Gemini 3 Pro Preview
GoogleLLM자연어 처리컴퓨터 비전오디오 처리1.0M 토큰
2025년 11월 20일Proprietary
Google DeepMind가 2025년 11월 공개한 Gemini 3 세대 첫 프론티어 모델. Gemini 2.5 Pro의 후속으로, 추론, 코딩, 멀티모달 전 영역에서 대폭 향상되었다. 2026년 3월 9일부로 deprecated되어 Gemini 3.1 Pro Preview로 대체되었지만, AI 모델 시장의 기준을 바꾼 모델로 평가받는다.
주요 특징
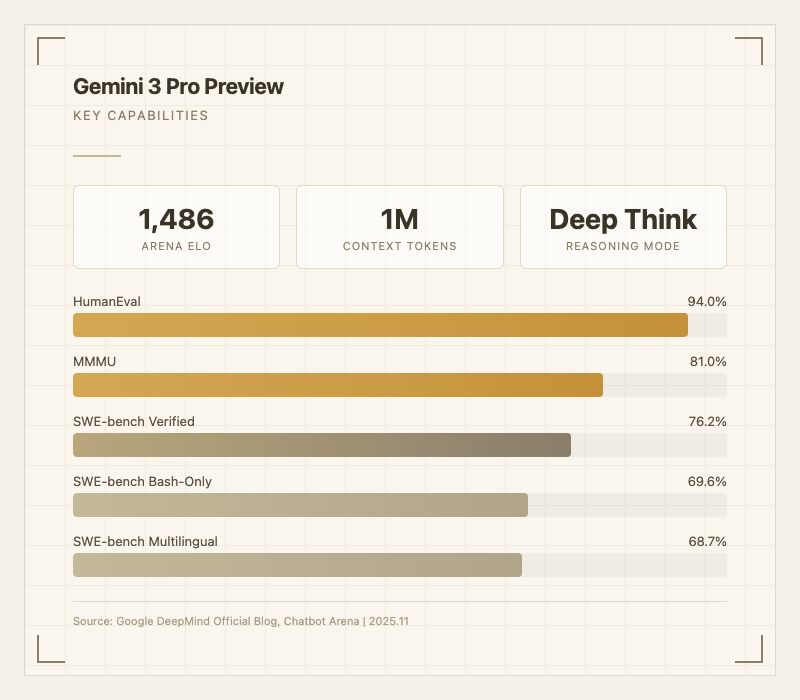
Chatbot Arena 역대급 Elo - Arena Elo 1486으로 출시 당시 전체 1위를 기록했다. Claude Opus 4.5(1490)에 근접하는 사용자 선호도로, "드디어 Google이 체감 품질에서도 경쟁력을 갖추게 됐다"는 반응이 쏟아졌다. 실제로 ChatGPT Plus에서 갈아타는 사용자가 눈에 띄게 늘었다는 후기가 Reddit에 다수 올라왔다.
Deep Think 추론 모드 - thinking_level 파라미터로 low/medium/high를 설정할 수 있으며, high 모드에서는 복잡한 멀티스텝 추론을 수행한다. 52개 PDF에서 단백질 접힘 관련 주장을 매핑하고 모순을 식별하는 연구 사례가 보고되었다. 사용자 평가: "노이즈가 많은 데이터에서 서브스텝을 나누고 방해 요소를 플래깅하며 추론 과정을 설명한다." (출처: Reddit 커뮤니티)
SWE-bench 도약 - SWE-bench Verified 76.2%로 Gemini 2.5 Pro(63.8%)에서 12.4%p 향상. SWE-bench Bash-Only 69.6%, Multilingual 68.7%로 터미널 작업과 다국어 코딩에서도 강력하다. (출처: 공식 블로그)
1M 토큰 컨텍스트 - 100만 토큰 입력을 지원하며, 장문 문서 분석과 대규모 코드베이스 처리에서 경쟁 모델 대비 독보적 우위를 가진다. 한 사용자는 "ChatGPT Plus에서 갈아탄 이유가 1M 컨텍스트. 전체 프로젝트 문서를 한번에 넣을 수 있다"고 평가했다. (출처: Reddit)
Thought Signatures - API 호출 간 추론 컨텍스트를 유지하기 위한 암호화된 추론 표현. 멀티턴 대화에서 추론 품질을 유지하는 독특한 기술이다.
