Gemma 2 27B
GoogleLLM자연어 처리컴퓨터 비전오디오 처리8K 토큰
2024년 7월 13일Gemma
한줄 소개
Gemma 2 27B는 Google DeepMind가 Gemini 연구에서 파생시킨 오픈 웨이트 LLM으로, 27B 파라미터라는 비교적 작은 크기에서 70B급 모델과 경쟁하는 성능을 보여주는 실용적인 오픈소스 모델이다. 2024년 6월 공개되었으며, 지식 증류(knowledge distillation) 기법을 통해 대규모 모델의 능력을 압축한 것이 핵심 전략이다.
주요 특징
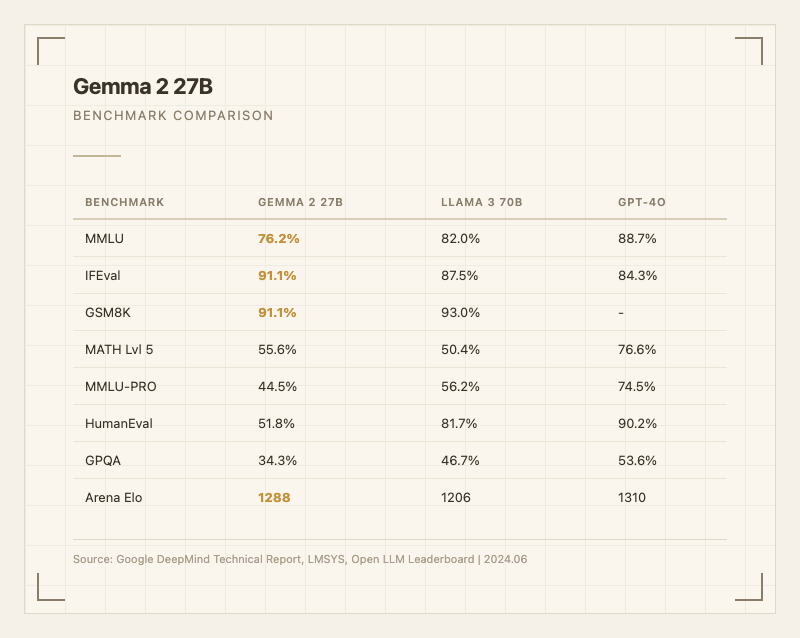
Gemma 2 27B의 가장 큰 차별점은 파라미터 효율성이다. Llama 3 70B의 절반도 안 되는 크기로 LMSYS Chatbot Arena에서 Elo 1288을 기록하며, 출시 당시 오픈 모델 중 1위를 차지했다 (출처: LMSYS Chatbot Arena). Llama 3 70B(Elo 1206)를 82점 차이로 앞섰다는 건, 실제 사용자들이 체감하는 대화 품질에서 확실한 우위가 있다는 의미다.
아키텍처 면에서는 interleaved local/global attention과 4096 토큰 슬라이딩 윈도우, GQA(Grouped Query Attention, KV 헤드 16개)를 조합해서 추론 속도를 끌어올렸다. 로짓 소프트캐핑(logit soft-capping)으로 학습 안정성도 확보했다. 실사용자들 사이에서는 "크기 대비 놀랍다"는 반응이 많았고, 특히 단일 GPU에서 돌릴 수 있다는 점이 로컬 배포를 원하는 개발자들에게 큰 장점으로 꼽혔다.
256K 크기의 SentencePiece 어휘를 사용해 다국어 토크나이징 효율이 비교적 좋은 편이며, 커뮤니티에서는 "27B 모델이 여러 비주류 언어에서도 거의 완벽에 가깝다"는 평가가 있었다 (출처: Reddit 커뮤니티).

할 수 있는 것
Gemma 2 27B는 텍스트 생성 전반에 걸쳐 활용된다. 질의응답, 요약, 추론, 창작 글쓰기가 주요 유스케이스다. 실사용자 리뷰에 따르면 창작 글쓰기에서 특히 강점을 보여서, 한 리뷰어는 "아름다운 산문과 즐거운 이야기를 만들어낸다"고 평가했다 (출처: Medium 리뷰).
반면 논리적 추론에서는 한계가 뚜렷하다. 같은 리뷰에서 Llama 3가 추론 테스트에서 3문제 중 2개를 맞춘 반면, Gemma 2는 1개도 제대로 못 맞추는 경우가 있었다. GPQA 34.3%라는 수치가 이를 뒷받침한다 (출처: 공식 테크니컬 리포트). 과학적 추론이 필요한 작업에는 적합하지 않다.
코딩 보조 도구로도 활용 가능하지만 HumanEval 51.8%로 간단한 수준에 머문다. 한국의 ReturnZero는 Gemma 2를 파인튜닝해서 통화 요약 서비스를 개발했는데 (출처: Google Developers Korea Blog), 이처럼 특정 도메인에 파인튜닝하면 실용적인 결과를 얻을 수 있다.
텍스트 전용 모델이므로 이미지, 오디오, 비디오 처리는 불가하다. 8K 토큰 컨텍스트 윈도우라는 제약도 있어서 긴 문서 처리에는 부적합하다.
성능
| 벤치마크 | 점수 | 비고 |
|---|---|---|
| MMLU | 76.2% | 일반 지식 (출처: 공식 리포트) |
| IFEval | 91.1% | 지시 따르기 (출처: 공식 리포트) |
| GSM8K | 91.1% | 기초 수학 (출처: 공식 리포트) |
| MATH Lvl 5 | 55.6% | 중급 수학 (출처: 공식 리포트) |
| MMLU-PRO | 44.5% | 심화 지식 (출처: Open LLM Leaderboard) |
| HumanEval | 51.8% | 코딩 (출처: 공식 리포트) |
| GPQA | 34.3% | 과학 추론 (출처: 공식 리포트) |
| BBH | 64.5% | 복합 추론 (출처: Open LLM Leaderboard) |
| Arena Elo | 1288 | 실사용 평가 (출처: LMSYS) |
| HellaSwag | 86.4% | 상식 추론 (출처: 공식 리포트) |
IFEval 91.1%와 GSM8K 91.1%는 대형 모델에 필적하는 안정적인 수치다. 지시를 정확히 따르고 기초 수학을 잘 푸는 건 실무에서 체감되는 부분이다. 반면 GPQA 34.3%, MMLU-PRO 44.5%는 전문적인 추론이나 심화 지식에서 확실한 한계를 드러낸다.
실사용자들의 체감은 벤치마크 수치보다 긍정적인 편이다. Arena Elo 1288이 이를 반영하는데, 실제 대화에서 자연스러운 응답을 잘 생성한다는 의미다. 다만 "벤치마크에서는 괜찮은데 실제 복잡한 추론 과제를 주면 한계가 보인다"는 의견도 있었고, 특히 할루시네이션이 이전 모델 대비 줄었다는 평가를 받았다 (출처: Medium 비교 리뷰).
사용 방법
일반 사용자: Google AI Studio(aistudio.google.com)에서 별도 하드웨어 없이 바로 테스트할 수 있다. Ollama를 통한 로컬 실행도 가능하다 (ollama run gemma2:27b).
개발자: HuggingFace Transformers를 통해 직접 로드할 수 있다.
python
from transformers import pipeline
import torch
pipe = pipeline(
"text-generation",
model="google/gemma-2-27b-it",
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [{"role": "user", "content": "Hello"}]
outputs = pipe(messages, max_new_tokens=256)
Kaggle, HuggingFace, NVIDIA NIM에서 가중치를 다운로드할 수 있으며, bitsandbytes를 통한 8비트/4비트 양자화도 지원한다. torch.compile 적용 시 최대 6배 추론 속도 향상이 가능하다 (출처: HuggingFace 모델 카드).
가격
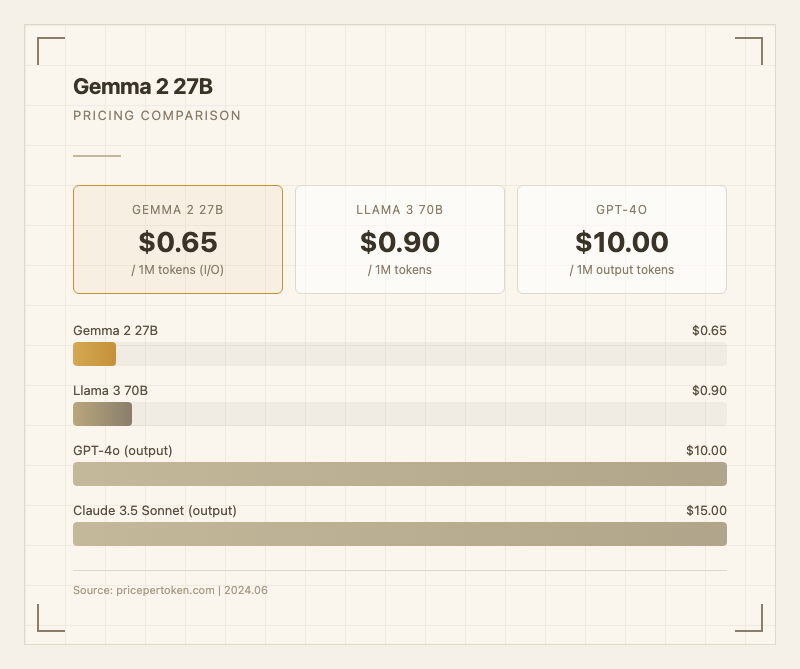
API 사용 시 입력/출력 모두 10/1M 출력 토큰) 대비 약 15배, Claude 3.5 Sonnet(0.90/1M)보다도 낮은 가격이다.
오픈 웨이트이므로 자체 호스팅 시 API 비용은 0이다. 양자화(Q4_K_M 등)를 적용하면 소비자용 GPU에서도 구동 가능해서 하드웨어 비용까지 절감할 수 있다. 가성비 측면에서 실사용자들의 평가는 매우 긍정적이며, "이 가격에 이 성능이면 충분하다"는 의견이 다수다.
한국어 토큰 효율 데이터는 공식적으로 미공개 상태다. 256K 어휘의 SentencePiece 토크나이저를 사용하므로 다국어 토크나이징 효율은 비교적 양호하지만, 구체적인 한국어 압축 비율 데이터는 확인되지 않았다.
기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 | 27B (26.8B) |
| 아키텍처 | Decoder-only Transformer |
| 레이어 | 46 |
| 히든 차원 | 4,608 |
| 어텐션 헤드 | 32 (KV 헤드: 16) |
| 어텐션 방식 | GQA + Interleaved Local/Global + Sliding Window (4096) |
| 활성화 함수 | GeGLU |
| 어휘 크기 | 256,128 (SentencePiece) |
| 컨텍스트 윈도우 | 8,192 토큰 |
| 정밀도 | BF16 (bfloat16) |
| 학습 데이터 | 13조 토큰 (웹, 코드, 수학) |
| 학습 인프라 | TPUv5p, JAX + ML Pathways |
| 학습 데이터 기준일 | ~2024년 6월 |
| 출시일 | 2024년 6월 27일 |
| 라이선스 | Gemma (상업적 사용 허용) |
Gemini 연구에서 사용된 것과 동일한 기술 기반으로 제작되었으며, 13조 토큰의 주로 영어 중심 데이터로 학습되었다. 텍스트 전용 디코더 모델로, 멀티모달 기능은 후속 모델인 Gemma 3에서 추가되었다.

참고 자료




스펙
컨텍스트 윈도우
8K 토큰
라이선스
Gemma
출시일
2024년 7월 13일
학습 마감일
2024년 6월 30일
가성비 지수
7.6
API 가격 (혼합)
입력 $0.650/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.65 / 1M 토큰
출력 (Completion)
$0.65 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
91.1
복잡한 지시사항 이해 및 수행
코딩
51.8
코드 생성, 버그 수정, 소프트웨어 엔지니어링
수학/추론
45.0
수학, 과학, 논리적 추론
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 49.6
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1288.0 | elo |
| BBH | 64.5 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemma 2 27B | 49.6 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |