GPT-4o
OpenAILMM시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)128K 토큰
2024년 5월 13일Proprietary
OpenAI가 2024년 5월 13일 출시한 멀티모달 모델. 'o'는 'omni'를 의미하며, 텍스트와 이미지를 동시에 처리하는 통합 모델이다. ChatGPT의 기본 모델로 2년간 운영되며 전 세계에서 가장 많이 사용된 프리미엄 AI 모델이 되었다. 2026년 4월 ChatGPT에서 은퇴했지만, API는 계속 사용 가능하며 사용자들의 강한 애착을 받는 독특한 위치의 모델이다.
주요 특징
GPT-5보다 사랑받은 모델 - GPT-4o의 가장 특이한 위치는 후속 모델인 GPT-5 출시 후 더 주목받았다는 점이다. GPT-5 출시 직후 Reddit에서 "horrible"이라는 4,600 좋아요 게시글이 올라왔고, 사용자들은 GPT-4o가 더 인간적이고 매력적이라고 평가했다. 850건의 이중 블라인드 테스트에서 GPT-4o가 GPT-5보다 선호되었다(48% vs 43%). 결국 OpenAI는 24시간 만에 GPT-4o를 복원하는 전례 없는 조치를 취했다. "GPT-4.5가 진심으로 나와 대화했는데, GPT-5는 기업적이고 건조한 한 문장만 던진다"는 사용자 반응이 대표적이다.
네이티브 멀티모달 - 텍스트와 이미지를 하나의 모델에서 처리. MMBench 81.8, AI2D 84.7, RealWorldQA 76.5로 비전 벤치마크에서 강력한 성능. GPT-4 대비 2배 빠른 응답 속도를 제공한다.
한국어 토큰 효율 혁신 - 한국어 토큰 사용을 70% 개선(45개 -> 27개 토큰). 비영어권 언어 성능을 본격적으로 향상시킨 첫 GPT 모델이다. 한국어 뉘앙스 파악 능력이 크게 향상되었다는 평가를 받았다.
빠른 속도 - 136.7 tok/s로 현세대 프론티어 모델(Opus 4.6: 43 tok/s)보다도 빠르다. 대량 처리와 실시간 응답에 적합.

할 수 있는 것
범용 대화 AI
2년간 ChatGPT의 기본 모델로 운영되며 검증된 안정성. 일상 대화, 질의응답, 글쓰기 보조, 브레인스토밍에서 자연스러운 톤과 인간적인 성격이 강점이다. 커뮤니티 평가: "벤치마크는 GPT-5가 높지만, 실제 대화 품질은 GPT-4o가 낫다."
멀티모달 분석
이미지 기반 질의응답, 차트 분석, 문서 OCR, 제품 이미지 분류 등. MMMU 69.9%, ScienceQA 90.1%로 시각적 이해와 과학 문제 풀이에서 실용적인 수준.
대량 프로덕션 워크플로우
10의 가격과 136.7 tok/s 속도로 대량 처리에 적합. 콘텐츠 생성, 이메일 분류, 데이터 추출 등 "충분히 좋은 품질을 빠르게" 처리하는 워크플로우의 표준.
안 되는 것
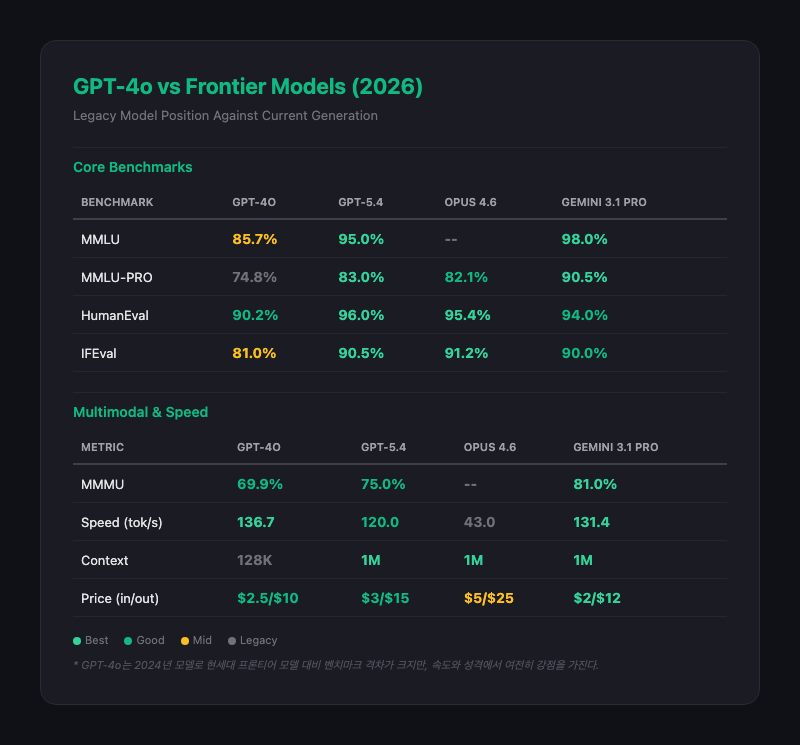
- 현세대 프론티어 모델과의 격차: MMLU-PRO 74.8%(Gemini 3.1 Pro: 90.5%), SWE-bench 미지원. 고급 추론, 에이전트 코딩에서는 세대 차이가 명확하다.
- 128K 컨텍스트 한계: 64K 이상에서 검색 정확도 급락(94% -> 23%). 현세대의 1M 컨텍스트와 비교 불가.
- 2023년 10월 지식 컷오프: 2024년 이후 정보를 모른다. 현세대 모델(2025년 지식)과 1년 이상 격차.
- ChatGPT 은퇴: 2026년 4월 3일부로 ChatGPT에서 서비스 종료. API만 사용 가능.
성능
벤치마크 결과
| 벤치마크 | 점수 | 카테고리 |
|---|---|---|
| MMLU | 85.7% | 지식 |
| MMLU-PRO | 74.8% | 지식 |
| HumanEval | 90.2% | 코딩 |
| IFEval | 81.0% | 지시 따르기 |
| MMMU | 69.9% | 멀티모달 |
| MMBench | 81.8% | 멀티모달 |
| ScienceQA | 90.1% | 과학 |
| AI2D | 84.7% | 비전 |
| RealWorldQA | 76.5% | 비전 |
벤치마크는 이런데 실제로는
"성격"이 가장 큰 장점이다. 벤치마크 수치로는 설명이 안 되는 부분이다. GPT-5가 모든 벤치마크에서 앞서지만, 실사용자 850명 블라인드 테스트에서 GPT-4o가 더 선호되었다. 창의적 글쓰기에서 감각적 디테일, 긴장감, 분위기가 살아 있다는 평가. GPT-5는 "선언적 문장 3개와 일반적 내용"을 내놓는다는 비교.
코딩은 실용적이지만 최신 모델에 뒤진다. HumanEval 90.2%로 코드 생성은 강하지만, SWE-bench 같은 실무 코딩에서는 현세대 모델(80%+)과 격차가 크다.
속도는 여전히 강점이다. 136.7 tok/s는 Opus 4.6(43 tok/s)의 3배. 대량 처리나 실시간 응답이 중요한 서비스에서 현세대 프리미엄 모델보다 유리할 수 있다.
사용 방법
API
OpenAI API, Azure OpenAI에서 사용 가능. model ID는 gpt-4o이다.
python
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "..."}]
)
이미지 입력도 지원한다(URL 또는 base64).
ChatGPT
2026년 4월 3일부로 ChatGPT에서 서비스 종료. GPT-5 시리즈로 마이그레이션 필요.
가격
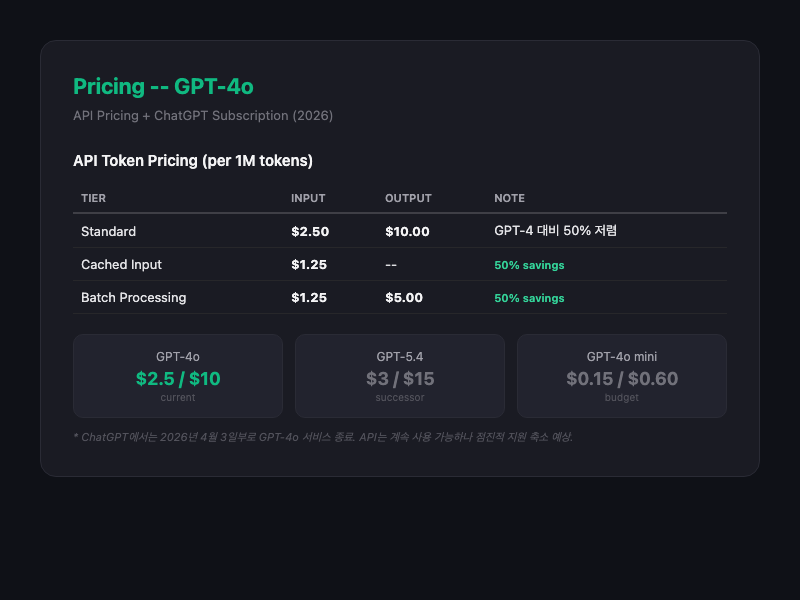
API 가격 (1M 토큰당)
| 티어 | Input | Output | 비고 |
|---|---|---|---|
| Standard | $2.50 | $10.00 | 2025년 10월 인하 (2.50) |
| Cached Input | $1.25 | - | 50% 절감 |
| Batch | $1.25 | $5.00 | 50% 절감 |
가성비 평가
10은 현세대 기준으로 중간 가격대다. GPT-5.4(15)보다 약간 싸고, Gemini 3.1 Pro(12)와 비슷하지만 성능은 한 세대 뒤진다. "레거시 모델 가격으로 레거시 성능"이라는 평가가 맞지만, 속도(136 tok/s)와 성격(인간적 톤)이라는 고유 가치가 있어서 일부 사용 사례에서는 여전히 합리적이다. GPT-4o mini(0.60)가 비용 민감 워크플로우에서는 더 나은 선택.
기술 사양
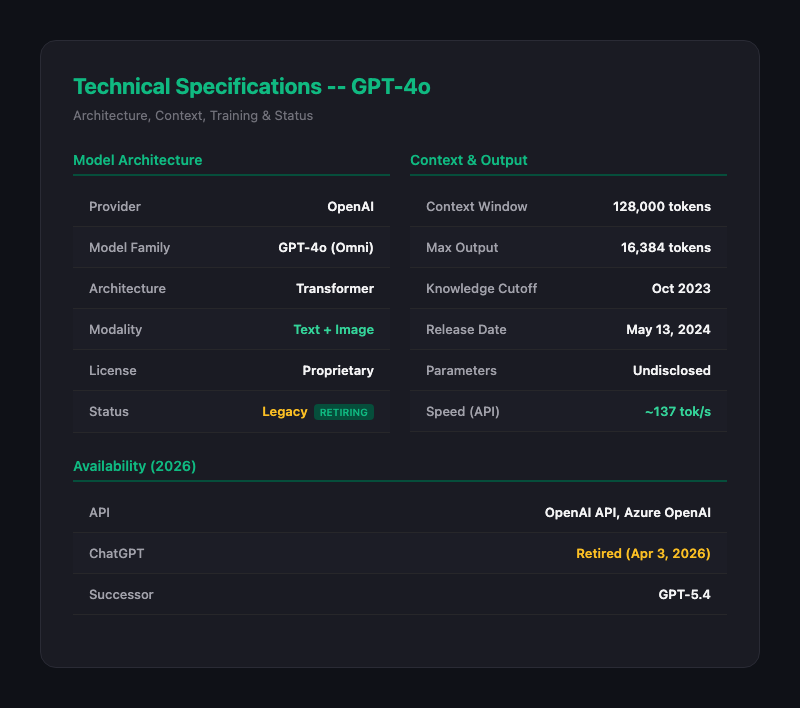
| 항목 | 사양 |
|---|---|
| Provider | OpenAI |
| Architecture | Transformer |
| Modality | Text + Image (입력), Text (출력) |
| Context Window | 128,000 tokens |
| Max Output | 16,384 tokens |
| Knowledge Cutoff | 2023년 10월 |
| Release Date | 2024년 5월 13일 |
| Parameters | 비공개 |
| License | Proprietary |
| API Speed | ~137 tok/s |
| Status | Legacy (ChatGPT 은퇴, API 유지) |
| Successor | GPT-5.4 |
References
- Hello GPT-4o - OpenAI - 공식 발표 블로그
- GPT-4o Pricing - OpenAI - 공식 가격 페이지
- Everyone Is Wrong About Why GPT-5 Feels Worse Than GPT-4o - RoboRhythms - GPT-5 vs 4o 논란 분석
- GPT-4o Retired: What Replaced It - NxCode - 은퇴 및 마이그레이션 가이드
- GPT-4o - Artificial Analysis - 독립 성능 분석
스펙
컨텍스트 윈도우
128K 토큰
라이선스
Proprietary
출시일
2024년 5월 13일
학습 마감일
2023년 10월 31일
가성비 지수
0.7
API 가격 (혼합)
입력 $2.50/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$2.50 / 1M 토큰
출력 (Completion)
$10.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
81.0
복잡한 지시사항 이해 및 수행
멀티모달
75.2
이미지, 비디오 등 멀티모달 이해
일반지식
72.6
다양한 분야 지식 및 이해
코딩
61.7
코드 생성, 버그 수정, 소프트웨어 엔지니어링
Provider
OpenAI
분류
시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)Multimodal TransformerLMM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 |
|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| GPT-4o | 66.2 |
| Nova Pro 1.0 | 68.4 |
| Gemma 4 | 86.2 |
| Claude 3 Haiku | 46.5 |
| Nova Premier 1.0 | 73.2 |