Phi 4
MicrosoftLLM자연어 처리컴퓨터 비전오디오 처리16K 토큰
2025년 1월 10일MIT
Phi-4는 Microsoft Research가 개발한 14B 파라미터 소형 언어 모델(SLM)로, "데이터 품질이 모델 크기를 이긴다"는 철학 아래 수학적 추론과 복잡한 논리 문제 해결에 특화되어 설계되었다. 2024년 12월에 공개되었으며, MIT 라이선스로 완전 오픈소스다.
주요 특징
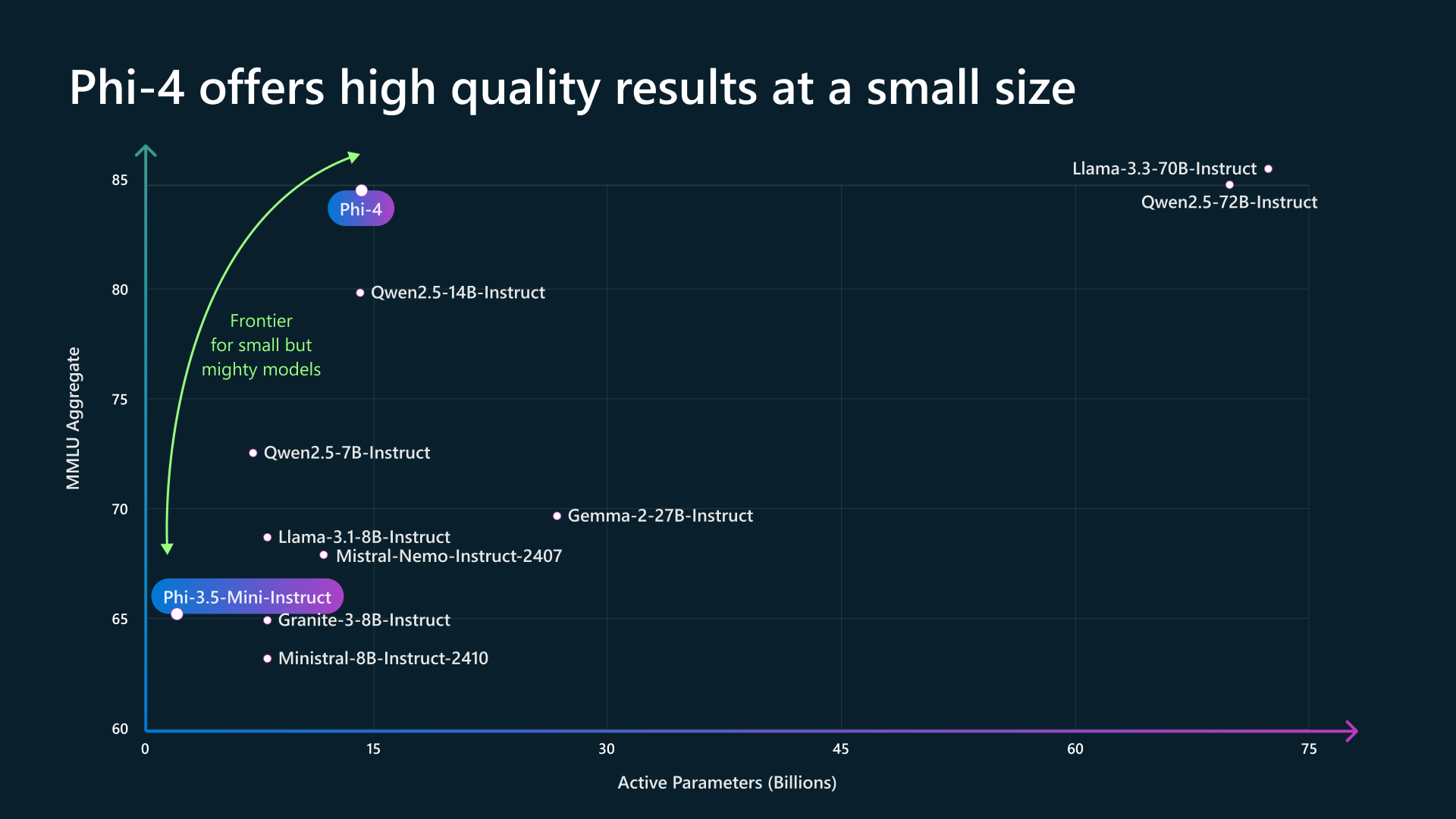
Phi-4의 가장 두드러진 특성은 크기 대비 추론 성능이다. 14B라는 작은 파라미터 수에도 불구하고, 수학과 과학 추론에서 자신보다 5배 큰 모델들을 능가한다. Microsoft Research는 9.8T 토큰 규모의 고품질 합성 데이터(synthetic data)와 엄선된 학술 자료, 코드 데이터를 혼합해 학습시켰고, 1920대의 H100 GPU에서 21일 만에 학습을 완료했다(출처: 공식 기술 보고서 arxiv:2412.08905).
핵심 차별점 5가지:
- 합성 데이터 중심 학습: 일반적인 웹 크롤링 데이터 대신 수학, 코딩, 추론에 특화된 합성 데이터로 학습하여 같은 크기 모델 대비 추론 능력이 월등하다.
- MIT 라이선스: Llama의 커뮤니티 라이선스나 Qwen의 Apache 2.0과 달리, 가장 개방적인 MIT 라이선스를 채택했다. 상업적 제한이 전혀 없다.
- 소비자 GPU 실행 가능: INT4 양자화 시 8-10GB VRAM이면 충분하다. RTX 4070 이상에서 초당 약 50 토큰 속도로 로컬 실행이 가능하다(출처: 클리앙 사용자 테스트, RTX 4080 Super 기준).
- 교사 모델 능가: GPQA(대학원 수준 과학 문제)와 MATH(경시대회 수학) 벤치마크에서 자신의 교사 모델인 GPT-4o를 능가하는 특이한 사례를 만들었다(출처: 공식 기술 보고서).
- Phi 패밀리 확장: 기본 14B 모델 이후 Phi-4-reasoning(추론 강화), Phi-4-mini(3.8B 경량), Phi-4-multimodal(음성+비전+텍스트 통합 5.6B), Phi-4-reasoning-vision(15B 비전 추론) 등으로 빠르게 패밀리가 확장되고 있다.
실사용자들이 체감하는 가장 큰 차이는 "이 크기에서 이 정도 추론을 하는 모델은 없다"는 점이다. 클리앙의 한 사용자는 "일반적인 능력은 GPT-4o급에 PDF/텍스트 파일 분석도 가능하다"고 평가했다. 반면, 영어 중심 학습 데이터 때문에 한국어 성능은 EXAONE3.5나 Aya-Expanse 같은 다국어 특화 모델에 비해 뒤처진다는 의견이 많다.

할 수 있는 것
Phi-4가 실제로 잘하는 것과 못하는 것을 나눠서 보자.
잘하는 것:
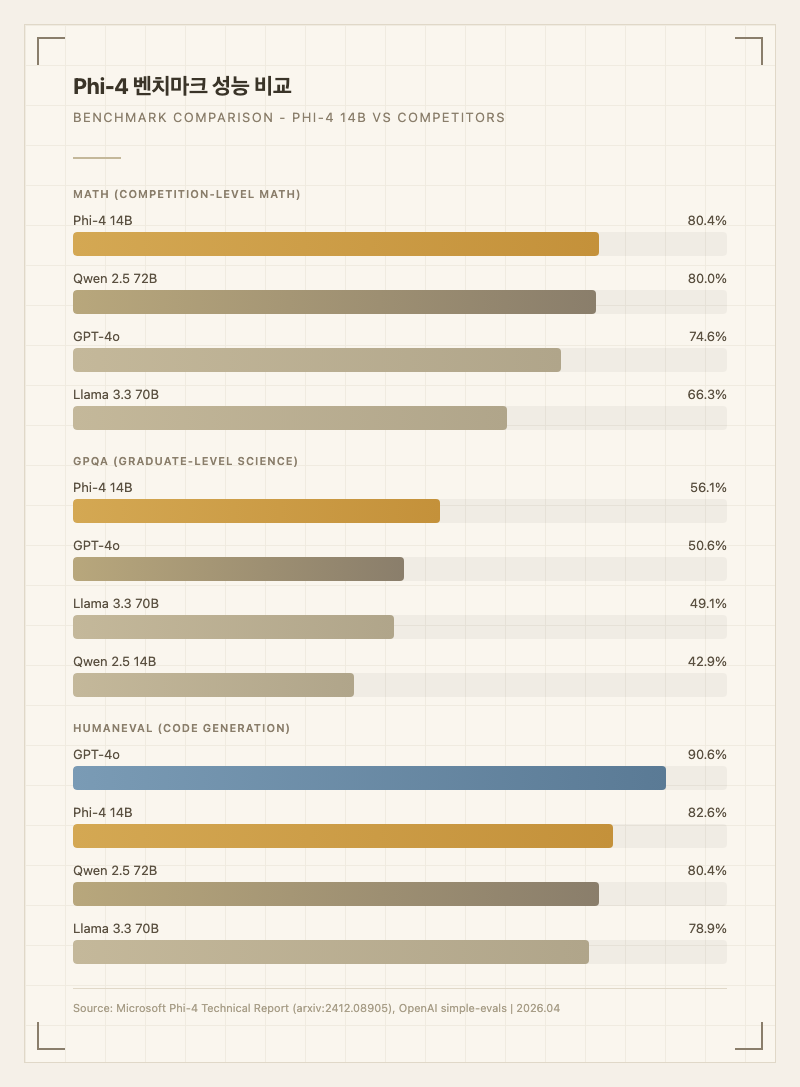
- 수학 문제 풀이: 경시대회 수준의 수학 문제에서 MATH 80.4%를 기록한다. 같은 크기의 Qwen 2.5 14B(75.6%)를 크게 앞서고, 5배 큰 Llama 3.3 70B(66.3%)도 넘는다(출처: 공식 기술 보고서). 실제로 수학 과외용 AI로 쓰기에 적합하다.
- 코드 생성: HumanEval 82.6%로 같은 크기 오픈소스 모델 중 최고 수준이다. 간단한 함수 작성, 알고리즘 구현, 버그 수정에 실용적이다(출처: 공식 기술 보고서).
- 과학 추론: GPQA 56.1%로 대학원 수준 과학 문제에서 GPT-4o(50.6%)를 능가한다. 물리, 화학, 생물 관련 개념 설명이나 문제 풀이에 효과적이다(출처: 공식 기술 보고서).
- 로컬 AI 어시스턴트: Ollama나 LM Studio에서 양자화 모델을 돌리면 인터넷 없이도 작동하는 개인 AI 어시스턴트를 만들 수 있다. 프라이버시가 중요한 업무에 적합하다.
못하는 것 / 한계:
- 지시 따르기(instruction following): DEV Community의 한 개발자가 체스 평가 프레임워크로 테스트한 결과, Phi-4는 Gemma 2 9B 대비 약 6배 많은 토큰을 생성하면서도 10배 많은 실수를 했다. 단순한 프롬프트 지시조차 자주 위반했고, 지나치게 장황한 응답이 원인으로 지목되었다(출처: DEV Community, maximsaplin). 벤치마크 점수와 실제 사용감의 괴리를 잘 보여주는 사례다.
- 사실 정확도: SimpleQA 벤치마크에서 3.0%를 기록하며, GPT-4o(39.4%)는 물론 같은 크기의 Qwen 2.5 14B(5.4%)보다도 낮다(출처: 공식 기술 보고서). 사실 확인이 필요한 작업에는 부적합하다. 한 Hugging Face 사용자는 "MMLU-PRO 점수는 48로 이 크기에서 불가능할 만큼 높은데, SimpleQA는 3으로 극단적으로 낮다. 이 정도 과적합은 처음 본다"고 지적했다.
- 긴 컨텍스트 처리: 16K 토큰 컨텍스트 윈도우는 현재 기준으로 매우 작다. Llama 3.3(128K)이나 Qwen 2.5(128K) 대비 8분의 1 수준이다. RAG 파이프라인이나 긴 문서 분석에는 심각한 제약이 된다.
- 한국어 성능: 영어 최적화 모델이라 한국어에서의 성능은 제한적이다. 기본적인 한국어 대화와 텍스트 교정은 가능하지만, EXAONE3.5나 Qwen 계열에 비해 자연스러움이 떨어진다는 평가가 지배적이다.
- Agentic 작업: 16K 컨텍스트와 지시 따르기 문제로 인해 SWE-bench 같은 에이전트 벤치마크 결과가 보고되지 않았다. 복잡한 멀티스텝 에이전트 워크플로우에는 적합하지 않다.
성능벤치마크 수치를 보면 Phi-4의 위치가 명확해진다.
| 벤치마크 | Phi-4 14B | Qwen 2.5 14B | GPT-4o mini | Llama 3.3 70B | GPT-4o |
|---|---|---|---|---|---|
| MMLU | 84.8 | 79.9 | 81.8 | 86.3 | 88.1 |
| GPQA | 56.1 | 42.9 | 40.9 | 49.1 | 50.6 |
| MATH | 80.4 | 75.6 | 73.0 | 66.3 | 74.6 |
| HumanEval | 82.6 | 72.1 | 86.2 | 78.9 | 90.6 |
| MGSM | 80.6 | 79.6 | 86.5 | 89.1 | 90.4 |
| SimpleQA | 3.0 | 5.4 | 9.9 | 20.9 | 39.4 |
| IFEval | 82.6 | - | - | 92.1 | - |
(출처: Microsoft Phi-4 Technical Report arxiv:2412.08905, OpenAI simple-evals)
수학(MATH 80.4)과 과학(GPQA 56.1)에서는 14B 모델로서 압도적이다. 자신보다 5배 큰 Llama 3.3 70B(MATH 66.3, GPQA 49.1)보다 높고, Qwen 2.5 72B(MATH 80.0)와 거의 동급이다. 코딩(HumanEval 82.6)도 같은 크기 대비 최상위권이다.
그러나 "벤치마크는 이런데 실제로는 이렇다"가 Phi-4를 이해하는 핵심이다. 벤치마크에서 높은 점수를 받는 것과 실제 작업에서 안정적으로 작동하는 것은 다르다. DEV Community의 체스 테스트에서 드러났듯, 지시를 안정적으로 따르는 능력이 부족하다. Artificial Analysis의 종합 평가에서도 Intelligence Index 10점으로 "평균 이하"로 분류되었다(출처: artificialanalysis.ai).
속도 측면에서도 API 기준 31.6 tokens/second, TTFT 2.12초로 같은 급 모델 대비 "상당히 느린 편"이라는 평가를 받았다(출처: artificialanalysis.ai). 로컬 실행 시에는 하드웨어에 따라 크게 다르지만, RTX 4080 Super에서 초당 50 토큰 정도가 보고되었다.
사용 방법일반 사용자:
- Azure AI Foundry: https://ai.azure.com/catalog/models/Phi-4 에서 바로 사용 가능. Microsoft 계정으로 로그인하면 웹 UI에서 대화할 수 있다.
- Ollama:
ollama run phi4로 로컬에서 즉시 실행. INT4 양자화 버전이 기본 제공되어 8GB VRAM이면 충분하다. - LM Studio: GUI 기반으로 Phi-4를 다운로드하고 실행할 수 있다. 프로그래밍 지식 없이도 로컬 AI를 운영할 수 있다.
개발자:
- Hugging Face Transformers:
python
import transformers
pipeline = transformers.pipeline(
"text-generation",
model="microsoft/phi-4",
model_kwargs={"torch_dtype": "auto"},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Solve: x^2 + 5x + 6 = 0"},
]
outputs = pipeline(messages, max_new_tokens=256)
- API 호출: OpenRouter, DeepInfra, Azure AI 등 다수 프로바이더에서 OpenAI 호환 API로 제공. 기존 코드베이스에서 모델명만 바꾸면 된다.
- 채팅 템플릿:
<|im_start|>system<|im_sep|>...<|im_end|>형식의 ChatML 템플릿을 사용한다.
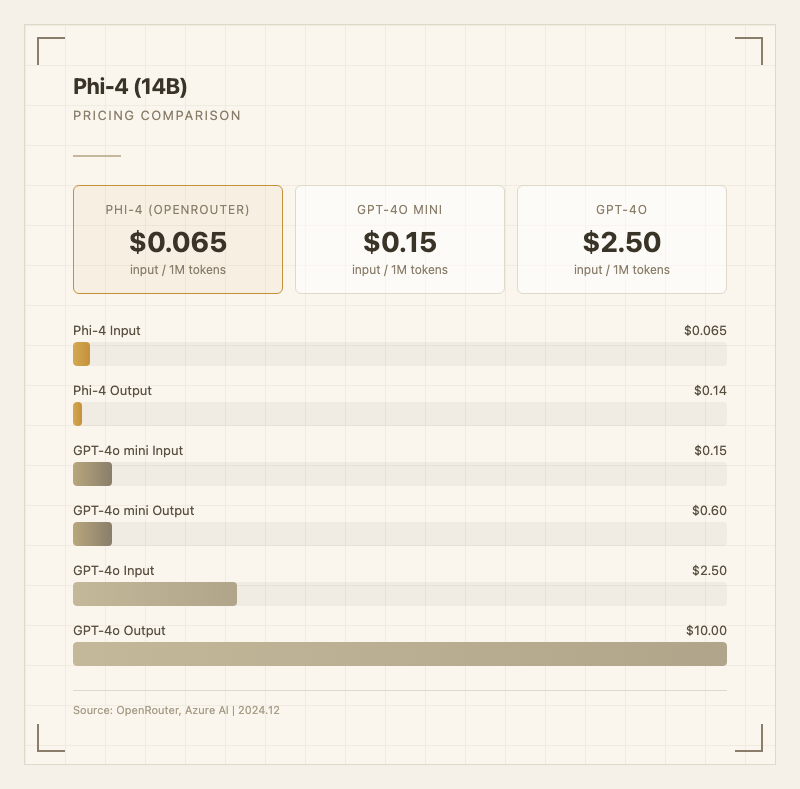
가격Phi-4의 가격 경쟁력은 명확하다.
API 기준 (OpenRouter):
- 입력: $0.065 / 1M 토큰
- 출력: $0.14 / 1M 토큰
- 블렌딩 비용 (3:1 기준): $0.22 / 1M 토큰
Azure AI 기준:
- 입력: $0.13 / 1M 토큰
- 출력: $0.50 / 1M 토큰
GPT-4o(입력 10.00)와 비교하면 약 40배 저렴하다. GPT-4o mini(입력 0.60)와 비교해도 절반 이하다. 비용에 극도로 민감한 대량 처리 워크로드에서 큰 장점이 된다.
로컬 실행 비용: MIT 라이선스이므로 로컬에서 무료로 실행할 수 있다. INT4 양자화 시 RTX 4070 급이면 충분하다. 전기료만 부담하면 되므로 대량 처리 시 API 대비 극적인 비용 절감이 가능하다.
다만, Artificial Analysis는 Phi-4를 "비슷한 크기의 오픈 모델 대비 다소 비싼 편"으로 평가했다(입력 평균 0.13, 출력 평균 0.50)(출처: artificialanalysis.ai). 이는 Azure 기준이고, OpenRouter 등 서드파티 프로바이더를 이용하면 훨씬 저렴하게 이용할 수 있다.
한국어 토큰 효율 데이터는 미공개다. Phi-4는 기본 토크나이저를 사용하며, 다국어 최적화 토크나이저(예: Qwen의 200K 어휘)를 채택한 모델에 비해 한국어 입력 시 토큰 수가 더 많이 소요될 가능성이 있다. Phi-4-mini는 200K 토큰 어휘의 확장된 토크나이저를 사용하지만, 기본 Phi-4 14B에는 적용되지 않는다.
기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 | 14B (140억) |
| 아키텍처 | Dense Decoder-only Transformer |
| 컨텍스트 윈도우 | 16,384 토큰 |
| 최대 출력 | 16,384 토큰 |
| 학습 데이터 | 9.8T 토큰 |
| 학습 구성 | 합성 데이터 + 엄선된 웹사이트 + 학술 자료 + 코드 |
| 다국어 데이터 비중 | 전체의 약 8% |
| 학습 기간 | 21일 |
| 학습 인프라 | 1920x H100-80G GPU |
| 학습 기간 | 2024년 10월 - 11월 |
| Knowledge Cutoff | 2024년 6월 |
| 출시일 | 2024년 12월 12일 |
| 라이선스 | MIT |
| 지원 언어 | 영어 중심, 한국어 포함 22개 언어 기본 지원 |
| VRAM (FP16) | 28GB |
| VRAM (INT4) | 8-10GB |
(출처: Hugging Face microsoft/phi-4 모델 카드, Microsoft Research 공식 기술 보고서)
Phi-4의 아키텍처는 표준 Dense Transformer이다. MoE(Mixture of Experts)나 특수 아키텍처를 사용하지 않았으며, 순수하게 데이터 품질과 학습 방법론으로 성능을 끌어올렸다는 점이 Microsoft Research의 핵심 주장이다. 학습 데이터의 상당 부분이 합성 데이터(synthetic textbook-like data)로 구성되어 있어, 수학, 코딩, 추론 분야에서 높은 성능을 보이지만 사실적 지식 저장 능력(SimpleQA 3.0%)은 크게 부족하다.

참고 자료





스펙
컨텍스트 윈도우
16K 토큰
라이선스
MIT
출시일
2025년 1월 10일
학습 마감일
2024년 6월 30일
가성비 지수
33.8
API 가격 (혼합)
입력 $0.065/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.07 / 1M 토큰
출력 (Completion)
$0.14 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
코딩최강
82.6
코드 생성, 버그 수정, 소프트웨어 엔지니어링
지시따르기
82.6
복잡한 지시사항 이해 및 수행
수학/추론
68.3
수학, 과학, 논리적 추론
Provider
Microsoft
Microsoft의 다른 모델
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 69.7
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| BBH | 0.7 | % |
| GPQA | 56.1 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Phi 4 | 69.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |