Llama 3.2 3B Instruct
MetaSLM자연어 처리컴퓨터 비전오디오 처리128K 토큰
2024년 9월 25일Llama Community License
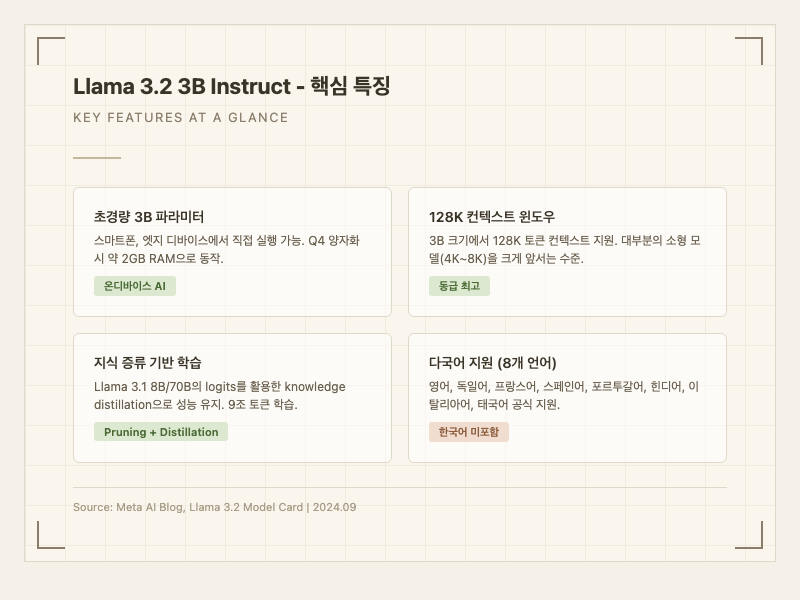
Meta가 2024년 9월 Connect 행사에서 공개한 Llama 3.2 3B Instruct는, 스마트폰이나 엣지 디바이스에서 직접 돌릴 수 있도록 설계된 초경량 언어 모델이다. 3B 파라미터라는 크기에서 실용적인 성능을 뽑아내는 것이 핵심 목표이며, Llama 3.1 8B와 70B 모델의 지식을 증류(distillation)해서 만들었다.
주요 특징
Llama 3.2 3B의 가장 눈에 띄는 점은 크기 대비 컨텍스트 윈도우다. 128K 토큰을 지원하는데, 같은 크기대의 소형 모델 대부분이 4K에서 8K 수준에 머무르는 것과 비교하면 압도적이다. 다만 실사용자들 사이에서는 "128K를 지원한다고는 하지만, 3B 크기에서 긴 문서를 넣으면 품질이 눈에 띄게 떨어진다"는 의견이 많다. NIH/Multi-needle 벤치마크에서 84.7점을 기록해 긴 컨텍스트 내 정보 검색 자체는 잘 하지만, 실제 복잡한 장문 요약에서는 기대만큼의 성능을 내지 못한다는 평가다 (출처: 공식 모델 카드).
학습 방식도 독특하다. 단순히 3B 모델을 처음부터 학습한 것이 아니라, 먼저 더 큰 모델에서 pruning(가지치기)으로 구조를 줄인 다음, Llama 3.1 8B와 70B의 출력값(logits)을 활용한 knowledge distillation으로 성능을 복원했다. 9조 토큰의 공개 데이터로 학습되었으며, Grouped Query Attention(GQA)을 사용해 추론 효율을 높였다.
다국어 지원은 영어 포함 8개 언어(독일어, 프랑스어, 이탈리아어, 포르투갈어, 스페인어, 힌디어, 태국어)를 공식 지원한다. 한국어는 공식 지원 언어에 포함되지 않는다.
할 수 있는 것
공식적으로는 요약, 지시 따르기, 텍스트 재작성, 도구 사용(tool use) 등이 주요 용도다. Meta 측에서는 "모바일 AI 어시스턴트, 엣지에서의 텍스트 분류, 대량 전처리 파이프라인"을 주요 유스케이스로 제시한다.
실사용자들의 평가는 좀 더 솔직하다. r/LocalLLaMA 커뮤니티에서는 "기본적인 텍스트 분류나 짧은 요약에는 쓸만하다"는 반응이 주류다. Ollama로 로컬에서 돌려본 사용자들은 "Q4 양자화로 2GB 정도면 돌아가니까, 라즈베리파이나 오래된 노트북에서도 쓸 수 있다"고 평가한다. Qualcomm과 MediaTek 하드웨어에서 직접 실행 가능하도록 최적화되어 있어, 실제 모바일 디바이스 배포 사례도 있다.
반면 "문서 요약이나 챗봇으로 쓰려면 한계가 명확하다"는 목소리도 강하다. Hugging Face 포럼에서는 "ChatGPT와 비교하면 문법 오류가 잦고, 지시를 제대로 따르지 않는 경우가 많다"는 분석이 올라왔다. 특히 "요약해줘"라는 단순한 지시도 가끔 무시한다는 보고가 있다. 3B라는 크기의 한계를 감안해야 하는 부분이다.
한국어 성능은 약하다. 공식 지원 언어에 한국어가 빠져 있고, 실사용에서도 "영문 표현이 섞여 나온다", "한국어 응답이 매끄럽지 않다"는 후기가 대부분이다. 한국어가 필요하면 Bllossom 팀이 150GB의 정제된 한국어 데이터로 추가 학습한 llama-3.2-Korean-Bllossom-3B를 쓰거나, Qwen 2.5 계열을 고려하는 것이 현실적이다.
성능
벤치마크 수치를 보면, 3B 크기대에서는 꽤 견고한 성능을 보여준다.
| 벤치마크 | 점수 | 비고 |
|---|---|---|
| MMLU | 63.4 | 일반 지식 (출처: 공식 모델 카드) |
| MMLU-PRO | 39.0 | 전문 지식 (출처: 공식 모델 카드) |
| GPQA | 32.8 | 대학원 수준 과학 (출처: 공식 모델 카드) |
| MATH Lvl 5 | 48.0 | 수학 추론 (출처: 공식 모델 카드) |
| IFEval | 77.4 | 지시 따르기 (출처: 공식 모델 카드) |
| GSM8K | 77.7 | 수학 문제풀이 (출처: 공식 모델 카드) |
| ARC-C | 78.6 | 과학 추론 (출처: 공식 모델 카드) |
| BFCL V2 | 67.0 | 함수 호출 (출처: 공식 모델 카드) |
IFEval 77.4는 경쟁 모델인 Gemma 2 2.6B(61.9)와 Phi-3.5-mini(59.2)를 크게 앞서는 수치다. 지시를 따르는 능력에서는 동급 최강이라 할 수 있다. MMLU 63.4도 Gemma 3 4B(59.6)를 앞서지만, Phi-4-mini(67.3)에는 뒤진다 (출처: localaimaster.com).
다만 벤치마크와 실사용 체감은 꽤 다르다는 목소리가 많다. "벤치마크 수치는 괜찮아 보이지만, 실제로 문서 Q&A나 요약을 시키면 소형 모델의 한계가 바로 드러난다"는 것이 중론이다. GPQA 32.8, MMLU-PRO 39.0이 보여주듯이 전문 지식 영역에서는 확실한 한계가 있다. 코딩 분야에서는 Phi-4-mini의 HumanEval 74.4에 비해 데이터가 공개되지 않아 직접 비교가 어렵다.
Artificial Analysis 기준 추론 속도는 평균 51.7 tokens/sec로, 3B 크기대에서는 준수한 편이다. TTFT(첫 토큰 생성 시간)는 0.83초 수준.

사용 방법
일반 사용자: Meta AI(meta.ai)에서 직접 사용하거나, Ollama를 설치해서 로컬에서 실행할 수 있다. Ollama 기준 ollama run llama3.2:3b 한 줄이면 된다. 양자화된 GGUF 포맷으로 약 2GB RAM이면 동작하므로, 4GB RAM 이상의 기기에서 무리 없이 실행 가능하다.
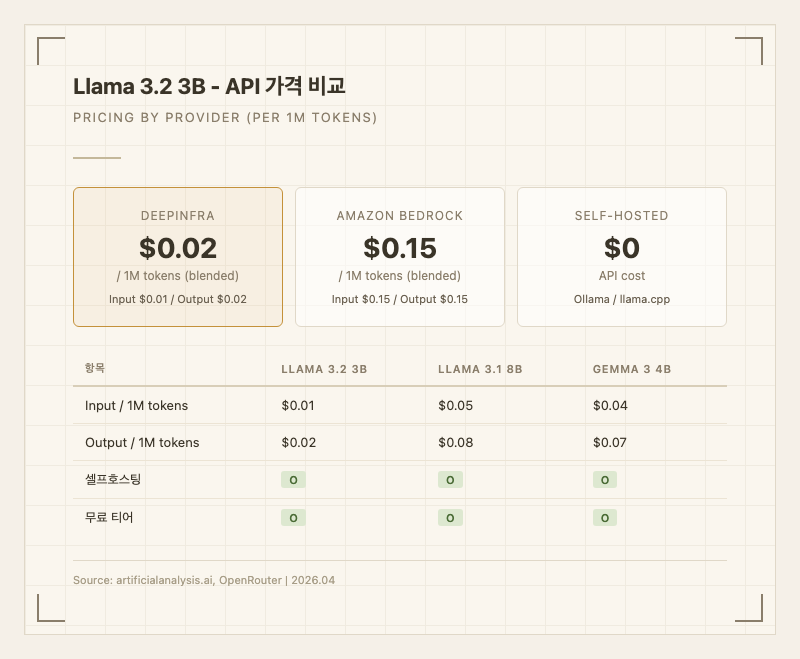
개발자: API로 사용하려면 DeepInfra, Amazon Bedrock, OpenRouter 등 다수 프로바이더를 통해 접근 가능하다. OpenAI 호환 API 형식을 지원하는 프로바이더가 많아서 기존 코드 변경 없이 모델만 교체할 수 있다. 셀프호스팅은 llama.cpp 또는 vLLM으로 가능하며, Hugging Face에서 가중치를 직접 다운로드할 수 있다.
공식 모델 카드: https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/MODEL_CARD.md
가격
오픈 웨이트 모델이므로 셀프호스팅 시 API 비용은 0이다. 클라우드 API를 통해 사용할 경우 프로바이더별 가격이 다른데, 가장 저렴한 DeepInfra 기준 입력 0.02/1M 토큰이다. OpenRouter에서는 무료 티어도 제공한다.
경쟁 모델과 비교하면, Llama 3.1 8B(입력 0.08)보다 5배 이상 저렴하고, Gemma 3 4B(입력 0.07)보다도 절반 이하다 (출처: artificialanalysis.ai). 실사용자들 사이에서는 "이 가격이면 대량 전처리에 부담 없이 쓸 수 있다"는 평가가 지배적이다.
한국어 토큰 효율 데이터는 미공개다. 다만 Llama 3 계열의 토크나이저(tiktoken 기반, 128K 어휘)는 한국어를 바이트 단위로 처리하는 경향이 있어, 같은 텍스트를 입력해도 영어 대비 2배에서 3배 정도 토큰을 더 소비하는 것으로 알려져 있다. 비용에 민감한 한국어 워크로드에서는 이 점을 감안해야 한다.
기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 수 | 3.21B (3,210M) |
| 아키텍처 | Transformer (Auto-regressive) |
| 어텐션 메커니즘 | Grouped Query Attention (GQA) |
| 컨텍스트 윈도우 | 128,000 tokens |
| 학습 데이터 | 9T tokens (공개 데이터) |
| 학습 기법 | Pruning + Knowledge Distillation |
| 학습 마감일 | 2023년 12월 |
| 출시일 | 2024년 9월 25일 |
| 라이선스 | Llama Community License |
| 지원 언어 | 영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 스페인어, 힌디어, 태국어 |
| 양자화 시 크기 | ~2GB (Q4_K_M GGUF) |
| 추론 속도 | ~52 tokens/sec (API 평균) |
Llama Community License는 상업적 사용을 허용하지만, 월간 활성 사용자 7억 명 이상의 서비스에서 사용하려면 Meta에 별도 라이선스를 요청해야 한다. 대부분의 기업과 개인 개발자에게는 사실상 제약이 없다.

참고 자료





스펙
컨텍스트 윈도우
128K 토큰
라이선스
Llama Community License
출시일
2024년 9월 25일
학습 마감일
2023년 12월 31일
가성비 지수
189.3
API 가격 (혼합)
입력 $0.010/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.01 / 1M 토큰
출력 (Completion)
$0.02 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
77.4
복잡한 지시사항 이해 및 수행
수학/추론
40.4
수학, 과학, 논리적 추론
일반지식
39.0
다양한 분야 지식 및 이해
Provider
Meta
분류
자연어 처리컴퓨터 비전오디오 처리TransformerSLM
성능 평가
LLM 종합 43.7
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1166.0 | elo |
| BBH | 0.5 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Llama 3.2 3B Instruct | 43.7 |
| Gemma 3 4B | 55.2 |