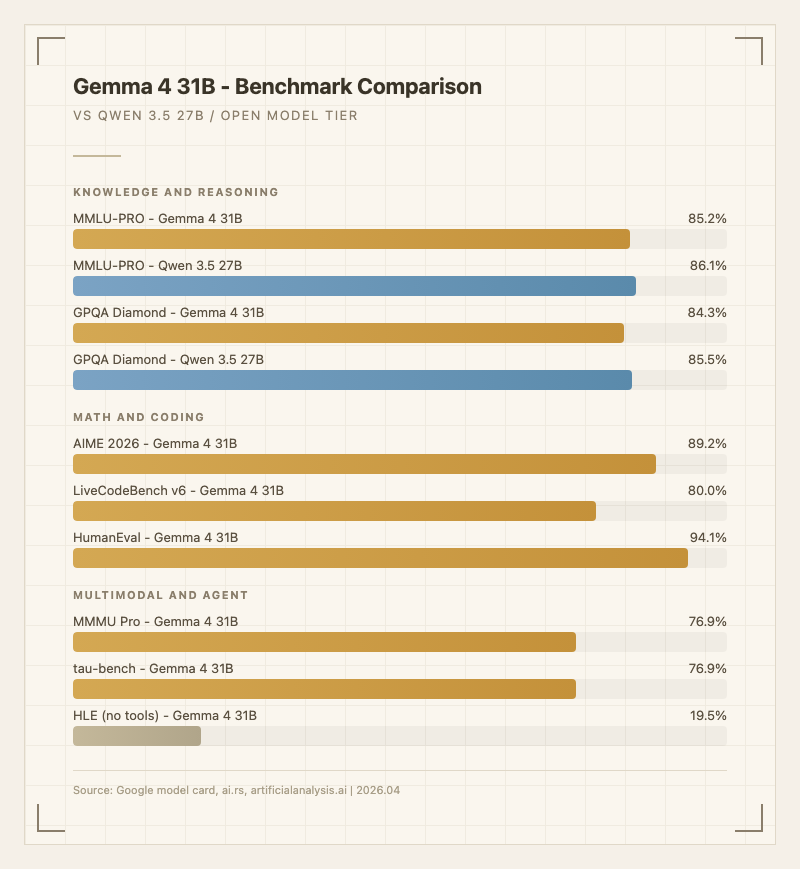
경쟁 모델 비교
vs Qwen 3.5: MMLU-PRO(85.2% vs 86.1%), GPQA(84.3% vs 85.5%)에서 Qwen이 근소하게 앞서지만, AIME 2026(89.2%)과 코딩에서 Gemma 4가 우세. Qwen은 CJK 언어(87.8% vs 76.2% 일본어)와 397B 대규모 모델에서 확실한 우위. 멀티모달과 Apache 2.0 라이선스는 Gemma 4의 강점. (출처: ai.rs, maniac.ai)
vs Llama 4 Scout: 벤치마크 대부분에서 Gemma 4가 앞서지만, Llama 4의 10M 토큰 컨텍스트는 다른 오픈 모델이 따라올 수 없는 킬러 피처. 전체 코드베이스나 초장문 문서 처리가 필요하면 Llama 4. 라이선스는 Llama 4(700M MAU 제한)보다 Gemma 4(Apache 2.0)가 확실히 유리. (출처: lushbinary.com)
vs 프론티어 모델 (Opus 4.6, GPT-5.4, Gemini 3.1 Pro): 벤치마크 격차는 있지만 비용이 0원(셀프호스팅)이라는 점에서 차원이 다른 가치. 데이터 프라이버시, 커스텀 파인튜닝, 오프라인 환경에서는 프론티어 모델이 대체할 수 없다.
상황별 선택: 코딩 어시스턴트/에이전트(로컬) -> Gemma 4 26B MoE, 초장문 컨텍스트 -> Llama 4 Scout, 다국어/CJK -> Qwen 3.5, 최대 품질(비용 무관) -> Gemini 3.1 Pro / Opus 4.6.
사용 방법
로컬 실행
Ollama, LM Studio, vLLM 등에서 즉시 실행 가능. Hugging Face에서 가중치를 다운로드하여 사용한다. 출시 직후 서드파티 구현체에서 토크나이저/양자화 호환 문제가 발견되었으므로, 반드시 최신 버전을 사용해야 한다. (출처: Hacker News)
bash
# Ollama
ollama run gemma4:31b
# LM Studio
# GUI에서 gemma-4-31b 검색 후 다운로드
API
Google AI Studio에서 무료(rate-limited) 사용 가능. OpenRouter, Together AI, Lightning AI 등 서드파티에서도 저렴하게 제공한다. Android AICore Developer Preview를 통해 온디바이스 배포도 가능. (출처: ai.google.dev)
python
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemma-4-31b-it",
contents="..."
)
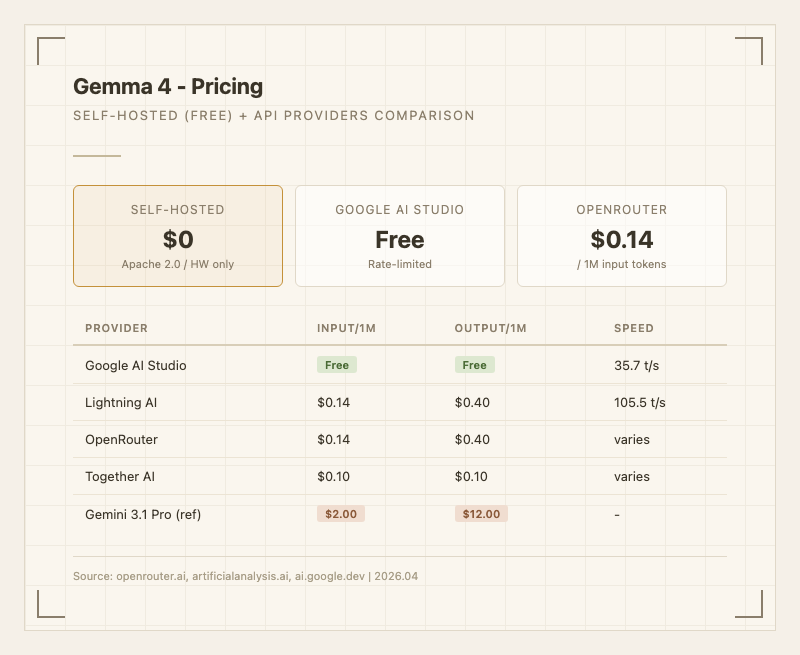
가격
셀프 호스팅완전 무료(Apache 2.0). 하드웨어 비용만 필요.
| 모델 | 파라미터 | 활성 파라미터 | 최소 VRAM | 컨텍스트 |
|---|---|---|---|---|
| E2B | 2.3B | 2.3B | ~3 GB | 128K |
| E4B | 4.5B | 4.5B | ~6 GB | 128K |
| 26B A4B (MoE) | 26B | 3.8B | ~18 GB | 256K |
| 31B Dense | 31B | 31B | ~22 GB | 256K |
API 가격
| Provider | Input | Output | Speed |
|---|---|---|---|
| Google AI Studio | 무료 (rate-limited) | 무료 | 35.7 t/s |
| Lightning AI | $0.14/1M | $0.40/1M | 105.5 t/s |
| OpenRouter | $0.14/1M | $0.40/1M | varies |
| Together AI | $0.10/1M | $0.10/1M | varies |
(출처: openrouter.ai, artificialanalysis.ai)
가성비 평가
오픈 모델이므로 셀프 호스팅 시 비용은 순수 하드웨어 비용뿐이다. 프론티어 모델과 비교하면 차원이 다른 경제성. "31B 모델이 GPT-4o 수준의 성능을 22GB VRAM으로 로컬에서 돌릴 수 있다"는 것이 핵심 가치. API 사용 시에도 OpenRouter 기준 0.40으로 Gemini 3.1 Pro(12)의 1/14~1/30 수준이다. Together AI는 0.10으로 더 저렴하다. 단, 프론티어 모델 대비 품질 격차가 있으므로 "공짜라서 좋은 것"과 "실제로 프로덕션에 쓸 수 있는 것"은 구분해야 한다. Lightning AI에서 105.5 t/s의 빠른 속도를 제공한다는 점도 API 사용자에게 매력적이다. (출처: artificialanalysis.ai)
한국어 토큰 효율 데이터 미공개. Gemma 3부터 도입된 새 토크나이저가 CJK 텍스트 인코딩 효율을 개선했으나, 영어/코드 대비 약간의 토큰 수 증가가 있다. (출처: Hugging Face 블로그)
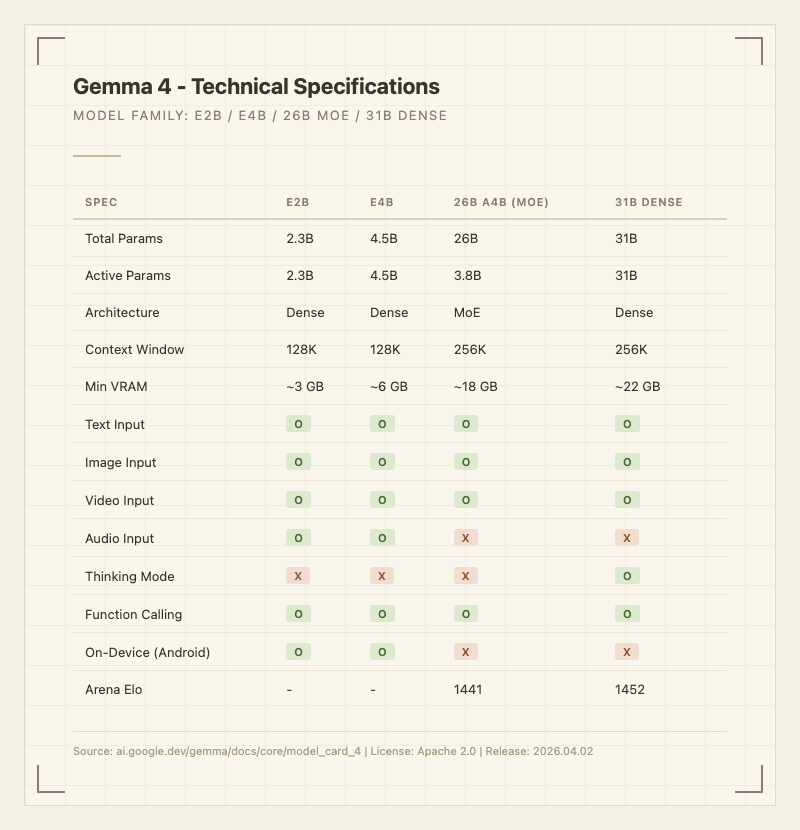
기술 사양
| 항목 | 사양 |
|---|---|
| Provider | Google DeepMind |
| Base Research | Gemini 3 |
| Architecture | Dense (31B, E2B, E4B) + MoE (26B A4B) |
| Modality | Text + Image + Video + Audio (입력), Text (출력) |
| Context Window | 128K (E2B/E4B), 256K (26B/31B) |
| Parameters | 2.3B / 4.5B / 26B(3.8B active) / 31B |
| Max Output | 131,072 tokens (31B) |
| License | Apache 2.0 |
| Release Date | 2026년 4월 2일 |
| Languages | 140+ |
| Features | Function Calling, Structured JSON, System Instructions |
| Thinking Mode | 31B only |
| Downloads | 400M+ (Gemma 시리즈 누적) |
| Variants | 100,000+ (Gemmaverse) |
(출처: ai.google.dev/gemma/docs/core/model_card_4)
참고 자료






스펙
컨텍스트 윈도우
262K 토큰
라이선스
Apache 2.0
출시일
2026년 4월 2일
가성비 지수
-0.0
API 가격 (혼합)
입력 $140000/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.14 / 1M 토큰
출력 (Completion)
$0.40 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
코딩최강
94.1
코드 생성, 버그 수정, 소프트웨어 엔지니어링
일반지식
85.2
다양한 분야 지식 및 이해
멀티모달
76.9
이미지, 비디오 등 멀티모달 이해
Provider
분류
시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)Multimodal TransformerLMM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| AIME 2026 | 89.2 | % |
| Arena Elo |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemma 4 | 86.2 |
| Nova Pro 1.0 | 68.4 |
| Claude 3 Haiku | 46.5 |
| Nova Premier 1.0 | 73.2 |
| GPT-4o-mini | 62.6 |