할 수 있는 것
대규모 문서 분석
1M 토큰 컨텍스트를 활용한 대량 문서 분석이 핵심 강점이다. 52개 PDF를 한 번에 읽고 주장 간 모순을 찾아내거나, 전체 코드베이스를 한번에 이해하는 작업에서 다른 모델이 따라올 수 없다. 연구자 평가: "단백질 접힘 연구 52편을 넣고 교차 분석을 시켰더니, 최신 증거와 모순되는 주장을 자동으로 플래깅하고 실험까지 제안했다." (출처: Google AI Forum)
코딩
HumanEval 94%, SWE-bench Verified 76.2%로 프론티어급 코딩 능력. 개발자들 사이에서 "GPT-4.5 대비 코드 생성에서 약 20% 우위"라는 평가가 있다. 디버깅, 오류 수정, API 통합에도 유용하다는 후기가 많다. 다만 "긴 반복 코딩 세션에서 상태 저하가 발생하고, 파일 수정 시 기존 코드를 삭제하는 사고가 있었다"는 비판도 있다. Claude Opus 4.5 대비 "돌아가기는 하지만 최소한만 구현하는 경향"이 지적된다. (출처: Reddit, Composio 비교 리뷰)
멀티모달 이해
텍스트, 이미지, 비디오, 오디오, 코드를 통합 처리한다. MMMU 81%로 멀티모달 추론에서 최상위권. 이미지 기반 코드 생성, 비디오 분석, 오디오 전사 등을 하나의 모델에서 수행한다. (출처: 공식 블로그)
수학 추론
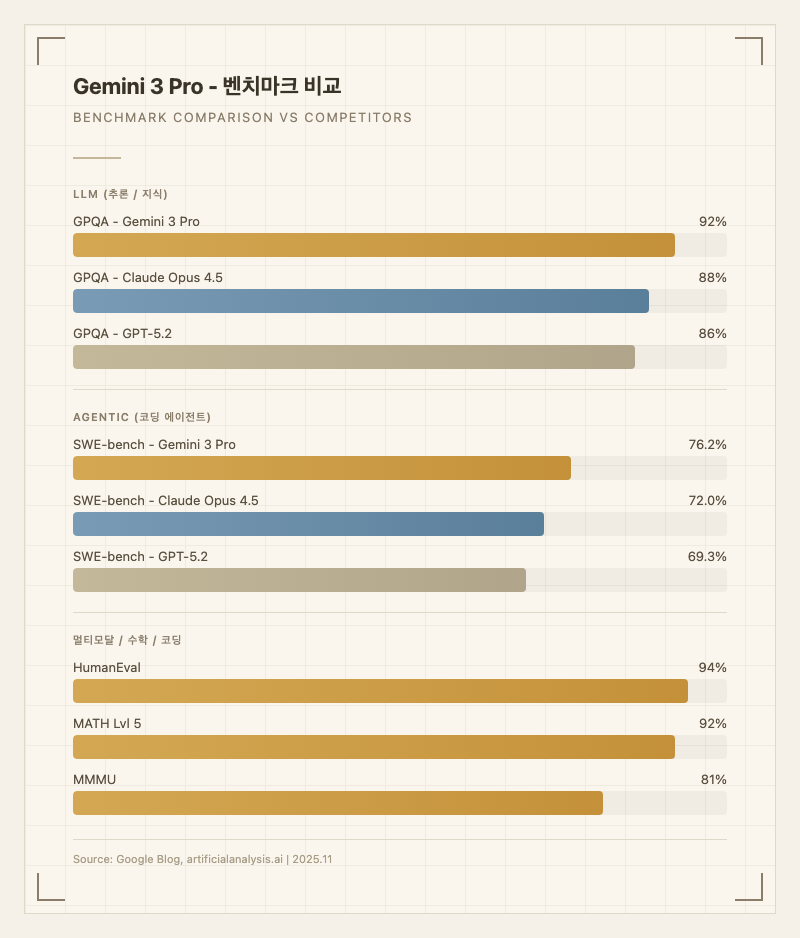
MATH Lvl 5 92%, AIME 2025 95%(코드 실행 시 100%)로 고급 수학에서 최상위 성능. 한 테스터는 "IMO 예선 25문제 중 23문제를 맞혔다"고 보고했다. (출처: Reddit 커뮤니티)
한계
- 할루시네이션: 독립 커뮤니티 벤치마크에서 프론티어 모델 중 가장 높은 할루시네이션 비율이 지적되었다. 팩트체크가 중요한 작업에서는 주의 필요. (출처: Skywork AI 리뷰)
- "최소 실행 가능" 출력: 경쟁 모델(특히 Claude Opus) 대비 "돌아가기는 하지만 최소한만 구현하는" 경향이 있다는 평가. (출처: Composio)
- 긴 세션 불안정: 장시간 반복 코딩 세션에서 상태가 저하되고, 기존 작동하던 코드를 삭제하는 사고 사례가 보고됨. (출처: Google AI Forum)
- 안전 가드레일 과도: 공인 이미지 생성 거부, 비논쟁적 질문에서도 보수적 응답 등 안전 필터가 창작 흐름을 방해한다는 불만. (출처: Reddit)
- Deprecated: 2026년 3월 9일부로 서비스 종료. Gemini 3.1 Pro Preview로 마이그레이션 필요. (출처: Google AI Forum 공지)
성능
벤치마크 결과
| 벤치마크 | 점수 | 카테고리 |
|---|---|---|
| GSM8K | 99% | 수학 |
| AIME 2025 | 95% | 수학 경시대회 |
| HumanEval | 94% | 코딩 |
| GPQA | 92% | 추론 |
| MATH Lvl 5 | 92% | 수학 |
| IFEval | 92% | 지시 따르기 |
| MMLU | 92% | 지식 |
| MMLU-PRO | 90% | 전문 지식 |
| tau-bench (avg) | 87.1% | 에이전트 |
| MMMU | 81% | 멀티모달 |
| SWE-bench Verified | 76.2% | 코딩 에이전트 |
| SWE-bench Bash-Only | 69.6% | 터미널 |
| SWE-bench Multilingual | 68.7% | 다국어 코딩 |
| HLE (no tools) | 37.2% | 고난도 추론 |
| Arena Elo | 1486 | 사용자 선호도 |
(출처: Google 공식 블로그, artificialanalysis.ai, Chatbot Arena)
벤치마크는 이런데 실제로는
체감 품질은 확실히 좋아졌다. Arena Elo 1486이 말해주듯, 사용자들이 실제로 "좋다"고 느끼는 응답 품질이 이전 세대와 확연히 다르다. 특히 Deep Think 모드에서의 복잡한 추론은 "노이즈가 많은 데이터에서 서브스텝을 나누고 방해 요소를 플래깅하며 추론 과정을 설명한다"는 평가. (출처: Reddit)
코딩에서는 양면이 있다. SWE-bench Verified 76.2%는 Gemini 2.5 Pro(63.8%) 대비 큰 도약이지만, 실사용에서는 "최소한만 구현하는 경향"과 "긴 세션에서의 코드 삭제 사고"가 보고되었다. Claude Opus 4.5가 "가장 일관된 코딩 결과와 UI 완성도"라는 비교 평가가 있다. (출처: Composio, CosmicJS)
할루시네이션 문제는 치명적. 프론티어 모델 중 가장 높은 할루시네이션 비율이라는 독립 벤치마크 결과는 심각한 약점이다. 학술 연구나 팩트 기반 작업에서는 반드시 교차 검증이 필요하다. (출처: Skywork AI)
한국어는 최상위권. 2026학년도 수능 테스트에서 국어, 수학, 영어, 한국사 및 탐구 전 과목 만점을 달성. MMMLU(다국어 QA) 91.8%로 GPT-5.2(89.6%)를 앞선다. 한국어 질문에 대한 이해력, 번역 품질, 문화적 맥락 파악이 모두 향상되었다. (출처: 나무위키, 국내 매체 테스트)
경쟁 모델 비교
vs Claude Opus 4.5: Arena Elo 근소 차이(1486 vs 1490). 코딩에서는 Opus가 "가장 일관되고 UI 완성도가 높다"는 평가. Gemini 3 Pro는 1M 토큰 컨텍스트와 멀티모달에서 우위. (출처: CosmicJS, MindStudio 비교)
vs GPT-5.2: GPT-5.2가 재귀, 에러 처리, 엣지 케이스 로직에서 구조적으로 일관된 코드 생성. Gemini 3 Pro는 컨텍스트 윈도우와 비용 효율에서 앞선다. "추론이 필요하면 GPT, 대량 분석이 필요하면 Gemini"라는 사용 패턴. (출처: MindStudio)
vs Gemini 3.1 Pro Preview: 3.1은 ARC-AGI-2 77.1%, SWE-bench Verified 80.6%로 전 영역에서 향상. 현재는 3.1로 마이그레이션 권장. (출처: Google 공식 블로그)
사용 방법
웹/앱
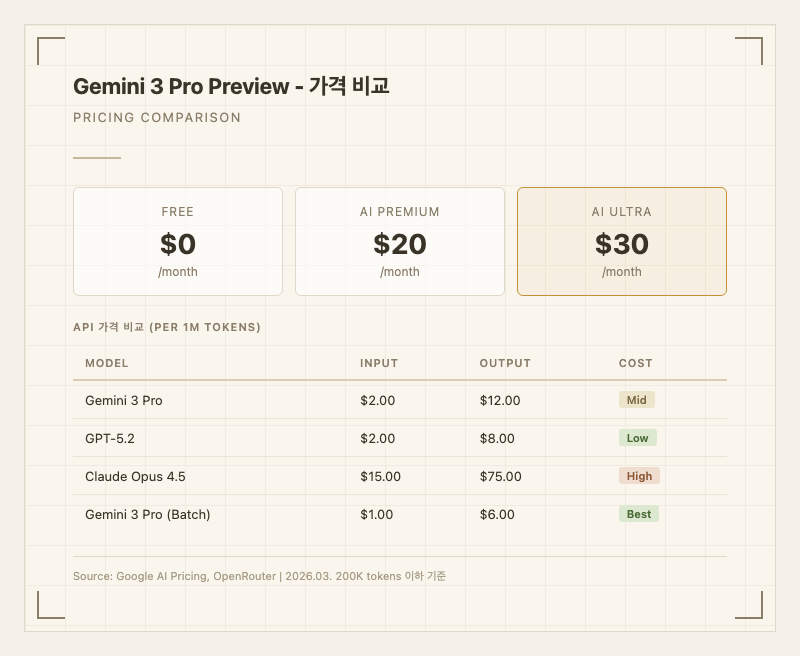
Google Gemini 앱(gemini.google.com)에서 무료 사용 가능. Deep Think 등 고급 기능은 Google AI Ultra 플랜($30/월) 필요.
API
Google AI Studio 또는 Vertex AI에서 접근. 현재는 gemini-3.1-pro-preview로 마이그레이션 필요.
python
from google import genai
client = genai.Client()
response = client.models.generate_content(
model="gemini-3.1-pro-preview", # 3 Pro는 deprecated
contents="..."
)
공식 문서: https://ai.google.dev/gemini-api/docs/gemini-3
가격
구독 플랜
| 플랜 | 가격 | 포함 내용 |
|---|---|---|
| 무료 | $0 | 기본 Gemini 접근 |
| Google AI Premium | $20/월 | Gemini Advanced, 1M 컨텍스트 |
| Google AI Ultra | $30/월 | Deep Think, Antigravity |
API 가격
| 구간 | Input | Output |
|---|---|---|
| 200K 토큰 이하 | $2/1M | $12/1M |
| 200K 토큰 초과 | $4/1M | $18/1M |
| Batch (50% 할인) | $1/1M | $6/1M |
(출처: Google AI Pricing 공식 문서)
가성비 평가
API 가격은 프론티어 모델 중 중간 수준. Claude Opus 4.5(75)보다는 확실히 저렴하지만, GPT-5.2(8)와 비교하면 출력 비용이 더 높다. "Deep Think은 좋은데 Ultra 플랜 1/$6으로 대폭 절감 가능. 1M 컨텍스트를 적극 활용하면 여러 번 API 호출 비용을 아낄 수 있어 대량 문서 분석에서는 오히려 경제적. (출처: Reddit, OpenRouter)
한국어 토큰 효율: 한국어/중국어/일본어 등 아시아 언어는 약 1토큰당 0.6-0.7자로, 영어(1토큰당 약 4자) 대비 토큰 소모가 높다. 동일한 내용을 한국어로 처리하면 영어 대비 약 4-5배의 토큰이 필요하다. (출처: ofox.ai)
기술 사양
| 항목 | 사양 |
|---|---|
| Provider | Google DeepMind |
| Architecture | Transformer (MoE) |
| Modality | Text + Image + Video + Audio (입력), Text + Image (출력) |
| Context Window | 1,048,576 tokens (입력) / 65,536 tokens (출력) |
| Knowledge Cutoff | 2025년 1월 31일 |
| License | Proprietary |
| Release Date | 2025년 11월 20일 |
| Deprecated | 2026년 3월 9일 (3.1 Pro로 대체) |
| Thinking Mode | low / medium / high (Dynamic) |
| Thought Signatures | 멀티턴 추론 컨텍스트 유지 |
| Languages | 100+ |
| Output Speed | 131.3 tokens/sec (Google API 기준) |
| Features | Batch API, Caching, Code Execution, Function Calling, Search Grounding, Maps Grounding, Structured Outputs |
(출처: Google AI 공식 문서, Vertex AI)

참고 자료






스펙
컨텍스트 윈도우
1.0M 토큰
라이선스
Proprietary
출시일
2025년 11월 20일
학습 마감일
2025년 1월 31일
가성비 지수
0.7
API 가격 (혼합)
입력 $2.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$2.00 / 1M 토큰
출력 (Completion)
$12.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
92.0
복잡한 지시사항 이해 및 수행
일반지식
90.0
다양한 분야 지식 및 이해
코딩
85.1
코드 생성, 버그 수정, 소프트웨어 엔지니어링
멀티모달
81.0
이미지, 비디오 등 멀티모달 이해
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 |
|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemini 3 Pro Preview | 91.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |