Gemini 2.0 Flash
GoogleLLM자연어 처리컴퓨터 비전오디오 처리1.0M 토큰
2025년 2월 6일Proprietary
한줄 소개
Gemini 2.0 Flash는 Google DeepMind가 만든 초경량 멀티모달 모델로, 가격 대비 성능에서 업계 최고 수준의 효율을 보여주는 모델이다. 2025년 2월 GA(정식 출시)되었으며, 2026년 6월 1일 서비스 종료가 예정되어 있다.
주요 특징
Gemini 2.0 Flash의 핵심은 "싸고 빠르고 꽤 똑똑하다"로 요약된다. 구체적으로 다음 5가지가 차별점이다.
- 1M 토큰 컨텍스트 윈도우: 경쟁 모델 대비 압도적이다. GPT-4o의 128K, Claude 3.5 Sonnet의 200K와 비교하면 5~8배 이상 긴 컨텍스트를 한 번에 넣을 수 있다. 책 한 권, 대규모 코드베이스를 통째로 프롬프트에 넣는 것이 가능하다.
- 250 tokens/sec 출력 속도: Gemini 1.5 Flash 대비 2배 빠르다. Vertex AI 기준 TTFT(첫 토큰까지 시간)가 0.46초로 측정된다 (출처: artificialanalysis.ai). GPT-4o의 116 t/s, Claude 3.5 Sonnet의 81 t/s를 크게 앞선다.
- 진짜 멀티모달: 텍스트, 이미지, 오디오, 비디오 4가지 모달리티를 입력으로 받고, 텍스트와 이미지를 출력한다. 경쟁 모델들이 텍스트+이미지 입력에 그치는 것과 비교하면 활용 범위가 넓다.
- 네이티브 도구 호출: Function calling, Google 검색 그라운딩, 코드 실행이 모델 레벨에서 기본 지원된다. 별도 프레임워크 없이도 에이전트 파이프라인 구성이 가능하다.
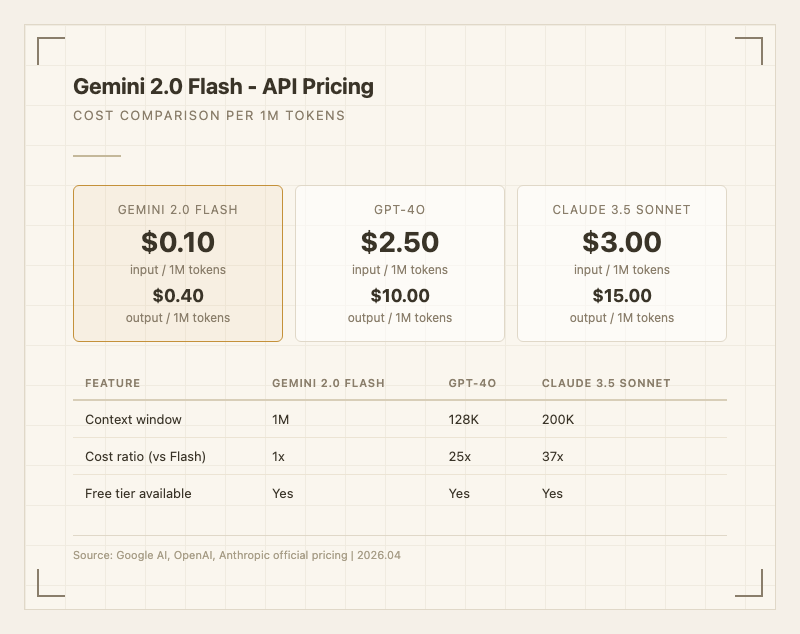
- 업계 최저 가격: 입력 0.40/1M 토큰. GPT-4o 대비 25배, Claude 3.5 Sonnet 대비 37배 저렴하다.
실사용자 반응을 보면, "번역용으로만 쓰던 제미나이가 이제는 어느 정도 이해를 하며 통찰력을 보여준다"는 평가가 한국 커뮤니티에서 나왔다. 다만 응답이 중간에 끊기는 버그가 개발자 포럼에서 수개월째 보고되고 있어, 프로덕션 안정성에 대한 우려도 존재한다.

할 수 있는 것
Gemini 2.0 Flash는 가격이 워낙 싸서 "대량 처리"가 핵심 유스케이스다. 실제로 사용자들이 해본 것과 공식 사례를 종합하면 다음과 같다.
- 대량 문서 분류/요약: 이메일 자동 분류, 고객 문의 라우팅, 콘텐츠 태깅 등 건당 비용이 중요한 작업에서 압도적이다. 1M 토큰 컨텍스트 덕분에 긴 문서도 잘라서 넣을 필요 없이 통째로 처리 가능하다.
- 실시간 채팅봇: 250 t/s의 속도와 낮은 TTFT로 실시간 대화 서비스에 적합하다. Google 검색 그라운딩을 켜면 최신 정보 기반 답변도 가능하다.
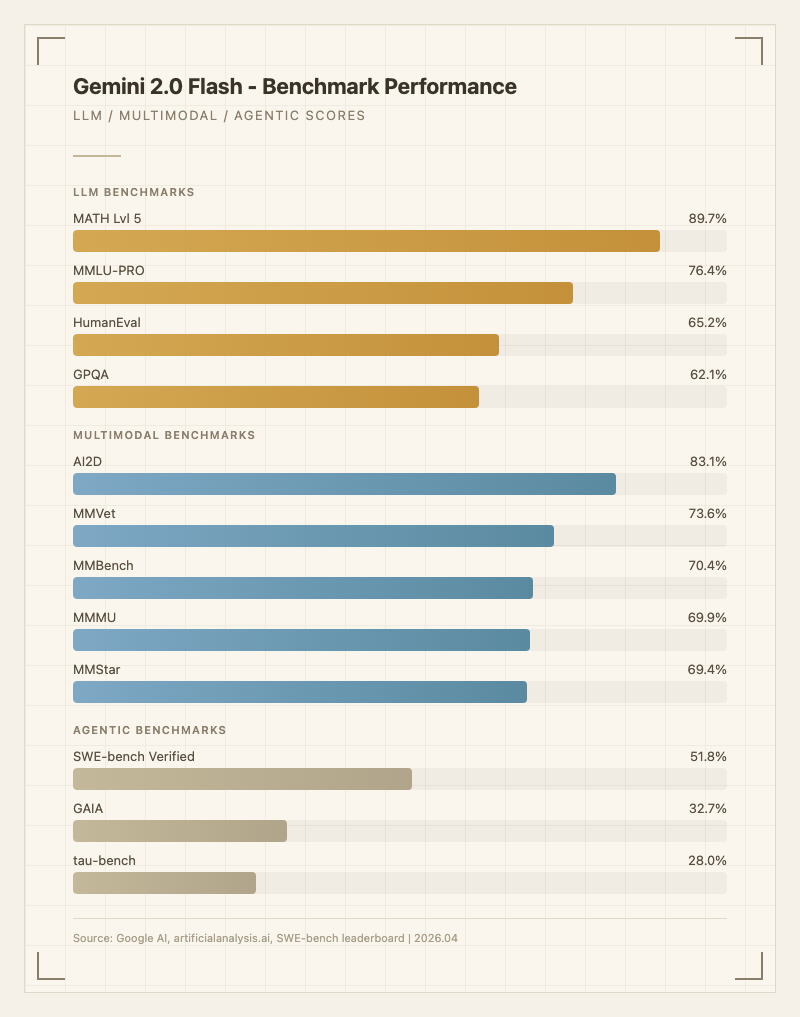
- 멀티모달 이해: 이미지 속 텍스트 추출(OCR), 비디오 내용 요약, 오디오 트랜스크립션 등을 단일 API로 처리한다. AI2D 83.1%로 다이어그램/차트 이해가 특히 강하다 (출처: Google AI 공식 벤치마크).
- 코딩 보조: HumanEval 65.2%로 기본적인 코드 생성은 가능하지만, Claude 3.5 Sonnet(92%)이나 GPT-4o(94%)에 비하면 코딩 전용으로 쓰기에는 부족하다.
- 간단한 에이전트 작업: SWE-bench Verified 51.8%로 코드 실행 도구와 결합하면 기본적인 소프트웨어 엔지니어링 태스크 수행이 가능하다 (출처: Google Developers Blog). 다만 복잡한 에이전틱 워크플로우에서는 한계가 명확하다.
반면 "이건 안 된다" 영역도 있다. 복잡한 추론이 필요한 과학 문제(GPQA 62.1%)나 고난도 코딩, 장시간 다단계 에이전트 작업에서는 프리미엄 모델에 크게 밀린다. Reddit에서는 "싸서 좋지만 어려운 건 못 한다"는 평이 지배적이다.
성능벤치마크 수치와 실사용 체감을 함께 정리한다.
LLM 벤치마크
| 벤치마크 | 점수 | 출처 |
|---|---|---|
| MATH Lvl 5 | 89.7% | Google AI 공식 |
| MMLU-PRO | 76.4% | Google AI 공식 |
| HumanEval | 65.2% | Google AI 공식 |
| GPQA | 62.1% | Google AI 공식 |
멀티모달 벤치마크
| 벤치마크 | 점수 | 출처 |
|---|---|---|
| AI2D | 83.1% | Google AI 공식 |
| MMVet | 73.6% | Google AI 공식 |
| MathVista | 70.4% | Google AI 공식 |
| MMBench | 70.4% | Google AI 공식 |
| MMMU | 69.9% | Google AI 공식 |
| MMStar | 69.4% | Google AI 공식 |
| HallusionBench | 58.0% | Google AI 공식 |
Agentic 벤치마크
| 벤치마크 | 점수 | 출처 |
|---|---|---|
| SWE-bench Verified | 51.8% | Google Developers Blog |
| GAIA | 32.7% | HAL 리더보드 |
| tau-bench | 28.0% | HAL 리더보드 |
| SWE-bench Bash-Only | 13.52% | SWE-bench 리더보드 |
MATH Lvl 5에서 89.7%는 가격 대비 놀라운 수준이다. 수학 추론에서는 프리미엄 모델에 근접하는 성능을 보인다. 반면 GPQA 62.1%는 과학 추론에서 한계가 있음을 보여주고, HumanEval 65.2%는 코딩 전용으로는 부족하다는 것을 뜻한다.
실사용 체감으로는, 벤치마크 수치 이상으로 속도가 체감 만족도를 높인다. "정확도는 80점짜리인데 속도가 100점이라 체감 만족도는 높다"는 의견이 개발자 커뮤니티에서 자주 보인다. 다만 응답이 문장 중간에 멈추는 버그가 GitHub Issues와 개발자 포럼에서 수개월째 보고되고 있어, 이 부분은 프로덕션 환경에서 리스크로 작용한다.
Artificial Analysis Intelligence Index 기준 종합 점수 19점으로, 동급 모델 평균(15점)을 상회한다 (출처: artificialanalysis.ai).
사용 방법
일반 사용자
- Gemini 앱 (gemini.google.com): 웹 브라우저나 모바일 앱에서 무료로 사용 가능하다. Google 계정만 있으면 된다.
- Google AI Studio (aistudio.google.com): 프롬프트 테스트와 프로토타이핑을 위한 무료 웹 인터페이스. API 키 발급도 여기서 가능하다.
개발자
- Gemini API (ai.google.dev): REST API 또는 공식 SDK(Python, Node.js, Go, Dart 등)로 연동. 모델 ID는
gemini-2.0-flash-001. - Vertex AI (cloud.google.com/vertex-ai): 엔터프라이즈 환경에서는 Vertex AI를 통해 접근하며, Provisioned Throughput과 VPC 네트워크 등 프로덕션 기능을 지원한다.
- OpenRouter 등 서드파티 프로바이더에서도 접근 가능하다.
주의: 2026년 3월 6일부터 신규 사용자에게는 제공되지 않으며, 기존 사용자만 이용 가능하다. 2026년 6월 1일 완전 종료 예정이므로 신규 프로젝트에서는 Gemini 2.5 Flash 이상을 사용하는 것을 권장한다.
가격
API 가격
- 입력: $0.10 / 1M 토큰
- 출력: $0.40 / 1M 토큰
- 긴 컨텍스트와 짧은 컨텍스트 구분 없이 단일 가격 적용 (Gemini 1.5 Flash에서는 구분이 있었음)
경쟁 모델 대비
GPT-4o(입력 10.00)와 비교하면 입력 25배, 출력 25배 저렴하다. Claude 3.5 Sonnet(입력 15.00)과 비교하면 입력 30배, 출력 37배 저렴하다. 대량 호출이 필요한 프로덕션 환경에서 비용 차이가 극적으로 벌어진다.
무료 티어
Google AI Studio에서 분당 15회 요청, 일일 150만 토큰까지 무료로 사용할 수 있다.
한국어 토큰 효율
Gemini의 토크나이저는 CJK(한중일) 문자를 작은 서브워드 단위로 분해하는 경향이 있어, 영어 대비 토큰 소모량이 높다. 구체적인 한국어 토큰 효율 수치는 미공개이나, 일본어 기준 0.82 characters/token으로 측정된 데이터가 있어 한국어도 유사한 수준으로 추정된다 (출처: apiyi.com 토크나이저 비교). 같은 내용의 한국어 텍스트가 영어보다 토큰을 더 많이 소모하므로, 한국어 중심 서비스에서는 실제 비용이 표시 가격보다 높아질 수 있다.
기술 사양
| 항목 | 사양 |
|---|---|
| 제공사 | Google DeepMind |
| 모델 ID | gemini-2.0-flash-001 |
| 출시일 | 2025년 2월 5일 (GA) |
| 컨텍스트 윈도우 | 1,048,576 토큰 (1M) |
| 최대 출력 | 8,192 토큰 |
| 학습 데이터 기준일 | 2024년 8월 |
| 입력 모달리티 | 텍스트, 이미지, 오디오, 비디오 |
| 출력 모달리티 | 텍스트, 이미지 |
| 라이선스 | Proprietary |
| 파라미터 수 | 미공개 |
| 아키텍처 | Transformer (MoE 추정, 미공개) |
| API 가격 (입력) | $0.10 / 1M 토큰 |
| API 가격 (출력) | $0.40 / 1M 토큰 |
| 서비스 종료일 | 2026년 6월 1일 |

참고 자료





스펙
컨텍스트 윈도우
1.0M 토큰
라이선스
Proprietary
출시일
2025년 2월 6일
학습 마감일
2024년 8월 31일
가성비 지수
14.8
API 가격 (혼합)
입력 $0.100/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.10 / 1M 토큰
출력 (Completion)
$0.40 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
일반지식최강
76.4
다양한 분야 지식 및 이해
수학/추론
75.9
수학, 과학, 논리적 추론
멀티모달
73.3
이미지, 비디오 등 멀티모달 이해
Provider
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Gemini 2.0 Flash | 74.1 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |