WizardLM-2 8x22B
MicrosoftLLM자연어 처리컴퓨터 비전오디오 처리66K 토큰
2024년 4월 16일Apache 2.0
WizardLM-2 8x22B - Microsoft AI의 Evol-Instruct 방법론을 적용한 오픈소스 MoE 모델
WizardLM-2 8x22B는 Microsoft AI의 WizardLM 팀이 2024년 4월에 출시한 대형 언어 모델이다. Mistral AI의 Mixtral 8x22B를 베이스로, Microsoft 독자 개발한 Evol-Instruct 방법론과 Stage-DPO, RLEIF 학습 파이프라인을 적용해 지시 따르기 능력과 복합 추론 성능을 끌어올렸다. Apache 2.0 라이선스로 공개되어 상업적 활용이 자유롭다.
주요 특징
WizardLM-2 8x22B를 다른 오픈소스 모델과 구분 짓는 핵심은 학습 방법론에 있다.
첫째, Evol-Instruct. 기존 학습 데이터를 LLM을 활용해 진화적으로 복잡하게 변형하는 기법이다. 단순한 지시문을 다단계 추론이 필요한 복잡한 버전으로 자동 변환하여, 수동 데이터 수집 없이도 고난도 학습 데이터를 대량 생성한다. 이 방식이 WizardLM 시리즈의 근본 차별점이다.
둘째, Stage-DPO(단계적 직접 선호도 최적화). 선호도 데이터를 한꺼번에 학습시키지 않고 난이도별로 슬라이스를 나누어 점진적으로 모델을 개선한다. 이를 통해 단일 패스 DPO 대비 정렬 품질이 더 정교해진다.
셋째, AI Align AI(AAA) 프레임워크. 여러 오픈소스 및 프로프라이어터리 모델을 수집하여, 서로 가르치고 평가하는 co-teaching 구조를 구성한다. 각 모델이 품질 판단, 개선 제안, 스킬 갭 보완을 자동으로 수행하며, 이 과정에서 합성 데이터의 품질이 높아진다.
넷째, RLEIF(Reinforcement Learning with Instruction and Process Feedback). 지시 품질 보상 모델(IRM)과 과정 감독 보상 모델(PRM)을 결합한 온라인 강화학습으로, 최종 답변뿐 아니라 추론 과정의 정확성까지 최적화한다.
출시 당시 사용자들 사이에서는 "오픈소스 모델 중에서는 확실히 GPT-4에 가장 근접하다"는 평가가 주류였다. 실제로 한 사용자는 로컬에서 WizardLM-2 8x22B를 돌려 15분 만에 원하는 SF TV 시리즈 추천 목록을 뽑아냈다는 후기를 남기기도 했다. 다만 낮은 양자화(IQ-1 수준)에서도 복잡한 추론이 작동한다는 보고와 함께, 상식 판단이나 현실 세계 경험에 기반한 질문에서는 간혹 비상식적인 답변이 나온다는 지적도 있었다.

할 수 있는 것
WizardLM-2 8x22B는 글쓰기, 코딩, 수학, 추론, 에이전트, 다국어 처리를 공식 학습 대상으로 삼고 있다. 공식적으로는 "인류의 주요 요구사항을 포괄하는 실세계 지시문"에 대해 학습했다고 설명한다.
실제 사용자들이 보고한 활용 사례를 보면, 복잡한 추론 체인이 필요한 분석 작업에서 강점을 보인다. 코딩 보조로는 준수한 수준이지만, 2024년 후반부터 등장한 최신 모델들(Llama 3, Qwen 2.5 등)에 비하면 코드 생성 품질에서 뒤처진다는 평가가 많다.
반면, 할 수 없는 것도 명확하다. 텍스트 전용 모델이므로 이미지 인식이나 생성은 불가능하다. Tool Use(함수 호출)와 Structured Output(JSON 스키마 강제)을 지원하지 않아, API 기반 에이전트 파이프라인에 직접 통합하기 어렵다. 또한 최대 출력이 8,000 토큰으로 제한되어 장문 생성에는 한계가 있다.
성능
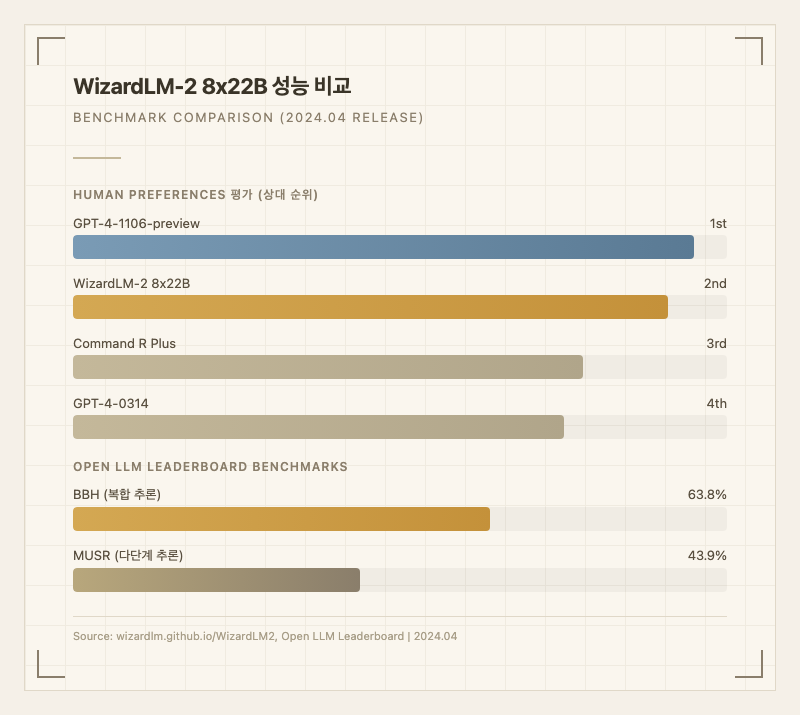
출시 당시 Microsoft가 공개한 Human Preferences 평가에서 WizardLM-2 8x22B는 GPT-4-1106-preview 바로 다음 순위를 기록했고, Command R Plus와 GPT-4-0314을 유의미하게 앞질렀다 (출처: 공식 블로그). MT-Bench에서도 GPT-4-Turbo, Claude-3와 경쟁할 수 있는 수준이라고 평가되었다 (출처: 공식 블로그).
Open LLM Leaderboard 기준으로는 BBH 63.8%, MUSR 43.9%를 기록했다 (출처: Open LLM Leaderboard).
하지만 현실적인 평가는 다르다. 2024년 4월 출시 이후 Llama 3 70B, Qwen 2.5, Mistral Large 등 후속 모델들이 대거 등장하면서 WizardLM-2 8x22B의 상대적 위치는 크게 하락했다. Hacker News에서는 "Llama 3 8B가 WizardLM-2 8x22B와 거의 비슷한 수준"이라는 제목의 토론이 열리기도 했다. 벤치마크 수치보다 파라미터 효율 면에서 후발 주자들에게 완전히 추월당한 상태다.
또한 출시 직후 Microsoft가 독성 테스트를 누락했다는 이유로 모델을 삭제하는 해프닝이 있었다. 이미 커뮤니티에서 다운로드하여 재업로드한 상태였기에 실질적인 회수는 불가능했지만, 안전성 검증이 불완전한 모델이라는 인식이 남아 있다 (출처: 404 Media).
사용 방법
WizardLM-2 8x22B는 웹 기반 공식 플레이그라운드를 제공하지 않는다. 사용하려면 API 제공업체를 통하거나 로컬에 직접 배포해야 한다.
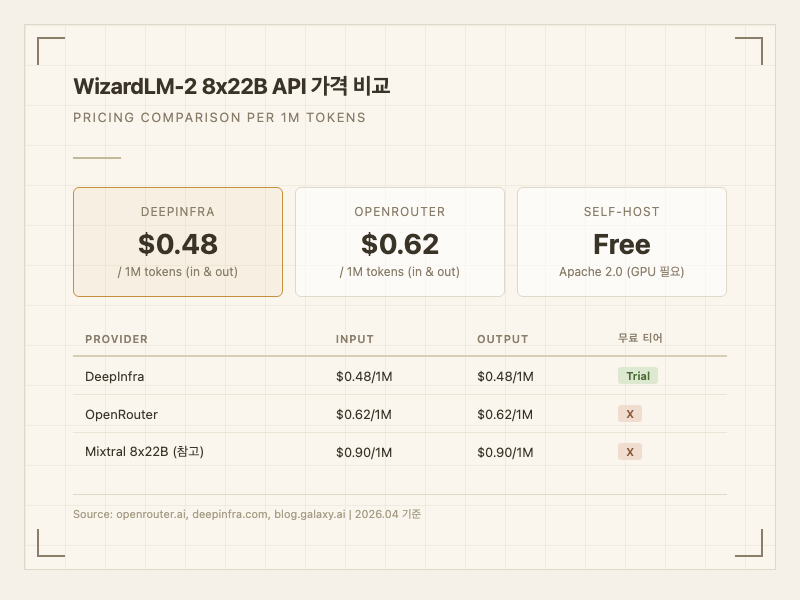
API 사용 (개발자): OpenRouter, DeepInfra 등에서 OpenAI 호환 API를 통해 접근할 수 있다. DeepInfra에서는 입출력 모두 0.62/1M 토큰이다. 엔드포인트 URL만 변경하면 기존 OpenAI SDK 코드를 거의 수정 없이 사용할 수 있다.
로컬 배포 (고급 사용자): Apache 2.0 라이선스이므로 Hugging Face에서 가중치를 다운로드하여 로컬에 배포할 수 있다. Ollama에서 ollama run wizardlm2:8x22b로 간편하게 실행 가능하다. 다만 141B 파라미터 모델이므로 최소 80GB 이상의 GPU VRAM이 필요하며, 양자화 버전(GGUF)을 사용하면 메모리 요구량을 줄일 수 있다.
프롬프트 형식은 Vicuna-style로, 멀티턴 대화를 지원한다.
가격
WizardLM-2 8x22B는 오픈소스 모델이므로 셀프 호스팅 시 모델 사용료는 무료다. API를 통해 사용할 경우 제공업체별로 가격이 다르다.
| 제공업체 | 입력 (1M 토큰) | 출력 (1M 토큰) |
|---|---|---|
| DeepInfra | $0.48 | $0.48 |
| OpenRouter | $0.62 | $0.62 |
베이스 모델인 Mixtral 8x22B Instruct의 API 가격이 약 $0.90/1M 토큰인 점을 감안하면, WizardLM-2 변형이 성능은 높으면서 가격은 더 저렴하다. MoE 아키텍처 특성상 총 파라미터(141B) 대비 실제 추론 비용이 효율적이기 때문이다.
다만 현재 시점에서 가성비를 평가하면, 비슷한 가격대에서 Llama 3 70B나 Qwen 2.5 72B 등 더 최신이고 더 높은 성능을 제공하는 모델들이 존재한다. 한국어 토큰 효율 데이터는 미공개이며, Mistral 토크나이저가 주로 유럽 언어에 최적화되어 있어 한국어 처리 시 토큰 소모가 상대적으로 많을 가능성이 높다.
기술 사양
| 항목 | 사양 |
|---|---|
| 개발사 | Microsoft AI (WizardLM Team) |
| 베이스 모델 | Mixtral 8x22B (Mistral AI) |
| 아키텍처 | Sparse Mixture of Experts (SMoE) |
| 총 파라미터 | 141B (8 experts x 22B) |
| 활성 파라미터 | ~39B (추론 시 2 experts 활성) |
| 컨텍스트 윈도우 | 65,536 tokens |
| 최대 출력 토큰 | 8,000 tokens |
| 토크나이저 | Mistral BPE (32K vocab) |
| 입출력 유형 | 텍스트 전용 |
| 프롬프트 형식 | Vicuna-style (multi-turn) |
| 학습 방법 | Evol-Instruct + Stage-DPO + AAA + RLEIF |
| 라이선스 | Apache 2.0 |
| 출시일 | 2024년 4월 15일 |
| 학습 데이터 기준일 | 미공개 (Mixtral 기반 추정: ~2024년 초) |

참고 자료



스펙
컨텍스트 윈도우
66K 토큰
라이선스
Apache 2.0
출시일
2024년 4월 16일
학습 마감일
2024년 4월 30일
가성비 지수
0.1
API 가격 (혼합)
입력 $0.620/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.62 / 1M 토큰
출력 (Completion)
$0.62 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
Provider
Microsoft
Microsoft의 다른 모델
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| BBH | 0.6 | % |
| MUSR | 0.4 | % |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| WizardLM-2 8x22B | - |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |