Llama 4 Maverick
MetaLLM자연어 처리컴퓨터 비전오디오 처리1.0M 토큰
2025년 4월 6일Llama Community License
Llama
4 Maverick이란
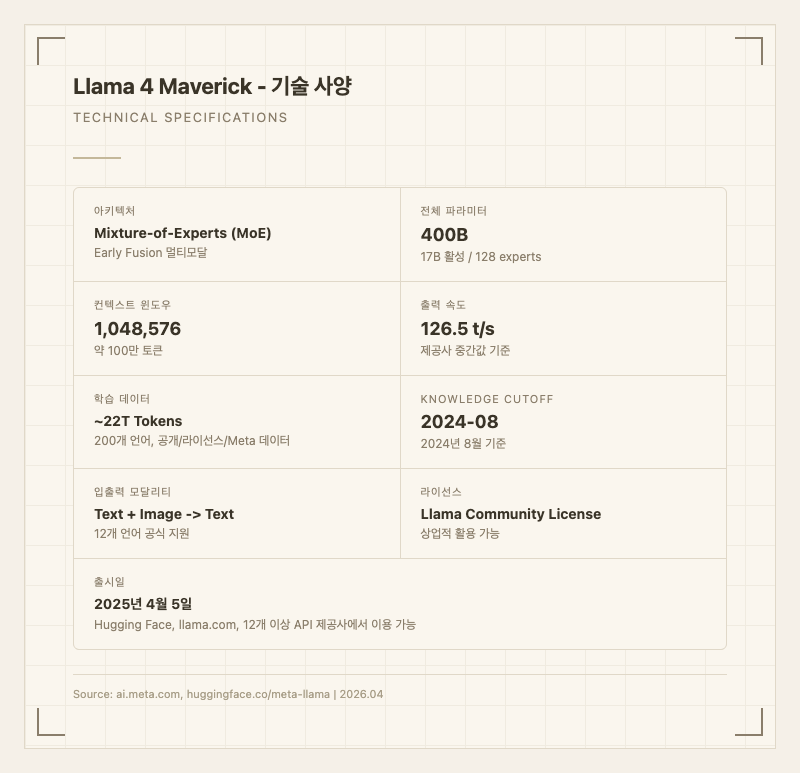
Llama 4 Maverick은 Meta가 2025년 4월 5일에 공개한 400B 규모의 Mixture-of-Experts(MoE) 기반 대규모 멀티모달 언어 모델이다. 128개의 전문가(expert) 중 추론 시 1개만 활성화하는 구조로, 실제 사용되는 파라미터는 17B에 불과하다. 400B급 모델의 지식 용량을 유지하면서도 소형 모델 수준의 추론 비용으로 운용할 수 있다는 것이 핵심 설계 철학이다. Llama 시리즈 최초로 MoE 아키텍처를 채택했으며, Early Fusion 방식의 네이티브 멀티모달을 지원해 텍스트와 이미지 입력을 동시에 처리한다. Llama Community License 하에 오픈 웨이트로 공개되어 상업적 활용과 파인튜닝이 모두 가능하다.
주요 특징
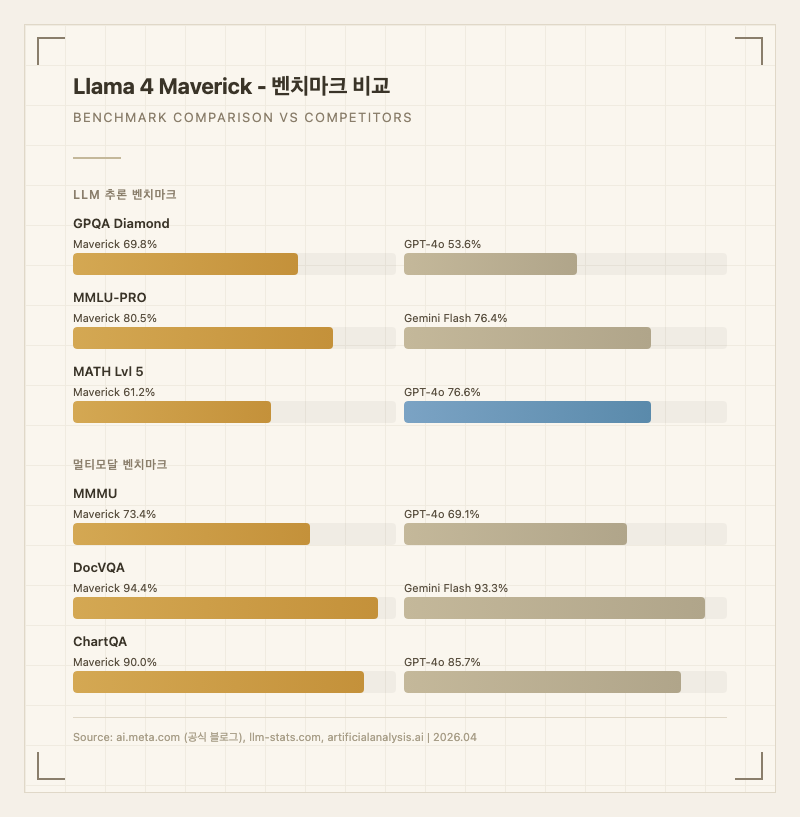
Llama 4 Maverick의 가장 눈에 띄는 차별점은 MoE 아키텍처가 만들어내는 효율성이다. 400B 전체 파라미터 중 17B만 활성화하면서도, GPQA Diamond 69.8%, MMLU-PRO 80.5% 같은 수치를 기록한다 (출처: 공식 블로그). 같은 클래스의 GPT-4o나 Gemini 2.0 Flash보다 대부분의 벤치마크에서 앞서면서, API 비용은 GPT-4o 대비 91~94% 저렴하다. 이 가격 대 성능 비율이 Maverick의 핵심 경쟁력이다.
두 번째는 1M(100만) 토큰 컨텍스트 윈도우다. 전체 코드베이스나 수백 페이지 분량의 문서를 한 번에 넣을 수 있다. 다만 실사용자들은 10,000~20,000 토큰을 넘어가면 품질이 눈에 띄게 떨어진다고 보고하고 있어, 공칭 수치와 실제 유효 범위 사이에 괴리가 있다.
세 번째 특징은 한국어 토큰 효율이다. SK DevOcean의 분석에 따르면, Llama 4 토크나이저는 한국어 171자를 76토큰으로 처리하여 약 2.2자/토큰의 효율을 보인다. 이는 Llama 3의 93토큰에서 18% 개선된 수치이며, OpenAI의 o200k_base(88토큰)보다도 효율적이다. 한국어 특화 모델인 SKT A.X(약 60토큰)보다는 약 30% 더 토큰을 사용하지만, 다국어 범용 모델 중에서는 최고 수준이다 (출처: devocean.sk.com).
네 번째로 출력 속도가 빠르다. 제공사 중간값 기준 126.5 tokens/sec로, 동급 오픈소스 모델 중간값(55.4 t/s)의 2배 이상이다 (출처: artificialanalysis.ai). TTFT(첫 토큰 생성 시간)도 0.95초로 경쟁력 있다.

할 수 있는 것
Maverick은 범용 어시스턴트로 설계되었지만, 실사용자들의 평가는 용도에 따라 극명하게 갈린다.
가장 좋은 평가를 받는 영역은 창작 글쓰기다. 한 리뷰어는 "오픈 웨이트 모델 중 최고의 범용 어시스턴트"라고 평가하면서, 특히 소설 쓰기에서 장르별로 적절한 내러티브 보이스를 구현한다고 언급했다 (출처: awesomeagents.ai). 문서 이해 측면에서도 DocVQA 94.4%, ChartQA 90.0%라는 높은 점수가 보여주듯, 문서에서 정보를 추출하거나 차트를 분석하는 작업에서 강점을 보인다 (출처: llm-stats.com).
반면 코딩 작업에서는 평가가 엇갈린다. MBPP 77.6%, LiveCodeBench 43.4%로 코딩 벤치마크 자체는 준수하지만, aider polyglot 코딩 벤치마크에서 16%라는 저조한 성적이 보고되었다 (출처: monica.im/blog). Reddit에서도 한 사용자는 코딩 작업에서 "abysmal(처참한)" 수준이라고 평가했다. 코딩에 Maverick을 쓰려면 단순한 코드 생성보다는 코드 리뷰나 설명 용도가 더 적합하다는 것이 커뮤니티 의견이다.
이미지 이해 능력은 MMMU 73.4%(GPT-4o 69.1% 대비 우세), MathVista 73.7%로 수학 문제가 포함된 시각 자료도 처리할 수 있다 (출처: 공식 블로그). 다국어 처리는 200개 언어로 사전 학습되었으나, 파인튜닝 지원은 12개 언어로 제한되며 한국어는 공식 파인튜닝 지원 언어에 포함되지 않는다.
긴 문맥 요약 작업에서는 Simon Willison의 테스트에서 Hacker News 스레드 요약 시 합리적인 결과를 보여줬으나, Gemini 2.5 Pro에 비해서는 품질과 분량 모두 뒤처졌다 (출처: simonwillison.net). 특히 긴 Reddit 스레드 요약에서는 루핑과 환각 현상이 발생한다는 보고도 있었다.
성능
| 벤치마크 | Maverick | 비교 모델 | 출처 |
|---|---|---|---|
| GPQA Diamond | 69.8% | GPT-4o 53.6% | 공식 블로그 |
| MMLU-PRO | 80.5% | Gemini 2.0 Flash 76.4% | 공식 블로그 |
| MATH Lvl 5 | 61.2% | GPT-4o 76.6% | llm-stats.com |
| MMLU | 85.5% | - | llm-stats.com |
| MMMU | 73.4% | GPT-4o 69.1% | 공식 블로그 |
| MMMU-Pro | 59.6% | - | llm-stats.com |
| DocVQA | 94.4% | Gemini 2.0 Flash 93.3% | 공식 블로그 |
| ChartQA | 90.0% | GPT-4o 85.7% | 공식 블로그 |
| MathVista | 73.7% | GPT-4o 63.8% | 공식 블로그 |
| LiveCodeBench | 43.4% | - | llm-stats.com |
| MBPP | 77.6% | - | llm-stats.com |
| MGSM (다국어 수학) | 92.3% | - | llm-stats.com |
| Multilingual MMLU | 84.6% | - | 공식 블로그 |
| Arena Elo (실험 버전) | 1417 | - | LMArena |
벤치마크만 보면 GPQA, MMLU-PRO, 멀티모달 영역에서 GPT-4o와 Gemini 2.0 Flash를 확실히 앞서는 모습이다. 하지만 MATH Lvl 5에서는 61.2%로 GPT-4o(76.6%)에 크게 뒤처지며, 수학 추론이 약점임을 드러낸다.
실사용 체감은 벤치마크와 상당한 괴리가 있다. Artificial Analysis의 Intelligence Index에서 18점을 기록해 동급 모델 중간값(20)보다 낮게 평가받았다 (출처: artificialanalysis.ai). LMSYS Arena에서는 실험 버전이 1417 ELO를 기록했지만, 이 실험 버전이 공개 배포 버전과 다르다는 논란이 있었다. 연구자 Daniel Lemire는 "Arena에서 1위인 Llama 4 모델은 Meta가 공개한 모델과 다르다"고 지적했다 (출처: InfoQ). 커뮤니티에서는 "벤치마크 게이밍" 의혹이 제기되었고, Meta는 이후 "버그 때문"이라고 해명했다 (출처: VentureBeat).
한 마디로 정리하면: 벤치마크 수치는 인상적이지만, 실제 사용 시 벤치마크만큼의 성능을 체감하기 어렵다는 평가가 지배적이다. 특히 코딩과 긴 문맥 처리에서 이 괴리가 크게 나타난다.
사용 방법Maverick은 여러 경로로 사용할 수 있다.
일반 사용자의 경우 Meta AI(meta.ai)에서 직접 대화형으로 사용할 수 있다. Instagram, WhatsApp, Facebook Messenger에서도 Meta AI 어시스턴트를 통해 Llama 4 기반 응답을 받을 수 있다.
개발자의 경우 Hugging Face에서 모델 웨이트를 직접 다운로드할 수 있다(meta-llama/Llama-4-Maverick-17B-128E-Instruct). API로는 Together AI, Fireworks, Groq, Amazon Bedrock, Google Cloud Vertex AI, Azure 등 12개 이상의 제공사에서 접근 가능하다. 제공사별로 컨텍스트 윈도우 제한이 다른데, Fireworks는 1.05M 토큰, Together는 524K 토큰을 지원한다.
자체 인프라 배포도 가능하지만, 400B MoE 모델 특성상 소비자급 GPU에서는 구동이 불가능하다. Jeremy Howard는 "양자화를 해도 소비자 GPU에서 돌릴 수 없는 거대 MoE"라고 언급했다 (출처: simonwillison.net).
가격
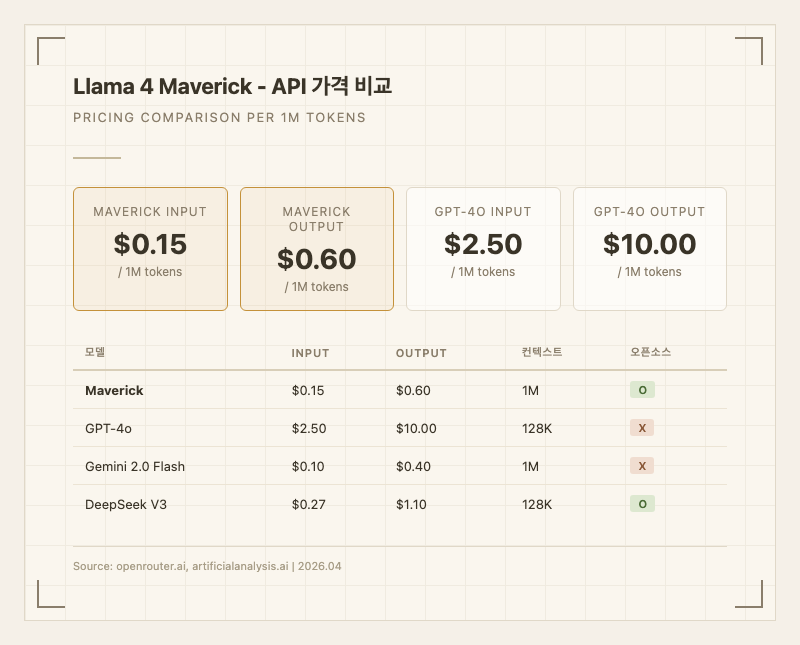
Maverick의 API 가격은 입력 0.60/1M 토큰이다 (최저가 기준). 이는 GPT-4o(입력 10.00)와 비교하면 입력 94%, 출력 94% 저렴한 수준이다. 제공사별 중간값은 입력 0.91/1M 토큰이다 (출처: artificialanalysis.ai).
셀프 호스팅 시 분산 추론 기준 약 0.30~$0.49/Mtok으로 추산된다.
같은 오픈소스 경쟁자인 DeepSeek V3(입력 1.10)보다 저렴하지만, Gemini 2.0 Flash(입력 0.40)보다는 약간 비싸다. 다만 Gemini Flash는 오픈소스가 아니므로 셀프 호스팅이 불가능하다는 차이가 있다.
한국어 토큰 효율을 고려하면 실질 비용이 달라진다. Llama 4는 171자를 76토큰으로 처리하므로, GPT-4o의 토큰당 비용이 높은 데다 토큰 효율까지 불리하면 실질 한국어 처리 비용 차이는 더 벌어진다. 반면 Gemini Flash와의 비교에서는 Gemini가 가격은 더 싸지만 한국어 토큰 효율 데이터가 공개되지 않아 직접 비교가 어렵다.
커뮤니티에서는 "가격 대비 성능은 확실히 매력적"이라는 평가와 "싼 게 비지떡"이라는 평가가 공존한다. 코딩 용도로 쓸 거라면 DeepSeek V3가 가성비가 더 좋고, 범용 어시스턴트 용도라면 Maverick의 가격 경쟁력이 돋보인다는 것이 대체적인 의견이다.
기술 사양
| 항목 | 사양 |
|---|---|
| 아키텍처 | Mixture-of-Experts (MoE), Early Fusion 멀티모달 |
| 전체 파라미터 | 400B (17B 활성, 128 experts) |
| 컨텍스트 윈도우 | 1,048,576 토큰 (약 1M) |
| 출력 속도 | 126.5 tokens/sec (제공사 중간값) |
| TTFT | 0.95초 (제공사 중간값) |
| 학습 데이터 | ~22조 토큰, 200개 언어 |
| Knowledge Cutoff | 2024년 8월 |
| 입력 모달리티 | 텍스트 + 이미지 |
| 출력 모달리티 | 텍스트 (12개 언어 공식 지원) |
| 라이선스 | Llama Community License (상업적 활용 가능) |
| 출시일 | 2025년 4월 5일 |
| API 가격 | 입력 0.60 per 1M tokens |
학습에는 공개 데이터, 라이선스 데이터, Meta 플랫폼 데이터가 혼합되었으며, Llama 3 대비 다국어 토큰이 10배 증가했다. 파인튜닝 공식 지원 언어는 아랍어, 영어, 프랑스어, 독일어, 힌디어, 인도네시아어, 이탈리아어, 포르투갈어, 스페인어, 타갈로그어, 태국어, 베트남어 12개이며, 한국어는 사전 학습에는 포함되나 공식 파인튜닝 지원 대상은 아니다.
참고 자료




스펙
컨텍스트 윈도우
1.0M 토큰
라이선스
Llama Community License
출시일
2025년 4월 6일
학습 마감일
2024년 8월 31일
가성비 지수
11.8
API 가격 (혼합)
입력 $0.150/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.15 / 1M 토큰
출력 (Completion)
$0.60 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
일반지식최강
80.5
다양한 분야 지식 및 이해
멀티모달
73.4
이미지, 비디오 등 멀티모달 이해
수학/추론
65.5
수학, 과학, 논리적 추론
Provider
Meta
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 70.5
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1417.0 | elo |
| GPQA | 69.8 | % |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Llama 4 Maverick | 70.5 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |