Llama 3.2 11B Vision Instruct
MetaVLM시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)131K 토큰
2024년 9월 25일Llama Community License
Meta가 2024년 9월 Meta Connect에서 공개한 Llama 3.2 11B Vision Instruct는 텍스트와 이미지를 동시에 처리하는 11B 파라미터 오픈 웨이트 멀티모달 모델이다. Llama 3.1 8B 텍스트 모델 위에 Cross-Attention 방식으로 비전 어댑터를 결합한 구조로, 텍스트 전용 성능을 유지하면서 이미지 이해 기능을 추가한 것이 특징이다.
주요 특징
Llama 3.2 11B Vision의 핵심은 "작은 크기에서의 멀티모달"이다. 기존에 이미지를 이해하려면 GPT-4o나 Claude 3.5 Sonnet 같은 대형 모델을 써야 했는데, 이 모델은 11B라는 상대적으로 작은 파라미터로 비전 기능을 제공한다.
첫째, Cross-Attention 아키텍처. 이미지 인코더의 표현을 언어 모델에 주입하는 Cross-Attention 레이어를 사용한다. 기존 텍스트 모델 파라미터는 학습 중 업데이트하지 않아서, Llama 3.1 8B의 텍스트 성능을 그대로 유지한다 (출처: Meta AI Blog). 이 방식 덕분에 텍스트 전용 작업에서 비전 모델의 성능 저하가 없다.
둘째, 128K 토큰 컨텍스트. 텍스트 기준 128K 토큰을 지원하고, 512x512 이미지 한 장이 약 1,610 토큰으로 변환된다 (출처: Meta 공식 문서). 긴 문서에 이미지를 함께 넣어 분석하는 것이 가능하다.
셋째, Ollama로 로컬 실행 가능. 양자화를 통해 최소 8GB VRAM에서 구동된다. 오픈 웨이트 멀티모달 모델 중에서 소비자 GPU로 돌릴 수 있는 몇 안 되는 선택지다. 다만 실사용자들은 맥북에서 돌리면 메모리가 크게 뛰어오르고, 이미지 분석 시 한번 더 점프한다고 보고한다 (출처: joinc.co.kr 실사용 리뷰). 실행은 되지만 "쾌적하다"고 하기는 어렵다는 반응이 많다.
넷째, 극저가 API 비용. OpenRouter 기준 input/output 모두 2.50/1M input) 대비 약 50배 이상 저렴하다 (출처: OpenRouter). 대량 이미지 처리 파이프라인에서 비용 부담이 거의 없다.
할 수 있는 것
공식적으로 이미지 캡셔닝, 시각적 질의응답(VQA), 문서 이해(차트/그래프), 이미지 내 객체의 방향 기반 위치 특정(Visual Grounding)을 지원한다 (출처: Meta AI Blog).
실사용자들이 실제로 많이 쓰는 용도는 OCR 보조 작업이다. 이미지에서 텍스트를 추출하는 데 꽤 괜찮다는 평가가 있지만, GPT-4o와 비교하면 정확도가 떨어진다는 의견이 지배적이다. 특히 한국어 OCR은 공식 지원 언어에 한국어가 포함되지 않아 기대하기 어렵다. 비전 작업에서는 영어만 공식 지원한다 (출처: HuggingFace Model Card).
차트와 그래프 해석에서는 ChartQA 83.4점(CoT 기준)으로 같은 급에서 나쁘지 않은 성능을 보여준다 (출처: HuggingFace Model Card). 다만 복잡한 차트에서는 환각(hallucination)이 발생한다는 보고가 있다. 숫자를 지어내거나 없는 데이터를 만들어내는 경우가 Qwen2.5-VL 7B나 MiniCPM 같은 경쟁 모델보다 눈에 띄게 잦다는 피드백이 있다 (출처: HuggingFace Discussion #110).
이미지 기반 분류 자동화, 교육 콘텐츠의 시각적 Q&A, 경량 엣지 환경에서의 멀티모달 배포에 적합하다. 반면 정밀 OCR, 복잡한 시각적 추론, 세밀한 객체 탐지가 필요한 작업에는 상위 모델을 고려해야 한다.
성능
벤치마크 수치와 실사용 체감 사이에 뚜렷한 갭이 있는 모델이다.
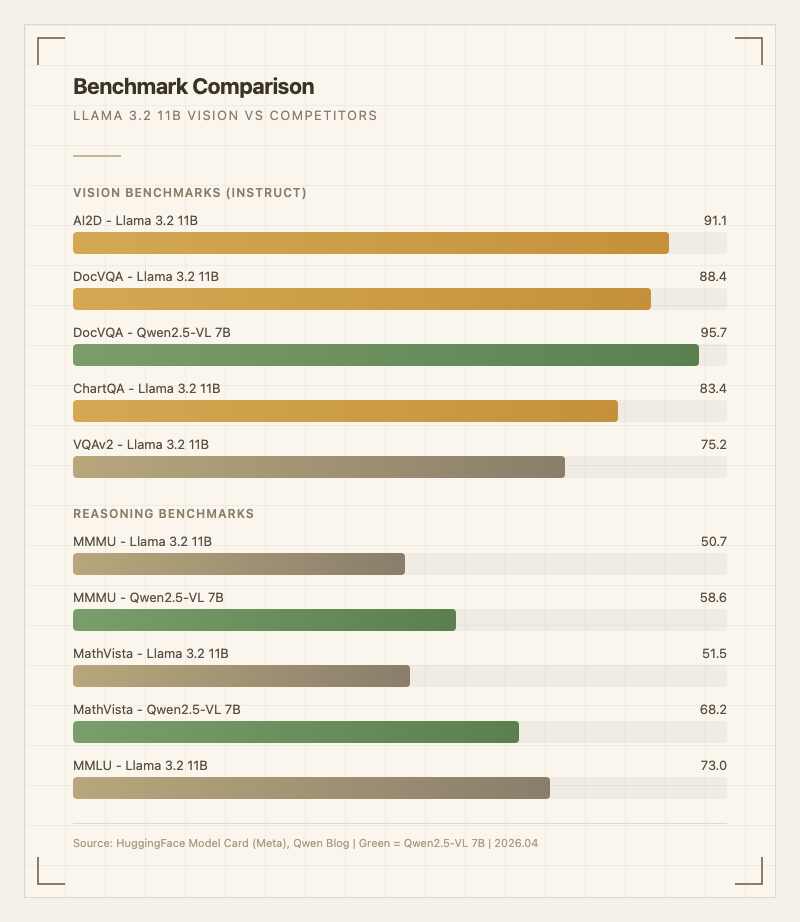
공식 벤치마크(Instruct 버전)를 보면 AI2D 91.1, DocVQA 88.4, ChartQA 83.4로 다이어그램과 문서 이해에서는 꽤 높은 점수를 기록한다. VQAv2 75.2, MMMU 50.7, MathVista 51.5, MMLU 73.0, GPQA 32.8, MATH 51.9 등이다 (출처: HuggingFace Model Card).
| 벤치마크 | Llama 3.2 11B | Qwen2.5-VL 7B | 비고 |
|---|---|---|---|
| MMMU | 50.7 | 58.6 | Qwen이 확연히 우세 |
| MathVista | 51.5 | 68.2 | 수학 시각 추론에서 큰 차이 |
| DocVQA | 88.4 | 95.7 | 문서 이해도 Qwen 우위 |
| AI2D | 91.1 | - | 다이어그램 이해 강점 |
| ChartQA | 83.4 | - | 차트 이해 양호 |
| MMLU | 73.0 | - | 텍스트 지식 수준 |
문제는 실사용 체감이다. Artificial Analysis 기준으로 Intelligence Index 9점으로, 같은 급 오픈 웨이트 모델 중앙값(12)보다 낮다. 출력 속도도 중앙값 48.1 t/s로 같은 급 중앙값(103.3 t/s)의 절반 수준이다 (출처: artificialanalysis.ai). 느리고, 벤치마크 점수 대비 실제 사용 시 환각이 잦다는 것이 사용자들의 공통된 반응이다.
특히 Qwen2.5-VL 7B와 비교하면 상황이 좋지 않다. 파라미터가 7B로 더 작은 Qwen 모델이 MMMU, MathVista, DocVQA에서 모두 이 모델을 앞선다 (출처: labellerr.com 비교 리뷰). 비전 분야에서 Llama 3.2 11B Vision은 출시 당시에는 "오픈 소스 최초의 멀티모달"이라는 의미가 있었지만, 후속 경쟁 모델들이 빠르게 추월한 상황이다.
장점은 AI2D 91.1점에서 보이듯 다이어그램/도표 이해에서는 아직 쓸만하다는 것, 그리고 가격이 압도적으로 저렴하다는 것이다. 단점은 환각이 잦고, 비전 작업에서 영어만 공식 지원하며, 수학적 시각 추론이 약하다는 것이다.
사용 방법
일반 사용자라면 Ollama를 통한 로컬 실행이 가장 접근하기 쉽다. Ollama 설치 후 터미널에서 ollama run llama3.2-vision:11b 명령으로 바로 실행 가능하다 (출처: ollama.com). 이미지 파일을 함께 첨부해서 질문하는 방식으로 사용한다.
개발자라면 API를 통한 연동이 가능하다. OpenRouter, DeepInfra, Amazon Bedrock, Azure, NVIDIA NIM 등 여러 프로바이더에서 호스팅하고 있으며, OpenAI 호환 API 엔드포인트를 제공한다 (출처: OpenRouter, DeepInfra 문서). HuggingFace Transformers 라이브러리에서도 직접 로드할 수 있다.
AWS Bedrock에서는 meta.llama3-2-11b-instruct-v1:0 모델 ID로 접근하며, NVIDIA NIM에서는 REST API를 통해 이미지와 텍스트를 함께 전송할 수 있다 (출처: AWS 블로그, NVIDIA NIM 문서).
공식 모델 카드와 사용 가이드는 HuggingFace(https://huggingface.co/meta-llama/Llama-3.2-11B-Vision-Instruct)와 Meta Llama 공식 사이트(https://www.llama.com/docs/how-to-guides/vision-capabilities/)에서 확인할 수 있다.
가격멀티모달 모델 중 가장 저렴한 축에 속한다.
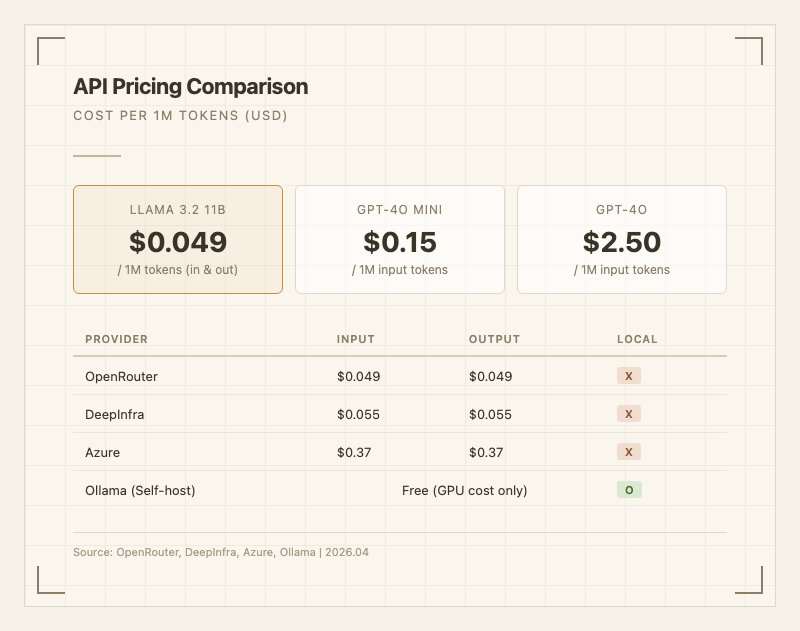
| 프로바이더 | Input ($/1M tokens) | Output ($/1M tokens) |
|---|---|---|
| OpenRouter | $0.049 | $0.049 |
| DeepInfra | $0.055 | $0.055 |
| Azure | $0.37 | $0.37 |
| Ollama (셀프호스트) | GPU 비용만 | GPU 비용만 |
(출처: OpenRouter, DeepInfra, Azure 공식 가격 페이지)
GPT-4o mini(2.50/1M input) 대비로는 50배 이상 차이가 난다. 대량 이미지 분류나 배치 처리 파이프라인에서 비용 압박 없이 사용할 수 있다.
실사용자들의 가성비 평가는 "GPT-4o에는 못 미치지만 가격을 고려하면 합리적"이라는 반응이 주류다 (출처: blog.getbind.co). 다만 Qwen2.5-VL 7B가 더 나은 성능을 비슷한 가격대에서 제공하면서, 순수 가성비 기준으로도 이 모델의 입지가 좁아졌다.
한국어 토큰 효율 데이터는 미공개 상태다. Llama 3.2는 tiktoken 기반 토크나이저를 사용하며, 한국어 문자가 영어 대비 2-3배 많은 토큰을 소모하는 것이 일반적이지만, 이 모델에 대한 구체적인 한국어 토큰 효율 벤치마크는 확인되지 않았다.
기술 사양
| 항목 | 값 |
|---|---|
| 파라미터 | 11B (약 10.6B) |
| 아키텍처 | Transformer + Cross-Attention Vision Adapter |
| 베이스 모델 | Llama 3.1 8B (텍스트 백본) |
| 이미지 인코더 | ViT-H/14 (사전학습) |
| 컨텍스트 윈도우 | 128K tokens (131,072) |
| 이미지 토큰 | 512x512 이미지 = 약 1,610 tokens |
| 어텐션 | Grouped-Query Attention (GQA) |
| 학습 데이터 기준일 | 2023년 12월 |
| 출시일 | 2024년 9월 25일 |
| 라이선스 | Llama Community License |
| 공식 지원 언어(텍스트) | 영어, 독일어, 프랑스어, 힌디어, 이탈리아어, 포르투갈어, 스페인어, 태국어 (8개) |
| 공식 지원 언어(비전) | 영어만 |
| 학습 방식 | 6B 이미지-텍스트 쌍 사전학습 + 3M 합성 데이터 SFT + DPO |
| 최소 VRAM | 8GB (양자화 기준, Ollama) |
(출처: HuggingFace Model Card, Meta AI Blog)

참고 자료






스펙
컨텍스트 윈도우
131K 토큰
라이선스
Llama Community License
출시일
2024년 9월 25일
학습 마감일
2023년 12월 31일
가성비 지수
90.3
API 가격 (혼합)
입력 $0.049/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.05 / 1M 토큰
출력 (Completion)
$0.05 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
멀티모달최강
63.3
이미지, 비디오 등 멀티모달 이해
수학/추론
42.3
수학, 과학, 논리적 추론
Provider
Meta
분류
시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)Multimodal TransformerVLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| AI2D | 91.1 | % |
| GPQA | 32.8 | % |
| MATH Lvl 5 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Llama 3.2 11B Vision Instruct | 41.5 |
| Qwen VL Max | - |
| Qwen3 VL 30B A3B Instruct | - |