Llama 4 Scout
MetaLLM자연어 처리컴퓨터 비전오디오 처리10.0M 토큰
2025년 4월 6일Llama Community License
Llama 4 Scout는 Meta가 2025년 4월에 출시한 Llama 4 시리즈의 경량 모델이다. 109B 총 파라미터 중 17B만 활성화하는 Mixture of Experts(MoE) 아키텍처를 최초로 도입한 모델로, 오픈 웨이트 멀티모달 AI 분야에서 새로운 접근을 시도했다.
주요 특징
Llama 4 Scout의 가장 큰 변화는 MoE 아키텍처의 도입이다. Llama 시리즈에서 처음으로 Mixture of Experts를 채택해 16개의 전문가 모듈 중 토큰마다 2개만 활성화하는 방식으로, 109B 전체 파라미터에서 17B만 사용한다. 이 덕분에 Int4 양자화 시 단일 H100 GPU에서 구동이 가능하다.
두 번째 특징은 10M 토큰의 컨텍스트 윈도우다. Llama 3의 128K에서 약 78배 늘어난 수치로, 공식적으로는 업계 최장 수준이라고 발표했다. 다만 실제 사용자 테스트에서는 128K 이상에서 성능이 급격히 떨어진다는 보고가 다수 있다. 한 독립 연구자가 128K 토큰 분량의 Reddit 스레드 요약을 시켰더니 "완전한 쓰레기" 수준의 결과물이 나왔고, 128K 토큰 기준 정확도가 15.6%에 불과했다 (출처: promptinjection.net). 같은 테스트에서 Gemini 2.5 Pro는 90.6%를 기록했다.
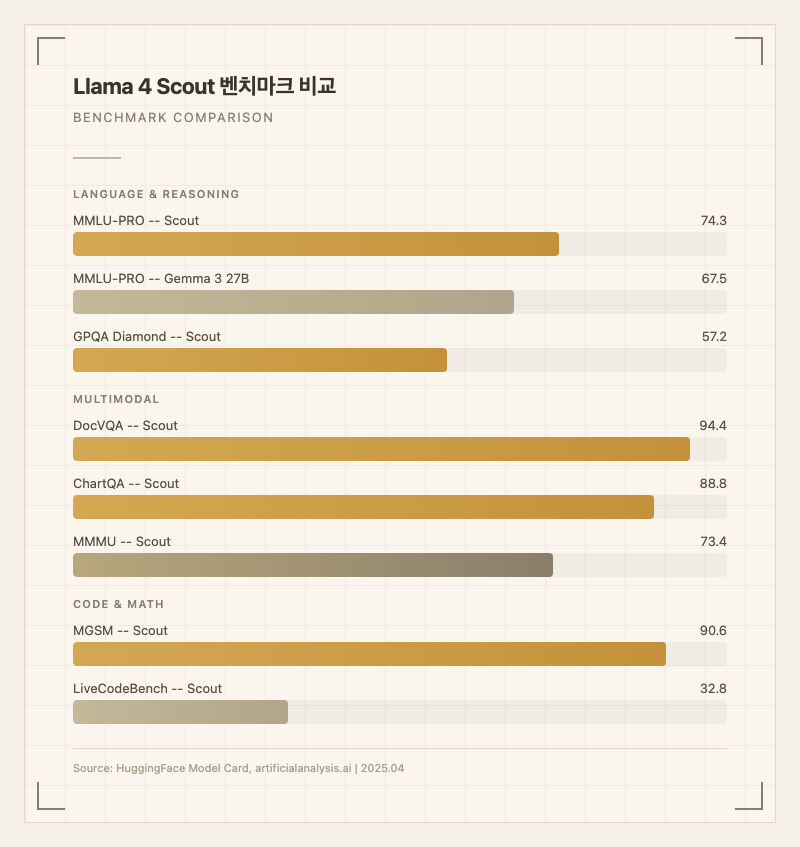
세 번째는 네이티브 멀티모달이다. Early Fusion 방식으로 학습 시점부터 텍스트와 이미지를 통합 처리한다. 학습 중 최대 48개 이미지를 동시 입력했고, DocVQA 94.4, ChartQA 88.8 등 문서/차트 이해에서 강점을 보인다 (출처: HuggingFace Model Card).
넷째, 한국어 토큰 효율이 크게 개선됐다. Meta가 자체 개발한 새 토크나이저(200K vocab, BBPE)를 사용하며, 동일 한국어 텍스트(171자) 기준 Llama 2에서 246토큰이 필요했던 것이 76토큰으로 69% 감소했다 (출처: DevOcean SK). 다만 한국어는 공식 파인튜닝 12개 언어에 포함되지 않아 비공식 지원 상태다.
커뮤니티에서 체감하는 가장 큰 차이는 "가격 대비 성능"이다. 오픈 웨이트라는 점에서 셀프 호스팅이 가능하고, API 사용 시에도 입력 0.30/1M으로 GPT-4o Mini의 절반 수준이다. 반면 "벤치마크 수치와 실제 체감 사이의 괴리가 심하다"는 불만이 출시 직후부터 꾸준히 나왔다.

할 수 있는 것
문서 이해와 차트 분석이 Scout의 강점 분야다. DocVQA 94.4, ChartQA 88.8은 동급 모델 대비 최상위 수준이며, 실사용자들도 PDF나 이미지 속 텍스트 추출에서는 "쓸 만하다"는 평가를 내린다.
번역 성능은 의외의 강점이다. 한 리뷰어가 스와힐리어 번역 테스트에서 Scout에 10점 만점에 8점을 줬는데, 같은 테스트에서 Qwen3가 3점을 받았다. 독일어-영어 시적 텍스트 번역에서도 9/10을 기록하며 "일반적인 대안보다 더 날카로운 이미지를 만든다"는 평가를 받았다 (출처: promptinjection.net).
MGSM 90.6은 다국어 수학 추론에서도 준수한 성능을 보여준다 (출처: HuggingFace Model Card).
반면 코딩은 실망스럽다. LiveCodeBench 32.8은 동급 모델 중 낮은 편이고, 커뮤니티에서는 "코드 생성, 글쓰기, 일상 대화 모든 면에서 실망스럽다"는 반응이 많다 (출처: promptinjection.net). 테트리스 게임 코드 생성 테스트에서 중력 메커니즘 누락, 회전 로직 오류, 게임오버 감지 미구현 등 치명적 결함이 발견됐다. 같은 테스트에서 GLM 4.5 Air는 "프로덕션 수준의 구현"을 제공했다.
장문 맥락 처리는 공식 스펙과 현실의 괴리가 가장 큰 영역이다. 10M 토큰 컨텍스트를 지원한다고 하지만, 실제로는 128K 이상에서 "루핑과 환각"이 발생한다. 20,000토큰 분량의 스레드 요약도 제대로 하지 못했다는 보고가 있다.
창작 글쓰기에서는 10점 만점에 4점을 받으며 "철학적 과욕에 구조적 진부함"이라는 혹평을 들었다. Qwen3 Next 80B가 같은 테스트에서 9점을 받은 것과 대비된다 (출처: promptinjection.net).
성능
| 벤치마크 | Scout 점수 | 비고 |
|---|---|---|
| MMLU | 79.6 | Pretrained (출처: HuggingFace) |
| MMLU-PRO | 74.3 | Instruct (출처: HuggingFace) |
| GPQA Diamond | 57.2 | Instruct (출처: HuggingFace) |
| MATH Lvl 5 | 50.3 | Pretrained (출처: HuggingFace) |
| MMMU | 73.4 | Instruct (출처: HuggingFace) |
| MathVista | 73.7 | Instruct (출처: HuggingFace) |
| DocVQA | 94.4 | Instruct (출처: HuggingFace) |
| ChartQA | 88.8 | Instruct (출처: HuggingFace) |
| LiveCodeBench | 32.8 | Instruct (출처: HuggingFace) |
| MGSM | 90.6 | Instruct (출처: HuggingFace) |
| Multilingual MMLU | 84.6 | (출처: llama.com) |
Meta는 Scout가 "Gemma 3, Gemini 2.0 Flash-Lite, Mistral 3.1을 전반적으로 능가한다"고 발표했다. MMLU-PRO 74.3은 Gemma 3 27B의 67.5를 상회하며, 멀티모달 벤치마크에서도 MMMU 73.4로 견고한 수치를 보인다.
그러나 벤치마크와 실제 사용 사이의 괴리가 Llama 4 Scout의 가장 큰 논란이다. 출시 직후 LM Arena에서 높은 순위를 기록했지만, 이것이 공개된 모델이 아니라 "대화 최적화 실험 버전"에서 측정된 것이라는 사실이 밝혀지면서 "벤치마크 해킹" 논란이 불거졌다 (출처: promptinjection.net, VentureBeat). 영향력 있는 AI 평론가 Zvi Mowshowitz는 "모델 출시에 대한 가장 부정적인 반응"이라고 평가하며 Meta를 "모델 성능 발표를 신뢰할 수 없는 연구소" 범주에 넣었다.
실사용에서 "코드 생성은 GPT-4o보다 깔끔한 코드를 만든다"는 긍정 평가도 있었지만 (출처: secondtalent.com), 전반적으로 "Llama 1 수준의 일반적이고 무미건조한 답변"이라는 혹평이 우세했다.
Artificial Analysis Intelligence Index에서 14점을 받아 동급 오픈 웨이트 비추론 모델 중앙값(13) 대비 소폭 상회하는 수준이다 (출처: artificialanalysis.ai). 출력 속도는 129.7 tokens/sec으로 동급 모델 중앙값(62.4 t/s) 대비 2배 이상 빠르다.
사용 방법
Llama 4 Scout는 오픈 웨이트 모델로 다양한 경로로 접근할 수 있다.
일반 사용자는 Meta AI(meta.ai)에서 직접 대화형으로 사용할 수 있고, HuggingFace의 모델 페이지에서 Inference API로 테스트할 수 있다.
개발자는 HuggingFace에서 모델 가중치를 직접 다운로드(meta-llama/Llama-4-Scout-17B-16E-Instruct)해서 셀프 호스팅하거나, API 제공업체를 통해 접근할 수 있다. 주요 API 제공업체로는 OpenRouter, AWS Bedrock, Oracle Cloud, IBM watsonx.ai, Groq 등이 있다.
Groq에서는 특히 빠른 추론 속도를 제공하며, OpenRouter를 통해 다양한 제공업체의 가격과 성능을 비교할 수 있다.
셀프 호스팅 시 Int4 양자화를 적용하면 단일 H100 GPU에서 구동 가능하다. vLLM, TGI 등의 추론 프레임워크와 호환되며, NVIDIA의 최적화 가이드도 공개되어 있다.
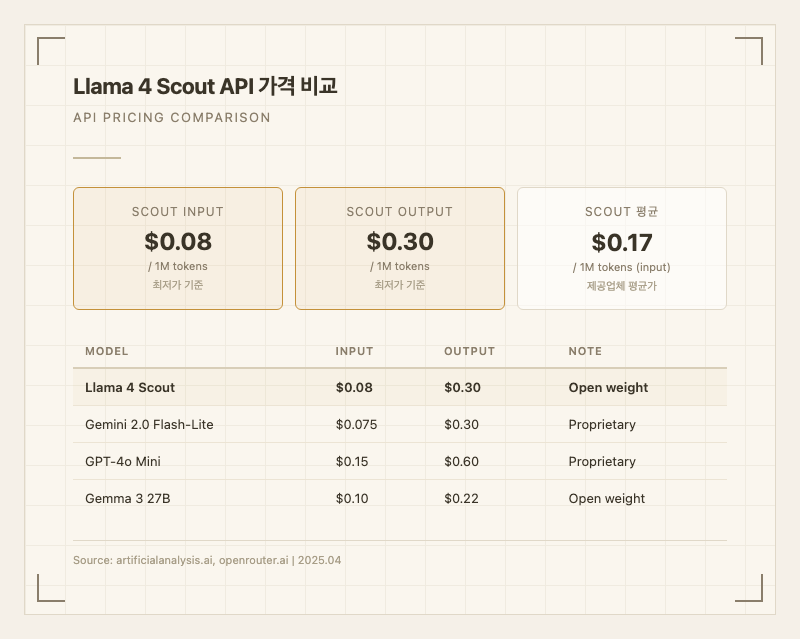
가격API 기준 가격(제공업체 최저가):
- 입력: $0.08 / 1M tokens
- 출력: $0.30 / 1M tokens
Artificial Analysis 집계 평균가:
- 입력: $0.17 / 1M tokens
- 출력: $0.66 / 1M tokens
경쟁 모델과 비교하면 GPT-4o Mini(입력 0.60)의 약 절반 수준이고, Gemini 2.0 Flash-Lite(입력 0.30)와 거의 동등하다. 오픈 웨이트라는 점에서 셀프 호스팅 시 API 비용 없이 GPU 비용만으로 운용 가능하다는 장점이 있다.
한국어 토큰 효율 측면에서, 동일 텍스트 기준 Llama 2 대비 약 69% 적은 토큰을 사용하므로 한국어 API 호출 비용이 이전 세대보다 크게 절감된다. 171자 한국어 텍스트 기준 76토큰으로 처리되며, OpenAI의 o200k_base 토크나이저(88토큰)보다도 효율적이다 (출처: DevOcean SK). 다만 SKT A.X 토크나이저 대비로는 약 30% 더 많은 토큰을 사용한다.
커뮤니티에서의 가성비 평가는 양분된다. "오픈 소스에 이 가격이면 훌륭하다"는 의견과 "가격이 싸도 성능이 기대 이하면 의미 없다"는 의견이 공존한다.
기술 사양
| 항목 | 사양 |
|---|---|
| 총 파라미터 | 109B (17B 활성) |
| 아키텍처 | Mixture of Experts, 16 Experts |
| 컨텍스트 윈도우 | 10M tokens (학습 시 256K) |
| 학습 데이터 | 40T+ tokens |
| 학습 데이터 언어 | 200개 언어 (100개 이상에서 각 1B+ tokens) |
| 파인튜닝 언어 | 12개 (아랍어, 영어, 프랑스어, 독일어, 힌디어, 인도네시아어, 이탈리아어, 포르투갈어, 스페인어, 타갈로그어, 태국어, 베트남어) |
| 학습 마감일 | 2024년 8월 |
| 출시일 | 2025년 4월 5일 |
| 멀티모달 | 텍스트 + 이미지 입력 (Early Fusion) |
| 토크나이저 | BBPE, 200K vocab (Meta 자체 개발) |
| 라이선스 | Llama Community License |
| 추론 속도 | ~130 tokens/sec 중앙값 (출처: artificialanalysis.ai) |
| 최소 GPU | 1x H100 (Int4 양자화 시) |

참고 자료





스펙
컨텍스트 윈도우
10.0M 토큰
라이선스
Llama Community License
출시일
2025년 4월 6일
학습 마감일
2024년 8월 31일
가성비 지수
21.3
API 가격 (혼합)
입력 $0.080/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.08 / 1M 토큰
출력 (Completion)
$0.30 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
일반지식최강
74.3
다양한 분야 지식 및 이해
멀티모달
73.4
이미지, 비디오 등 멀티모달 이해
수학/추론
53.8
수학, 과학, 논리적 추론
Provider
Meta
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 60.4
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GPQA | 57.2 | % |
| MATH Lvl 5 | 50.3 | % |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Llama 4 Scout | 60.4 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |