Gemma 3 4B
GoogleSLM자연어 처리컴퓨터 비전오디오 처리131K 토큰
2025년 3월 14일Gemma License
한줄 소개
Gemma 3 4B는 Google DeepMind가 2025년 3월에 공개한 43억 파라미터 오픈 웨이트 멀티모달 모델이다. Gemini 2.0 계열의 기술을 기반으로, 텍스트와 이미지를 동시에 이해하면서도 스마트폰이나 라즈베리파이 같은 엣지 디바이스에서 실행할 수 있을 정도로 가볍다. 140개 이상의 언어를 지원하며, 128K 토큰 컨텍스트 윈도우를 탑재해 소형 모델의 한계를 상당 부분 극복했다.
주요 특징

Gemma 3 4B의 가장 눈에 띄는 점은 크기 대비 성능이다. IFEval 90.2%, MATH Lvl 5 75.6%, GSM8K 89.2%로, 이 수치는 일부 70B급 모델과 견줄 만한 수준이다 (출처: 공식 기술 보고서 arXiv:2503.19786). 실제로 Gemma 2 27B IT를 다수 벤치마크에서 능가하는데, 파라미터 수는 6분의 1에 불과하다.
멀티모달 지원도 큰 차별점이다. 같은 크기의 경쟁 모델인 Phi 4 Mini(3.8B)가 텍스트만 처리하는 반면, Gemma 3 4B는 이미지 입력을 지원한다. DocVQA 75.8, AI2D 74.8 수준이면 문서 스캔이나 다이어그램 이해가 실용적으로 가능한 수준이다 (출처: 공식 모델 카드).
토크나이저 업그레이드도 실사용에서 체감된다. Gemini 2.0 계열의 SentencePiece 토크나이저(262K 어휘)를 채택해서, 한국어를 포함한 CJK 언어의 토큰 효율이 이전 세대 대비 크게 개선됐다. 올리브영 기술팀에서 실제로 확인한 바에 따르면, 동일한 한국어 텍스트를 처리할 때 이전 세대 대비 토큰 수가 줄어들어 메모리 사용량과 추론 속도가 향상됐다 (출처: 올리브영 테크블로그).
5:1 로컬/글로벌 어텐션 인터리빙 아키텍처를 써서 128K 컨텍스트를 효율적으로 처리한다. 글로벌 어텐션의 RoPE 주파수를 1M으로 설정하고, 로컬 어텐션은 10K로 유지하는 방식이다 (출처: 기술 보고서).
실사용자들 사이에서는 "4B 모델의 sweet spot"이라는 평이 많다. 로컬 실행 시 논리 추론에서 가끔 더 큰 모델(12B, 27B)을 능가하는 결과가 나오기도 해서, "크기가 전부가 아니다"는 인식을 퍼뜨린 모델이기도 하다 (출처: zazencodes.com 리뷰).
할 수 있는 것
Gemma 3 4B로 실제로 해볼 수 있는 것과 없는 것을 정리하면 다음과 같다.
된다고 확인된 것들:
- 한국어 텍스트 요약, 분류, 엔티티 추출. 올리브영에서는 T4 GPU 1장으로 Gemini 2.0 Flash 대비 0.95 수준의 정확도를 유지하면서 프롬프트 길이를 81% 줄이는 데 성공했다 (출처: 올리브영 테크블로그).
- 이미지 속 텍스트 인식(OCR 대체), 다이어그램 해석, 문서 이해. DocVQA 75.8은 실무 수준이다.
- 코드 생성. HumanEval 71.3%, MBPP 63.2%로 간단한 유틸리티 함수 작성이나 코드 리뷰 보조에 쓸 만하다.
- 함수 호출(function calling)과 구조화된 출력(structured outputs) 지원.
- 140개 이상 언어로 다국어 대화.
- 모바일/엣지 디바이스에서의 온디바이스 AI. 4bit 양자화 시 ~3.4GB VRAM이면 충분하다.
실망스러운 부분:
- 비주얼 유머 인식은 못한다. 강제원근법 사진이나 밈의 의도를 해석하지 못한다는 리뷰가 있다 (출처: zazencodes.com).
- 한국어 오타 정정(Typo Robustness) 성능이 상대적으로 낮다. 올리브영 팀에서 리뷰 기반 생성 태스크에 부적합하다고 판단한 바 있다 (출처: 올리브영 테크블로그).
- "인기 있는 구글 검색어에 대응하는 수준"이라는 평가도 있다. 즉, 비주류 주제나 깊은 전문 지식이 필요한 질문에서는 한계가 뚜렷하다 (출처: dotnetperls.com 리뷰).
- 코드 생성에서 완전한 프로젝트를 구성하는 수준은 아니다. 간단한 디자인 개선은 가능하지만, Cline 같은 도구와 통합해서 복잡한 기능을 구현하는 데는 실패한 사례가 보고됐다 (출처: zazencodes.com).
- 유의 자릿수(significant figures) 반올림 같은 특수한 수학 문제에서 오답을 내는 경우가 있다.
on-device 한국어 작업의 경우, 1B 모델로는 아주 제한적인 작업(엔티티 추출 등)만 가능하고, 실질적으로 쓸 만한 수준은 4B부터라는 의견이 한국 개발자 커뮤니티에서 나오고 있다 (출처: threads.com/@ethanoncloud).
성능
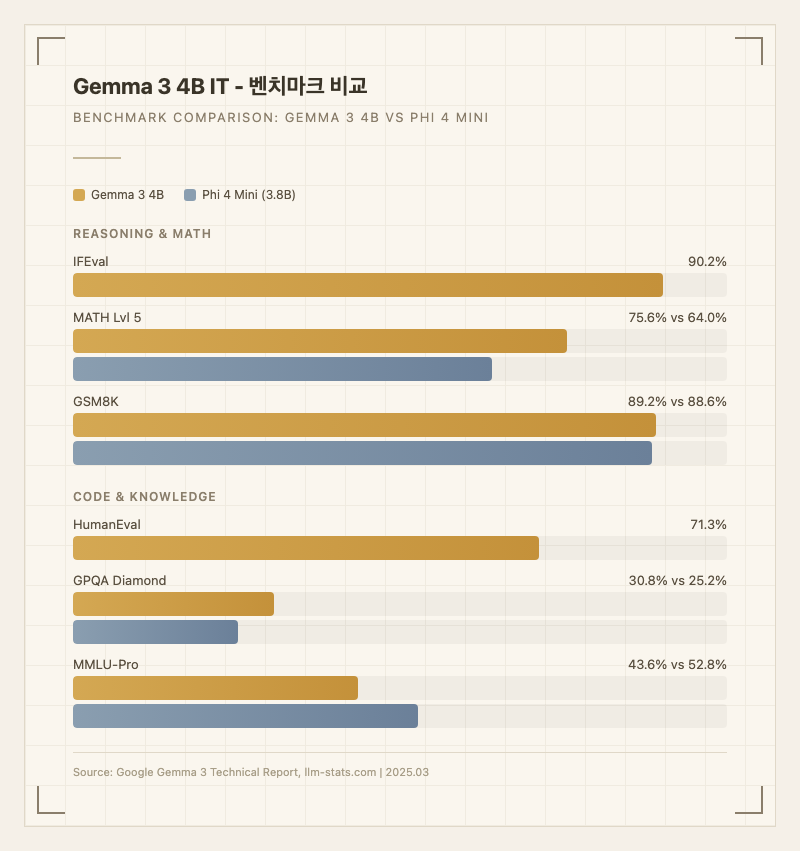
벤치마크 수치
| 벤치마크 | Gemma 3 4B | Phi 4 Mini (3.8B) | 비고 |
|---|---|---|---|
| IFEval | 90.2% | - | 지시 따르기 (출처: 기술 보고서) |
| MATH Lvl 5 | 75.6% | 64.0% | 수학 추론 (출처: 기술 보고서, llm-stats.com) |
| GSM8K | 89.2% | 88.6% | 수학 (출처: 기술 보고서, llm-stats.com) |
| HumanEval | 71.3% | - | 코드 생성 (출처: 기술 보고서) |
| MBPP | 63.2% | - | 코드 (출처: 기술 보고서) |
| GPQA Diamond | 30.8% | 25.2% | 대학원 수준 과학 (출처: 기술 보고서, llm-stats.com) |
| MMLU-Pro | 43.6% | 52.8% | 전문 지식 (출처: 기술 보고서, llm-stats.com) |
| BBH | 72.2% | 70.4% | 추론 (출처: 기술 보고서, llm-stats.com) |
| MMMU | 48.8% | - | 멀티모달 이해 (출처: 모델 카드) |
| AI2D | 74.8% | - | 다이어그램 이해 (출처: 모델 카드) |
| DocVQA | 75.8% | - | 문서 QA (출처: 모델 카드) |
Artificial Analysis Intelligence Index에서는 26개 모델 중 6위로, "같은 크기 오픈 모델 중 중간 이하" 수준이라는 평가를 받았다 (출처: artificialanalysis.ai). 다만 이 인덱스는 주로 순수 텍스트 지능을 측정하기 때문에, 멀티모달 능력이나 가격 대비 성능은 반영되지 않는다.
벤치마크와 실제 체감의 괴리
벤치마크 수치만 보면 MMLU-Pro 43.6%가 Phi 4 Mini의 52.8%에 뒤지지만, 실사용에서는 다른 양상이다. Chatbot Arena에서 Elo 1365를 기록했는데, 이는 사용자 블라인드 평가에서 훨씬 큰 모델들과 경쟁한 결과다 (출처: 기존 DB 데이터). 벤치마크 하나하나보다 "전반적으로 쓸 만한가"에서 높은 평가를 받고 있다는 뜻이다.
속도 면에서는 Artificial Analysis 측정 기준 31.4 tokens/sec로, 같은 사이즈 모델 중 다소 느린 편이다 (중간값 87.1 t/s). TTFT(Time to First Token)도 1.42초로 평균(0.88초)보다 느리다 (출처: artificialanalysis.ai). 로컬에서 Ollama로 돌릴 때는 상당히 빠르다는 평이 많지만, API 서비스 기준으로는 속도가 아쉬운 부분이다.
단점도 분명하다. 글자 수 세기 같은 단순한 작업에서 무한 루프에 빠지기도 하고, 이미지의 맥락을 정확히 파악하지 못하는 경우가 있다. 일본 화투 카드를 지폐로 잘못 인식하거나, 마야 문자를 맥락 없이 보여주면 린디스판 복음서로 오인하는 등 시각 인식의 한계가 드러나기도 한다 (출처: zazencodes.com 리뷰).
사용 방법
일반 사용자
- Google AI Studio(ai.google.dev)에서 무료로 사용 가능. 별도 설치 없이 웹 브라우저에서 바로 대화할 수 있다.
- Ollama를 설치하면 로컬에서도 실행 가능.
ollama run gemma3:4b명령어 한 줄이면 된다. 8GB RAM Mac에서도 구동되지만, 16GB면 스왑 없이 쾌적하다. - QAT(양자화 인식 학습) 버전이 일반 양자화 버전보다 답변 품질이 나으므로 QAT 모델을 권장한다.
개발자
- Google AI Gemini API를 통해 API 호출 가능.
gemma-3-4b-it모델 ID를 사용한다. - Hugging Face에서 모델 가중치를 직접 다운로드해서 transformers, vLLM 등으로 서빙할 수 있다.
- OpenRouter, Together AI, DeepInfra 등 서드파티 API 프로바이더를 통해서도 사용 가능.
- 파인튜닝은 T4 GPU 1장에서도 가능하지만, QLoRA + gradient checkpointing + batch accumulation이 필수다 (출처: 올리브영 테크블로그).
가격
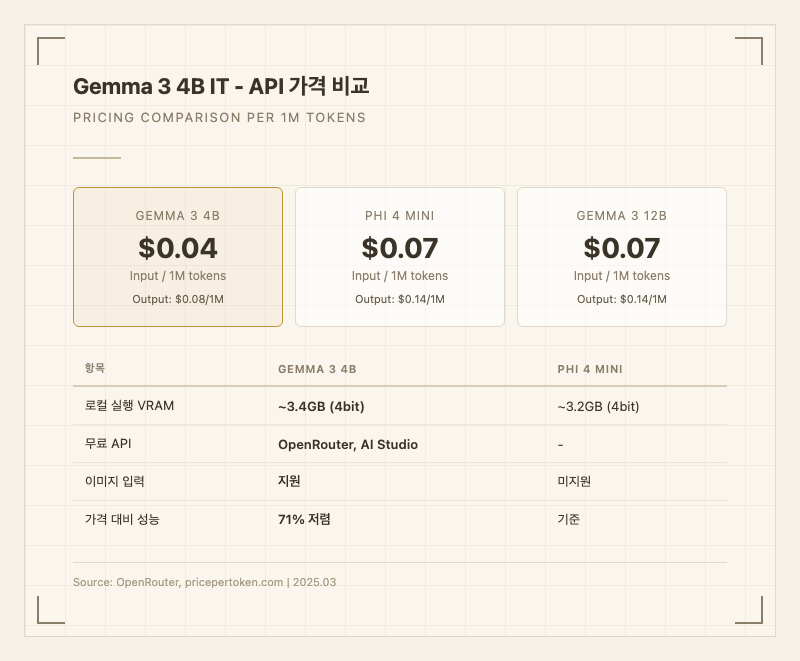
API 기준 입력 0.08/1M 토큰으로 거의 무료에 가까운 수준이다 (출처: pricepertoken.com). Phi 4 Mini 대비 71% 저렴하다.
무료로 쓸 수 있는 경로도 있다:
- Google AI Studio: 무료 (속도 제한 있음)
- OpenRouter free 티어: 입출력 모두 $0.00/1M 토큰 (출처: openrouter.ai)
로컬 실행 시에는 API 비용이 전혀 들지 않는다. 4bit 양자화 기준 ~3.4GB VRAM이면 충분하고, 디스크 용량도 ~3.3GB 수준이다. 전기료 외에는 추가 비용이 없다는 점이 소규모 프로젝트나 학습 목적에서 큰 장점이다.
한국어 토큰 효율에 대해서는 정확한 수치 데이터가 공식적으로 공개되지 않았다. 다만 Gemini 2.0 계열 토크나이저(262K vocab)를 사용하므로 이전 세대 대비 한국어 토큰 수가 감소한 것은 확인됐다. 올리브영 사례에서 "동일한 한국어 텍스트의 토큰 수가 줄어들어 메모리 사용량과 추론 속도가 향상됐다"고 보고한 바 있다 (출처: 올리브영 테크블로그).
가성비 측면에서 4B 크기 모델 중 현재 가장 경쟁력 있는 위치에 있다. 멀티모달 지원 + 128K 컨텍스트 + 이 가격대의 조합을 제공하는 경쟁 모델은 없다.
기술 사양

| 항목 | 사양 |
|---|---|
| 파라미터 | 4.3B |
| 아키텍처 | Transformer (5:1 로컬/글로벌 어텐션 인터리빙) |
| 컨텍스트 윈도우 | 131,072 tokens (128K) |
| 토크나이저 | SentencePiece 262K vocab (Gemini 2.0 계열) |
| 학습 데이터 | 4T tokens |
| 학습 마감일 | 2024-08-31 |
| 입력 | 텍스트 + 이미지 |
| 출력 | 텍스트 |
| 라이선스 | Gemma License (상업적 사용 가능, 조건부 오픈 웨이트) |
| 출시일 | 2025-03-13 |
| VRAM (BF16) | ~6.4GB |
| VRAM (4bit) | ~3.4GB |
| 지원 언어 | 140개 이상 |
라이선스 관련 참고: Gemma License는 Apache 2.0이 아닌 Google 자체 라이선스다. 상업적 사용은 허용하지만, Google의 금지 사용 정책을 위반할 경우 Google이 원격으로 사용을 제한할 수 있는 조항이 포함되어 있다. 파생 모델도 동일한 라이선스 조건을 따라야 하며, Gemma로 생성한 합성 데이터로 학습한 모델 역시 Gemma License가 적용된다 (출처: ai.google.dev/gemma/terms). 이 라이선스 구조 때문에 시장 채택이 더딘 편이라는 분석도 있다 (출처: TechCrunch).
참고 자료






스펙
컨텍스트 윈도우
131K 토큰
라이선스
Gemma License
출시일
2025년 3월 14일
학습 마감일
2024년 8월 31일
가성비 지수
71.5
API 가격 (혼합)
입력 $0.040/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.04 / 1M 토큰
출력 (Completion)
$0.08 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
90.2
복잡한 지시사항 이해 및 수행
코딩
71.3
코드 생성, 버그 수정, 소프트웨어 엔지니어링
멀티모달
61.8
이미지, 비디오 등 멀티모달 이해
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerSLM
성능 평가
LLM 종합 55.2
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| AI2D | 74.8 | % |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemma 3 4B | 55.2 |
| Llama 3.2 3B Instruct | 43.7 |