Llama 3.1 8B Instruct
MetaLLM자연어 처리컴퓨터 비전오디오 처리128K 토큰
2024년 7월 23일Llama 3.1 Community License
Llama
3.1 8B Instruct란
Llama 3.1 8B Instruct는 Meta(구 Facebook)의 AI 연구 조직 FAIR에서 2024년 7월 23일 출시한 오픈 웨이트 대규모 언어 모델이다. Llama 3.1 시리즈(8B, 70B, 405B) 중 가장 작은 모델로, 8B(80억) 파라미터라는 경량 구조에서도 상당한 수준의 성능을 제공한다. "누구나 자기 컴퓨터에서 돌릴 수 있는 AI"라는 오픈소스 LLM의 취지에 가장 잘 부합하는 모델 중 하나이며, 파인튜닝 베이스 모델, 엣지 디바이스 배포, 대량 텍스트 처리 등 비용 효율이 중요한 시나리오에서 널리 사용된다.
주요 특징
Llama 3.1 8B Instruct의 핵심 차별점은 크게 네 가지로 요약할 수 있다.
첫째, 소비자급 하드웨어에서 실행 가능한 경량성이다. 8B 파라미터는 8GB VRAM GPU(RTX 3060, RTX 4060 등)에서 양자화 없이도 실행할 수 있는 크기이며, 4bit 양자화를 적용하면 라즈베리파이나 모바일 디바이스에서도 추론이 가능하다. r/LocalLLaMA 커뮤니티에서는 이 모델을 "소형 모델의 sweet spot"으로 부르며, 일반 소비자 GPU에서 약 55 tokens/sec의 속도를 달성한다고 보고한다.
둘째, 128K 토큰 컨텍스트 윈도우다. Llama 3의 8K에서 16배 확장되어 긴 문서, 코드베이스 분석, 다문서 요약 등에서 활용 범위가 크게 넓어졌다. 다만 실사용자들은 128K 풀 컨텍스트에서 성능 저하를 체감하기도 하며, 16K~32K 범위에서 가장 안정적이라는 의견이 많다.
셋째, 오픈 웨이트 공개로 자체 서버 호스팅 시 무료 무제한 사용이 가능하다. Llama 3.1 Community License 하에 상업적 이용도 허용되며, HuggingFace에서 가장 활발하게 파인튜닝되는 베이스 모델 중 하나다. 한국어 특화 파인튜닝(Bllossom, Open-Ko, linkbricks 등), 도메인 전문화, 양자화 배포 등 다양한 변형이 커뮤니티에서 만들어지고 있다.
넷째, 도구 사용(Tool Use) 기능 내장이다. API-Bank 82.6, BFCL 76.1 등 도구 사용 벤치마크에서 8B 크기 모델치고는 높은 점수를 기록하며, 함수 호출과 외부 API 연동이 가능하다.

할 수 있는 것
Llama 3.1 8B Instruct의 실제 활용 사례를 공식 문서와 커뮤니티 후기를 종합해 정리하면 다음과 같다.
일상 대화 및 텍스트 생성: r/LocalLLaMA 사용자들은 이 모델을 "일상적인 채팅과 글쓰기에 충분한 품질"이라고 평가한다. 이메일 작성, 브레인스토밍, 간단한 번역 등 가벼운 텍스트 작업에서 비용 대비 만족스러운 결과를 제공한다.
코딩 보조: HumanEval 72.6, MBPP++ 72.8로 기본적인 코드 생성과 디버깅을 처리할 수 있다. 다만 커뮤니티에서는 "간단한 스크립트나 보일러플레이트는 잘 생성하지만, 복잡한 알고리즘이나 대규모 리팩토링은 70B 이상 모델이 필요하다"는 의견이 지배적이다.
수학적 추론: GSM8K 84.5로 기초~중급 수학 문제 풀이에 강하다. 다만 MATH Lvl 5(고난도 수학)에서는 25.4에 그쳐, 경쟁 과목 수준의 수학 추론에는 한계가 있다.
파인튜닝 베이스 모델: 이 모델의 가장 강력한 활용처 중 하나다. 의료, 법률, 금융 등 특정 도메인에 맞춤화된 전문 모델을 만들 때 70B나 405B를 파인튜닝하기에는 GPU 비용이 과도하므로, 8B를 파인튜닝해서 도메인 전문 모델을 만드는 패턴이 실무에서 보편적이다.
대량 텍스트 분류 및 전처리: API 비용이 1M 입력 토큰당 $0.02(OpenRouter 기준)로 극도로 저렴하기 때문에, 수만~수십만 건의 텍스트를 분류하거나 구조화하는 배치 작업에 적합하다.
엣지 디바이스 배포: 4bit 양자화 시 약 4GB로 모바일, IoT 디바이스, 내장 시스템에서 로컬 추론이 가능하다. 인터넷 연결 없이 온디바이스 AI가 필요한 시나리오에서 활용된다.
반면 "이건 안 된다"는 의견도 명확하다. 복잡한 멀티스텝 추론, 전문적인 논문 작성, 실시간 에이전트 태스크 등은 70B 이상 모델에 맡기는 것이 현실적이다. 이미지/비디오 처리는 지원하지 않는 텍스트 전용 모델이다.
성능
벤치마크 점수
| 벤치마크 | 점수 | 비고 |
|---|---|---|
| MMLU (5-shot) | 69.4 | (출처: Meta 공식) |
| MMLU-PRO (5-shot CoT) | 48.3 | (출처: Meta 공식) |
| GPQA (0-shot) | 30.4 | (출처: Meta 공식) |
| IFEval | 80.4 | (출처: Meta 공식) |
| HumanEval (0-shot) | 72.6 | (출처: Meta 공식) |
| GSM8K (8-shot CoT) | 84.5 | (출처: Meta 공식) |
| MATH (0-shot CoT) | 51.9 | (출처: Meta 공식) |
| MATH Lvl 5 | 25.4 | (출처: Meta 공식) |
| ARC-C (0-shot) | 83.4 | (출처: Meta 공식) |
| API-Bank (Tool Use) | 82.6 | (출처: Meta 공식) |
| BFCL (Tool Use) | 76.1 | (출처: Meta 공식) |
경쟁 모델 비교
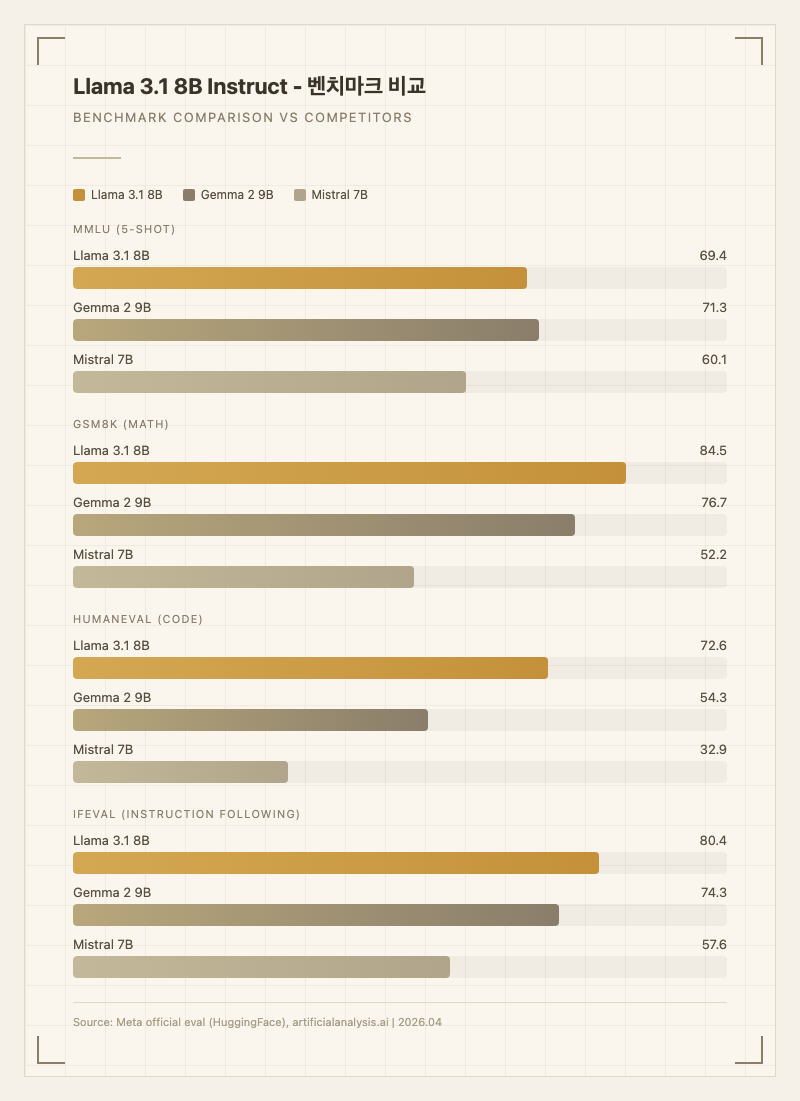
같은 크기대의 오픈 웨이트 모델인 Gemma 2 9B, Mistral 7B와 비교하면, Llama 3.1 8B는 GSM8K(84.5 vs 76.7 vs 52.2)와 HumanEval(72.6 vs 54.3 vs 32.9)에서 확실한 우위를 보인다. 반면 MMLU에서는 Gemma 2 9B(71.3)에 근소하게 뒤진다(69.4). Mistral 7B 대비로는 전 영역에서 우위다.
Artificial Analysis Intelligence Index 기준 점수 12로, 같은 크기대 비추론 오픈 웨이트 모델 중 평균 이상에 위치한다. 추론 속도는 프로바이더 중앙값 155 t/s로 비슷한 크기 모델 중앙값(98 t/s)을 크게 상회한다.
실사용 체감으로는, r/LocalLLaMA에서 "일상 작업에서는 GPT-3.5 Turbo와 비슷하거나 약간 나은 수준"이라는 평가가 많다. 코딩은 전용 모델(DeepSeek Coder, Qwen Coder 등)에 비하면 아쉽지만, 범용 작업에서는 가성비가 뛰어나다는 의견이 주류다. 반대로 "GPQA 30.4는 전문 지식 질의에서 한계가 명확하다", "벤치마크와 달리 복잡한 지시를 여러 번 반복해야 제대로 따르는 경우가 있다"는 불만도 존재한다.
사용 방법
웹/앱 (일반인)
Llama 3.1 8B Instruct는 오픈 웨이트 모델이므로 Meta 자체 웹 서비스가 아닌 다양한 서드파티 플랫폼에서 이용 가능하다.
- Ollama(ollama.com):
ollama run llama3.1:8b명령어로 로컬 설치 후 터미널에서 바로 대화 가능 - HuggingFace Chat: 웹 브라우저에서 바로 테스트 가능 (huggingface.co/chat)
- NVIDIA NIM: build.nvidia.com에서 데모 실행 가능
- Groq, Together AI, OpenRouter 등 API 프로바이더의 Playground에서 무료 테스트 가능
API 연동 (개발자)
OpenRouter, Together AI, Groq, Amazon Bedrock, Azure AI 등 다수의 프로바이더에서 API로 제공한다. OpenAI 호환 API 형식을 사용하므로 기존 코드에서 엔드포인트와 모델명만 변경하면 바로 적용 가능하다.
자체 호스팅을 원할 경우 vLLM, TensorRT-LLM, llama.cpp 등으로 서빙할 수 있다. HuggingFace에서 모델 웨이트를 다운로드한 후 로컬 GPU 서버에 배포하는 방식이다.
가격
Llama 3.1 8B Instruct는 오픈 웨이트 모델이므로 자체 호스팅 시 무료다. API로 사용할 경우 프로바이더마다 가격이 다르다.
| 프로바이더 | 입력 / 1M tokens | 출력 / 1M tokens |
|---|---|---|
| OpenRouter | $0.02 | $0.05 |
| Groq | $0.05 | $0.08 |
| Cerebras | $0.10 | $0.10 |
| SambaNova | $0.10 | $0.10 |
| Together AI | $0.18 | $0.18 |
| Amazon Bedrock | $0.22 | $0.22 |
프로바이더 중앙값은 입력 0.10 per 1M tokens이다 (출처: artificialanalysis.ai).
커뮤니티 가성비 평가는 "이 가격에 이 성능이면 거의 공짜"라는 반응이 지배적이다. 특히 대량 배치 처리, 개발 프로토타이핑, 학습 목적에서는 사실상 비용 걱정이 필요 없는 수준이다. 다만 "싸니까 Llama 8B 쓰다가 결과물 품질에 실망해서 결국 70B로 올렸다"는 후기도 자주 보인다. 비용만 보고 선택하기보다 태스크 난이도에 맞는 모델 크기를 선택하는 것이 중요하다.
한국어 토큰 효율은 공식 데이터 미공개 상태다. Llama 3.1의 토크나이저(128K vocab, BBPE)에는 한국어 토큰이 약 1,000개만 포함되어 있어, 한국어 텍스트는 영어 대비 약 23배 더 많은 토큰으로 분해된다. 이는 동일한 한국어 문장을 처리할 때 비용이 영어 대비 23배 더 발생할 수 있음을 의미한다. Bllossom, Open-Ko 등 한국어 특화 파인튜닝 버전에서는 어휘 확장을 통해 이 문제를 부분적으로 해결하고 있다.

기술 사양
| 항목 | 사양 |
|---|---|
| 개발사 | Meta (FAIR) |
| 출시일 | 2024년 7월 23일 |
| 파라미터 수 | 8B (80억) |
| 아키텍처 | Transformer (auto-regressive) + Grouped-Query Attention (GQA) |
| 컨텍스트 윈도우 | 128,000 tokens |
| 학습 데이터 | ~15T tokens (공개 데이터) |
| 파인튜닝 방법 | SFT + RLHF (25M+ 합성 예제 포함) |
| 학습 마감일 | 2023년 12월 |
| 토크나이저 | 128,000 vocab (BBPE), 한국어 ~1,000 토큰 |
| 지원 언어 | 영어, 독일어, 프랑스어, 이탈리아어, 포르투갈어, 힌디어, 스페인어, 태국어 (한국어 비공식) |
| 라이선스 | Llama 3.1 Community License (상업적 이용 가능) |
| 멀티모달 | 텍스트 전용 (이미지/비디오 미지원) |

참고 자료



스펙
컨텍스트 윈도우
128K 토큰
라이선스
Llama 3.1 Community License
출시일
2024년 7월 23일
학습 마감일
2023년 12월 31일
가성비 지수
107.9
API 가격 (혼합)
입력 $0.020/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.02 / 1M 토큰
출력 (Completion)
$0.05 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
80.4
복잡한 지시사항 이해 및 수행
코딩
72.6
코드 생성, 버그 수정, 소프트웨어 엔지니어링
일반지식
48.3
다양한 분야 지식 및 이해
Provider
Meta
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 42.8
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GPQA | 30.4 | % |
| GSM8K | 84.5 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Llama 3.1 8B Instruct | 42.8 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |