Llama 3.3 70B Instruct
MetaLLM자연어 처리컴퓨터 비전오디오 처리128K 토큰
2024년 12월 6일Llama Community License
Llama
3.3 70B Instruct란?
Meta가 2024년 12월 6일에 공개한 700억 파라미터 규모의 오픈 웨이트 대형 언어 모델이다. Llama 3.1 70B의 후속 모델로, 동일한 70B 파라미터 크기를 유지하면서도 Llama 3.1 405B에 근접하는 성능을 달성했다. 텍스트 입출력 전용 모델이며, 영어를 포함한 8개 언어를 공식 지원한다. Llama Community License로 상업적 사용이 가능하고, 15조 개 이상의 토큰으로 학습되었다.
주요 특징
Llama 3.3 70B의 가장 눈에 띄는 점은 "작은 모델로 큰 모델의 성능을 낸다"는 것이다. Databricks 측 테스트에 따르면 Llama 3.1 405B 대비 배포 비용이 88% 절감되면서도 벤치마크 성능은 거의 동일하다 (출처: Helicone 블로그). 405B 모델을 돌리려면 8장의 80GB GPU가 필요하지만, 3.3 70B는 2장의 48GB GPU면 충분하다. 이건 실무에서 서버 비용 차이가 몇 배 나는 수준이다.
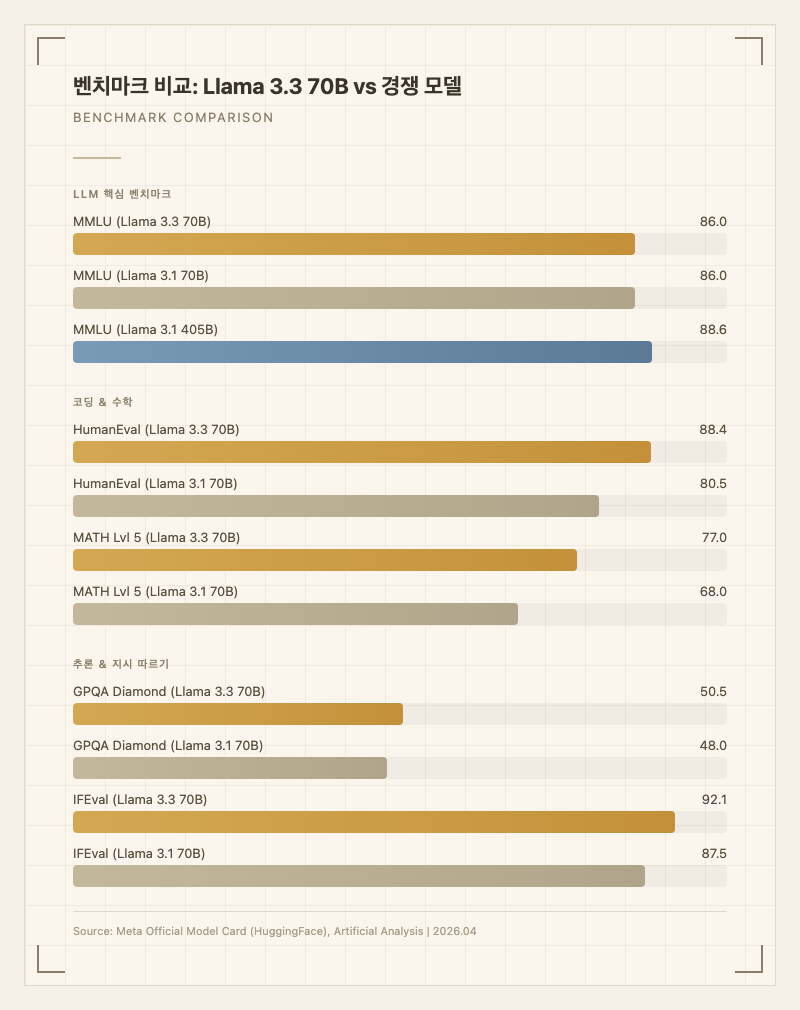
코딩 능력이 전작 대비 크게 올랐다. HumanEval 88.4% (3.1 70B는 80.5%), MATH Lvl 5는 77.0% (3.1 70B는 68.0%)로 수학과 코드 양쪽에서 눈에 띄게 향상됐다 (출처: Meta 공식 모델 카드). IFEval(지시 따르기) 역시 92.1%로 3.1 70B의 87.5%에서 4.6%p 올랐다. 실사용자들도 "코드 생성 품질이 확실히 좋아졌다"는 반응이 많다.
Groq 하드웨어 기준 초당 276토큰의 추론 속도를 보이며, 이는 Llama 3.1 70B보다 초당 25토큰 더 빠르다 (출처: Helicone 블로그). Grouped-Query Attention(GQA) 아키텍처가 추론 효율성에 기여하고 있다.
128K 토큰 컨텍스트 윈도우를 지원하여 약 400페이지 분량의 텍스트를 한 번에 처리할 수 있다. 이는 Llama 3.1 405B와 동일한 수준이다.

할 수 있는 것
실제 사용자들의 후기를 종합하면, Llama 3.3 70B가 잘하는 영역과 한계가 비교적 명확하다.
잘하는 것부터 보면, 코드 생성이 가장 강점이다. HumanEval 88.4%는 Python 100문제 중 88문제를 첫 시도에 맞힌다는 뜻인데, GPT-3.5의 48%와 비교하면 거의 2배다 (출처: Meta 공식 모델 카드). 실제로 개발자 커뮤니티에서 "소비자용 노트북에서 로컬로 돌려도 쓸 만한 코드를 뽑아낸다"는 보고가 있다 (출처: Helicone 블로그).
다국어 대화에서도 MGSM(다국어 수학) 91.1%를 기록하며, 영어 외 7개 언어에서 안정적인 성능을 보인다 (출처: Meta 공식 모델 카드). 다만 공식 지원 언어에 한국어는 포함되지 않는다. 한국어로도 기본적인 대화는 가능하지만, 영어 대비 품질 차이가 있다는 것이 커뮤니티 공통 의견이다. 한국어 특화가 필요하면 Bllossom 같은 한국어 파인튜닝 버전이 별도로 존재한다.
Tool Use / 함수 호출은 BFCL v2에서 77.3%로 양호한 수준이다 (출처: Meta 공식 모델 카드). API 연동이나 에이전트 파이프라인에 넣어 쓸 수 있는 수준이지만, GPT-4o나 Claude 대비 안정성이 떨어진다는 피드백이 있다.
안 되는 것도 명확하다. 이미지나 오디오 처리는 불가능하다. 텍스트 전용 모델이므로, 멀티모달이 필요하면 Llama 3.2 Vision 계열을 써야 한다. Knowledge cutoff가 2023년 12월이라 최신 정보에 대한 답변은 불가능하다. 또한 일부 사용자는 "에이전틱 코딩(코드베이스를 자동으로 읽고 수정하는 작업)에서는 아직 부족하다"는 의견을 냈다 (출처: LogRocket 블로그).
성능벤치마크 수치를 먼저 보면:
| 벤치마크 | Llama 3.3 70B | Llama 3.1 70B | Llama 3.1 405B |
|---|---|---|---|
| MMLU | 86.0 | 86.0 | 88.6 |
| MMLU-PRO | 68.9 | 66.4 | - |
| GPQA Diamond | 50.5 | 48.0 | - |
| HumanEval | 88.4 | 80.5 | 89.0 |
| MATH Lvl 5 | 77.0 | 68.0 | - |
| IFEval | 92.1 | 87.5 | - |
| MBPP EvalPlus | 87.6 | 86.0 | - |
| MGSM (다국어) | 91.1 | 86.9 | - |
(출처: Meta 공식 모델 카드, HuggingFace)
숫자만 보면 3.1 70B 대비 전 영역에서 향상되었고, 특히 코딩(HumanEval +7.9%p)과 수학(MATH +9%p)에서 점프가 크다. MMLU는 86.0으로 동일한데, 이건 이미 높은 수준이라 더 올리기 어려운 영역이다.
하지만 실사용 체감은 벤치마크와 항상 일치하지 않는다. 커뮤니티 의견을 종합하면:
- 코딩에서는 확실히 체감 차이가 있다. 3.1 70B로는 에러가 나던 코드가 3.3에서는 한 번에 되는 경우가 늘었다.
- 추론 능력(GPQA 50.5)은 Claude 3.5 Sonnet(59.4)에 비하면 여전히 격차가 있다. 대학원 수준 과학 문제에서는 클로즈드소스 모델에 밀린다 (출처: Analytics Vidhya).
- MMLU-PRO 68.9 역시 Claude 3.5 Sonnet의 78.0에 한참 못 미친다. 전문 지식 영역에서는 확실한 차이가 있다.
- Artificial Analysis 인텔리전스 인덱스에서 38개 모델 중 14위를 기록했다 (출처: artificialanalysis.ai). 오픈소스 모델 중에서는 상위권이지만, 전체로 보면 중간 수준이다.
- 속도는 빠르지만 출력이 다소 장황하다는 평가도 있다. 동일 질문에 대해 Claude나 GPT-4o보다 토큰을 더 많이 생성하는 경향이 있다 (출처: artificialanalysis.ai).
사용 방법
Llama 3.3 70B는 오픈소스 모델이므로, 접근 경로가 다양하다.
일반 사용자라면 HuggingFace Chat(huggingface.co/chat)이나 Groq의 GroqCloud Playground에서 무료로 사용해 볼 수 있다. 별도 설치 없이 웹 브라우저에서 바로 대화가 가능하다.
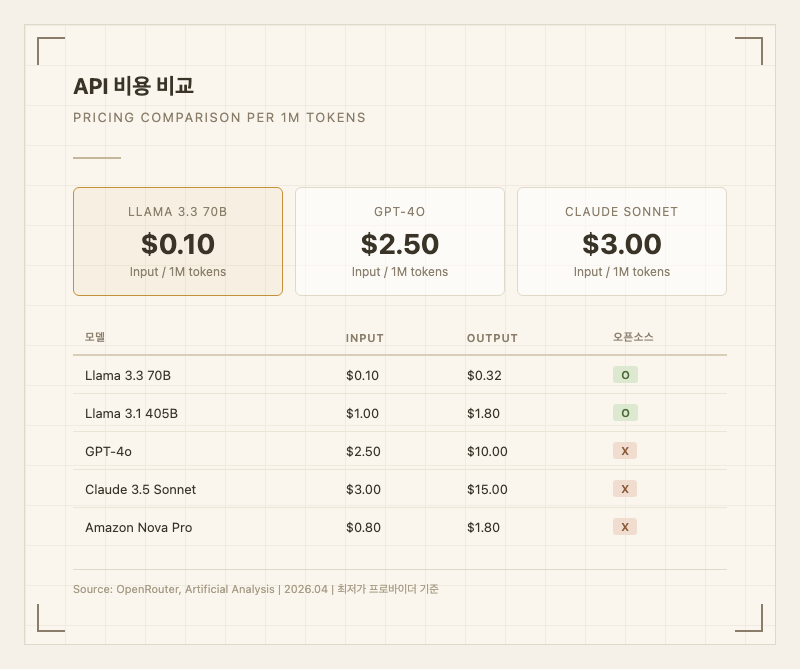
개발자라면 API를 통한 접근이 편리하다. OpenRouter, Together AI, DeepInfra, Fireworks AI 등 다수의 서드파티 호스팅 프로바이더에서 Llama 3.3 70B API를 제공한다. OpenRouter 기준 입력 0.32/1M으로 이용 가능하다. AWS Bedrock, Azure AI, Oracle OCI, IBM watsonx 등 주요 클라우드 플랫폼에서도 제공된다.
로컬 실행을 원하면, HuggingFace에서 모델 웨이트를 직접 다운로드하여 vLLM, Ollama, llama.cpp 등으로 서빙할 수 있다. FP16 기준 약 140GB VRAM이 필요하며 (48GB GPU 2장), 4비트 양자화 적용 시 단일 GPU에서도 실행 가능하다. 공식 모델 페이지: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
가격Llama 3.3 70B의 최대 장점 중 하나가 가격이다.
API 호스팅 프로바이더 기준, 최저가는 DeepInfra에서 입력/출력 모두 0.24, 출력 0.58, 출력 $0.71/1M 토큰이다.
경쟁 모델과 비교하면 격차가 크다. GPT-4o는 입력 10.00/1M으로 Llama 3.3 대비 2530배 비싸다. Claude 3.5 Sonnet은 입력 15.00/1M으로 더 비싸다. 같은 오픈소스인 Llama 3.1 405B도 입력 1.80/1M으로 3.3 70B보다 510배 비싸다. 실사용자들 사이에서 "가성비 끝판왕"이라는 평가가 나오는 이유다.
셀프 호스팅하면 API 비용이 0이 된다. 48GB VRAM GPU 2장(예: A6000 또는 RTX 6000 Ada)이면 FP16으로 서빙 가능하고, 4비트 양자화 시 24GB GPU 1장에서도 돌아간다. 온프레미스 배포가 필요한 기업에게는 TCO 측면에서 매우 유리하다.
한국어 토큰 효율 데이터는 미공개 상태다. Llama 3 계열은 tiktoken 기반 128K 보캡 토크나이저를 사용하는데, 한국어는 공식 지원 언어가 아니라서 영어 대비 토큰 소비가 더 많을 수 있다. 한국어 특화 버전인 Bllossom은 30,000개의 한국어 전용 토큰을 추가해 한국어 컨텍스트를 약 25% 더 길게 처리할 수 있다 (출처: Dataloop).
기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 | 70B (700억) |
| 아키텍처 | Optimized Transformer + Grouped-Query Attention (GQA) |
| 컨텍스트 윈도우 | 128,000 tokens (약 192 A4 페이지) |
| 최대 출력 | 16,384 tokens |
| 학습 데이터 | 15T+ tokens (공개 온라인 데이터 혼합) |
| Knowledge Cutoff | 2023년 12월 |
| 출시일 | 2024년 12월 6일 |
| 라이선스 | Llama 3.3 Community License (상업적 사용 가능, MAU 7억 초과 시 별도 협의) |
| 지원 언어 | 영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 힌디어, 스페인어, 태국어 |
| 모달리티 | 텍스트 입력 -> 텍스트 출력 (이미지/오디오 미지원) |
| 파인튜닝 | SFT + RLHF |
| 학습 GPU 시간 | 7.0M H100-80GB GPU hours |
| 셀프 호스팅 | FP16 기준 2x 48GB VRAM GPU 필요 |
| API 가격 (최저) | 입력 0.32/1M (프로바이더별 상이) |

참고 자료





스펙
컨텍스트 윈도우
128K 토큰
라이선스
Llama Community License
출시일
2024년 12월 6일
학습 마감일
2023년 12월 1일
조회수
0
API 가격 (USD 기준)
0
{
1
"
2
p
3
r
4
o
5
m
6
p
7
t
8
"
9
:
10
11
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
92.1
복잡한 지시사항 이해 및 수행
코딩
88.4
코드 생성, 버그 수정, 소프트웨어 엔지니어링
일반지식
68.9
다양한 분야 지식 및 이해
Provider
Meta
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 69.7
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1276.0 | elo |
| BBH | 0.7 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Llama 3.3 70B Instruct | 69.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |