Llama 3 70B Instruct
MetaLLM자연어 처리컴퓨터 비전오디오 처리8K 토큰
2024년 4월 18일Meta Llama 3 Community License
Llama 3 70B Instruct는 Meta가 2024년 4월에 공개한 Llama 3 시리즈의 대형 모델이다. 70B(700억) 파라미터 규모의 디코더 전용 트랜스포머로, 대화 및 지시 수행에 최적화된 Instruct 버전이다. 출시 당시 오픈소스 LLM 중 가장 높은 성능을 기록하며, GPT-3.5 Turbo를 넘어서고 GPT-4 초기 버전에 근접하는 성능을 오픈 가중치로 제공한다는 점에서 큰 주목을 받았다.
주요 특징
Llama 3 70B Instruct의 가장 큰 차별점은 오픈소스 70B 모델 중 최초로 상용 모델급 성능에 도달했다는 점이다. LMSYS Chatbot Arena에서 GPT-4와 동률로 1위를 기록한 바 있다.
첫째, 15조(15T) 토큰이라는 방대한 학습 데이터를 사용했다. Llama 2 대비 7배 규모이며, 코드 데이터는 4배 증가했다. 이 대규모 학습이 모델의 전반적인 품질을 끌어올린 핵심 요인이다.
둘째, 128K 어휘 크기의 tiktoken 기반 BPE 토크나이저를 새로 도입했다. Llama 2의 sentencepiece(32K) 대비 4배 큰 어휘 사전 덕분에 토큰 효율이 크게 개선됐다. 특히 비영어권 언어에서의 토큰 압축률이 2~3배 향상되어, 한국어 처리 효율도 이전 세대 대비 눈에 띄게 나아졌다.
셋째, Grouped Query Attention(GQA) 아키텍처를 채택해서 추론 속도가 빠르다. DeepInfra 기준 초당 45.9토큰, Replicate 기준 41.4토큰의 출력 속도를 보여준다. 같은 파라미터 규모의 다른 모델 대비 효율적인 추론이 가능하다.
넷째, Meta Llama 3 Community License 하에 가중치를 완전 공개했다. 상업적 사용이 가능하고, 파인튜닝도 자유롭다. 이 때문에 수많은 커뮤니티 파인튜닝 변형 모델(예: Korean Bllossom 70B, Llama 3 Instruct Gradient 등)의 베이스 모델이 됐다.
실사용자들의 반응을 보면, "포맷 지시를 잘 따른다", "과도한 프롬프트 엔지니어링 없이도 원하는 형태로 출력을 잘 뽑아준다"는 평가가 많다. 반면 "가끔 이모티콘을 과도하게 사용한다", "영어 이외 언어에서는 성능 격차가 있다"는 지적도 있다.

할 수 있는 것
Meta는 공식적으로 12개 핵심 유스케이스를 제시한다: 조언 요청, 브레인스토밍, 분류, 폐쇄형 질의응답, 코딩, 창작 글쓰기, 정보 추출, 페르소나 연기, 개방형 질의응답, 추론, 리라이팅, 요약이다. 이 모든 항목에서 Claude Sonnet, Mistral Medium, GPT-3.5를 넘어서는 성능을 보였다고 한다 (출처: 공식 블로그).
실사용자들이 검증한 강점은 다음과 같다:
코딩 보조 도구로서 실용적이다. 간단한 함수 작성, 디버깅 힌트, 코드 리뷰 등에서 쓸만하다는 평가가 많다. 다만 복잡한 버그 수정이나 대규모 코드베이스를 다루는 작업에서는 코드 문법 오류가 발생하거나 잘못된 코드를 생성하는 경우가 보고됐다.
요약과 분류 작업에서 가성비가 좋다. GPT-4 대비 최대 50배 저렴하면서도 10배 빠르기 때문에, 대량의 텍스트를 분류하거나 요약하는 배치 작업에서 특히 효과적이다 (출처: Vellum AI 비교 분석).
초등 수준 수학 문제, 산술 추론에서는 잘 작동하지만, 중학교 이상 난이도의 수학 문제에서는 정확도가 떨어진다. 수학이 핵심 유스케이스라면 GPT-4 계열이 더 적합하다.
멀티모달은 지원하지 않는다. 이미지를 보거나 처리하는 기능이 없으므로, 비전 작업이 필요하면 GPT-4V나 Gemini Pro를 사용해야 한다.
논리 퍼즐(트롤리 문제 변형 등)에서 추론 갭이 드러나는 경우가 있다. 복잡한 다단계 추론보다는 직관적인 지시 수행에 더 강하다.
성능
벤치마크 수치를 보면, MMLU 82.0으로 범용 지식에서 준수한 성능을 보인다 (출처: Meta 공식 모델 카드). IFEval 77.6으로 지시 수행 능력이 높은 편이다. MATH Lvl 5에서 68.0을 기록해 수학적 추론 역량도 보여준다. 그러나 GPQA 46.7(대학원 수준 과학 문제)과 MMLU-PRO 56.2(전문 지식 심화)에서는 한계가 드러난다. BBH(복합 추론) 65.5, MUSR(멀티스텝 추론) 41.5로, 고난도 추론에서는 상용 모델과 격차가 있다 (출처: artificialanalysis.ai).
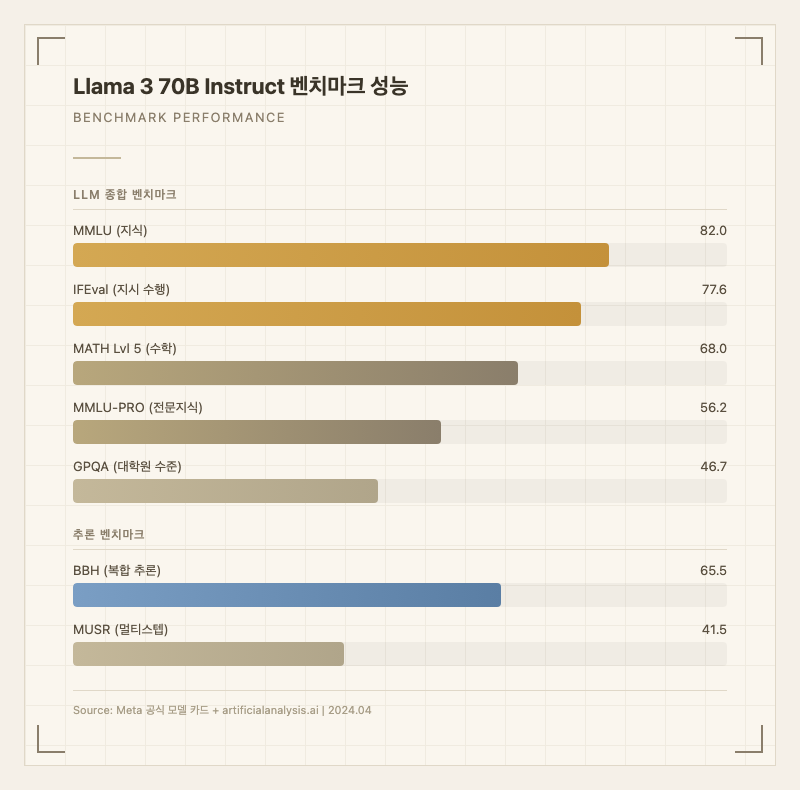
Artificial Analysis의 종합 평가에서는 Intelligence Index 10점(100점 기준 추정)으로, 같은 크기의 오픈 모델 중에서는 발매 당시 최상위였지만, 2024년 하반기에 나온 후속 모델들(Llama 3.1 70B, Llama 3.3 70B)에 의해 빠르게 추월당했다.
경쟁 모델과의 실사용 비교에서, GPT-4o mini가 수학(86%)과 분류(72%)에서 더 높은 정확도를 보였고, Llama 3 70B는 수학 64%, 분류에서도 뒤처졌다 (출처: Vellum AI 평가). 반면 출력 속도에서는 초당 250토큰(Llama 3.1 70B 기준)으로 GPT-4o mini(103토큰), Claude 3.5 Haiku(128토큰)를 크게 앞선다.
실사용자 체감으로는, "벤치마크 숫자보다 실제 대화 품질이 나은 편"이라는 평가가 많다. Chatbot Arena에서 GPT-4와 동률을 기록한 것이 이를 뒷받침한다. 다만 "환각(hallucination)이 가끔 발생한다", "긴 대화에서 맥락을 놓치는 경우가 있다"(8K 컨텍스트의 한계)는 단점도 보고된다.
사용 방법
Llama 3 70B Instruct는 오픈 가중치 모델이므로 여러 경로로 사용할 수 있다.
일반 사용자는 Meta AI(meta.ai)에서 직접 대화할 수 있다. HuggingFace의 모델 페이지(huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct)에서도 Inference API를 통해 테스트 가능하다. Ollama나 llama.cpp를 사용하면 로컬 환경에서도 실행할 수 있지만, 70B 모델은 약 40GB의 VRAM이 필요하므로 RTX 6000 Ada급 GPU 2장 이상이 권장된다.
개발자는 OpenRouter, Together AI, DeepInfra, Amazon Bedrock, Azure AI 등 다양한 API 제공업체를 통해 접근할 수 있다. OpenRouter의 경우 OpenAI 호환 API를 제공하므로, 기존 OpenAI SDK 코드에서 모델명과 엔드포인트만 바꾸면 바로 사용 가능하다.
가격
API 호출 비용은 제공업체마다 다르다. OpenRouter 기준 입력 0.74/1M 토큰이다. Artificial Analysis 집계 평균은 입력 1.75로 다소 높게 나타난다 (출처: artificialanalysis.ai).
GPT-4 Turbo(입력 30)나 Claude 3 Sonnet(입력 15) 대비 압도적으로 저렴하다. 실사용자들은 "GPT-4 대비 50배 싸면서 쓸만한 품질"이라는 가성비 평가를 많이 내린다.
다만 후속 모델과 비교하면 가격 경쟁력이 떨어진다. Llama 3.1 70B(입력 0.40)가 더 싸고 성능도 좋으며, Llama 3.3 70B(입력 0.32)는 가격이 5분의 1 수준이면서 대폭 향상된 성능을 제공한다. 새 프로젝트에서 Llama 3 70B를 선택할 가격적 이유는 거의 없다.
한국어 토큰 효율은 Llama 2 대비 2~3배 개선됐다. 128K 어휘의 tiktoken 토크나이저 도입으로 한국어 텍스트의 토큰 수가 크게 줄었다. Bllossom 팀이 만든 Korean Bllossom 70B는 3만 개 이상의 한국어 어휘를 추가해서 표준 Llama 3 대비 약 25% 더 긴 한국어 컨텍스트를 처리할 수 있다. 다만 기본 Llama 3 70B의 정확한 한국어 토큰 효율 수치(동일 텍스트 기준 토큰 수 비교)는 공식 미공개 상태다.

기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 | 70B (700억) |
| 아키텍처 | Decoder-only Transformer + Grouped Query Attention (GQA) |
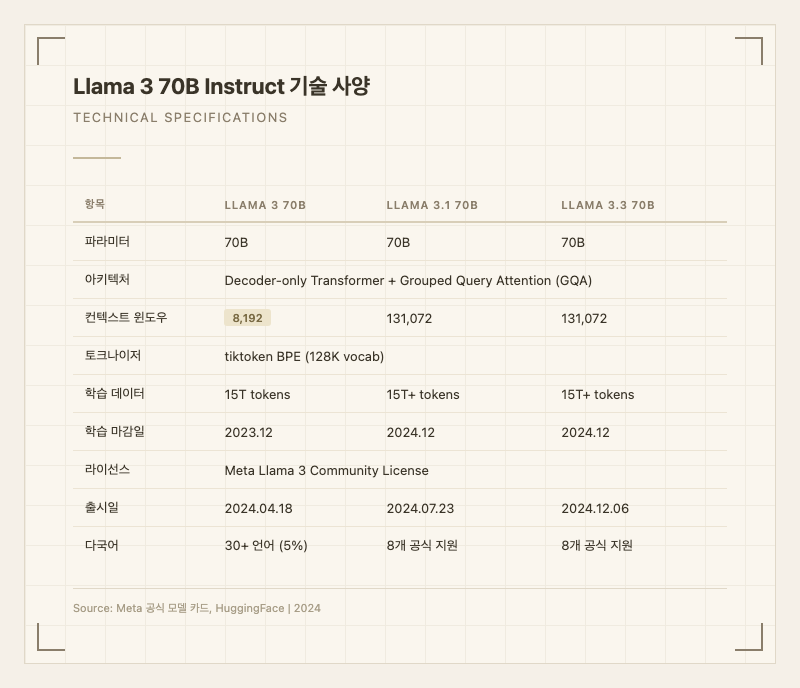
| 컨텍스트 윈도우 | 8,192 토큰 |
| 토크나이저 | tiktoken BPE (128K vocab) |
| 학습 데이터 | 15조(15T) 토큰, 공개 소스 기반 |
| 학습 마감일 | 2023년 12월 |
| 라이선스 | Meta Llama 3 Community License |
| 출시일 | 2024년 4월 18일 |
| 다국어 | 30개 이상 언어 (학습 데이터의 5%) |
| 파인튜닝 데이터 | 공개 지시 데이터셋 + 1,000만 건 이상 인간 주석 |
| GPU 요구사항 | 약 40GB VRAM (FP16 기준) |
| 주요 제공업체 | OpenRouter, DeepInfra, Together AI, Amazon Bedrock, Azure AI |
8,192 토큰이라는 컨텍스트 윈도우는 현재 기준으로 상당히 짧다. 후속 모델인 Llama 3.1과 3.3이 131,072 토큰을 지원하는 것과 대조적이다. 긴 문서 처리나 복잡한 대화가 필요하면 후속 모델을 사용하는 것이 맞다.
학습 마감일이 2023년 12월이므로, 2024년 이후의 사건이나 정보에 대해서는 답변할 수 없다. 이 점도 후속 모델(학습 마감일 2024년 12월)과의 차이다.
Llama 3 70B Instruct는 오픈소스 LLM 역사에서 이정표적인 모델이다. 최초로 상용 모델급 성능을 오픈 가중치로 달성했고, 파인튜닝 생태계의 폭발적 성장을 이끌었다. 하지만 2024년 하반기부터 나온 후속 모델들(Llama 3.1, 3.3)이 모든 면에서 더 나은 성능과 긴 컨텍스트, 낮은 가격을 제공하므로, 새 프로젝트에는 Llama 3.3 70B를 권장한다. 기존 Llama 3 파이프라인과의 호환성이 필요하거나, Llama 3 기반 파인튜닝 모델을 유지보수하는 경우에만 이 모델을 선택하면 된다.
참고 자료






스펙
컨텍스트 윈도우
8K 토큰
라이선스
Meta Llama 3 Community License
출시일
2024년 4월 18일
학습 마감일
2023년 12월 31일
가성비 지수
4.7
API 가격 (혼합)
입력 $0.510/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.51 / 1M 토큰
출력 (Completion)
$0.74 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
77.6
복잡한 지시사항 이해 및 수행
수학/추론
57.4
수학, 과학, 논리적 추론
일반지식
56.2
다양한 분야 지식 및 이해
Provider
Meta
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 58.7
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| BBH | 0.7 | % |
| GPQA | 46.7 | % |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Llama 3 70B Instruct | 58.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |