Auto Research vs AutoML: 코딩이면 Auto Research, 파라미터 튜닝이면 AutoML
결론부터 말하면, Auto Research는 AutoML의 상위 호환이 아니다. 완전히 다른 카테고리의 도구다. AutoML이 "사전에 정의된 탐색 공간 안에서 최적 파라미터를 찾는 자동화"라면, Auto Research는 "LLM이 스스로 가설을 세우고 코드를 작성하고 실험을 반복하는 자율 연구"다. 2026년 3월 Andrej Karpathy가 630줄짜리 Python 스크립트 하나로 하룻밤 동안 50개 실험을 자동 실행한 AutoResearch를 공개하면서, 이 차이가 업계에서 본격적으로 논의되기 시작했다. 학습 전략을 바꾸거나 Flash Attention 같은 아키텍처 변경을 시도하는 것은 AutoML의 탐색 공간에는 존재하지 않는 영역이다. 반면, 이미 검증된 파이프라인에서 learning rate를 0.001로 할지 0.003으로 할지 빠르게 정해야 하는 프로덕션 환경에서는 AutoML이 여전히 정답이다.
한눈에 보는 비교
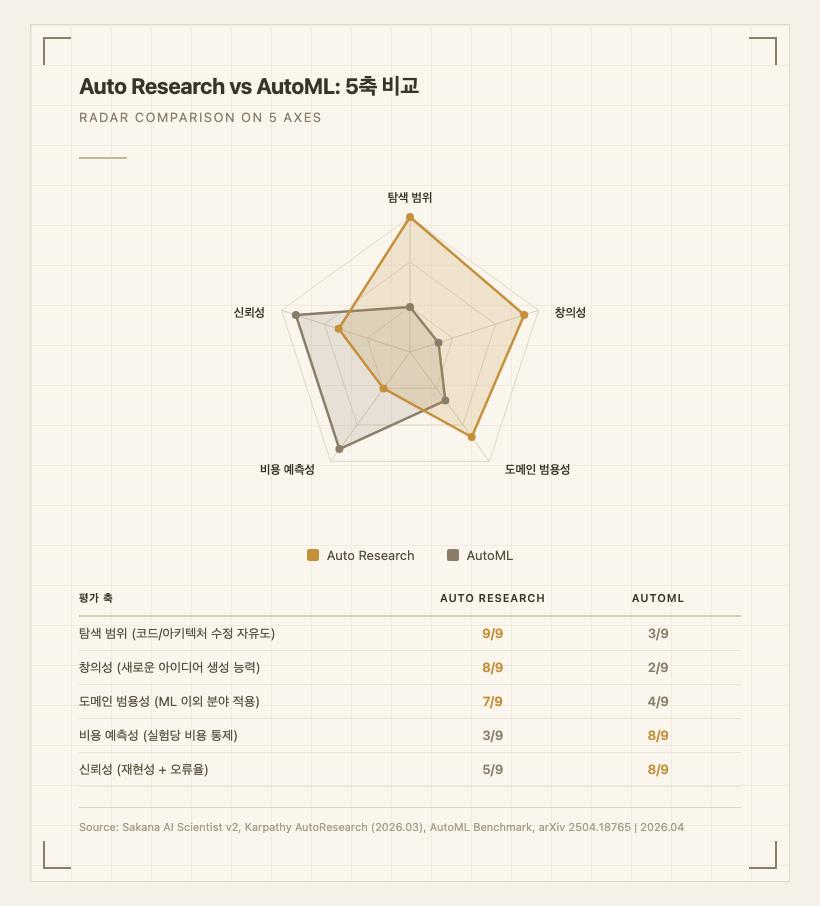
위 레이더 차트는 5개 축에서 Auto Research와 AutoML의 강약 패턴을 보여준다. 각 축의 점수 산출 근거는 다음과 같다.
탐색 범위 - Auto Research 9/9 vs AutoML 3/9. AutoML(Optuna, Ray Tune, Auto-Keras 등)은 사용자가 trial.suggest_float("lr", 1e-5, 1e-2) 같은 형태로 미리 정해준 파라미터 공간만 탐색한다. Auto Research는 LLM이 train.py 파일 자체를 수정하기 때문에 optimizer 변경, 새로운 regularization 기법 도입, 심지어 모델 아키텍처 재설계까지 시도할 수 있다. Karpathy의 AutoResearch는 실제로 하룻밤 실험에서 Cosine Annealing 도입, Gradient Clipping 추가, Muon optimizer 적용 등 코드 수준 변경을 자율적으로 수행했다. (출처: Karpathy GitHub, MarkTechPost 2026.03)
창의성 - Auto Research 8/9 vs AutoML 2/9. AutoML의 탐색 알고리즘(베이지안 최적화, 유전 알고리즘)은 주어진 공간 내에서 효율적으로 탐색하지만, "Gradient Clipping을 추가하면 어떨까?"라는 아이디어를 생성하지 못한다. Auto Research의 LLM은 수백만 논문의 지식을 바탕으로 새로운 조합을 제안한다. EvoScientist(2026.03)는 자동 생성 아이디어의 참신성(novelty)에서 7개 기존 시스템을 초과했다는 벤치마크 결과를 보고했으며, DeepResearch Bench II와 AstaBench에서 1위를 기록했다. (출처: arXiv 2603.08127)
도메인 범용성 - Auto Research 7/9 vs AutoML 4/9. AutoML은 ML 파이프라인(분류, 회귀, NAS)에 특화되어 있다. Auto Research 시스템은 ML 이외 분야에서도 작동한다. Kosmos(2025.11)는 데이터셋과 목표만 주면 12시간 동안 200개 에이전트 롤아웃을 실행하면서 평균 42,000줄의 코드를 실행하고 1,500편의 논문을 읽었다. 독립 과학자 평가에서 Kosmos 보고서 내 진술의 79.4%가 정확하다고 판정했다. (출처: arXiv 2511.02824)
비용 예측성 - Auto Research 3/9 vs AutoML 8/9. AutoML은 trial 수와 GPU 시간을 사전에 정할 수 있어 비용이 예측 가능하다. Auto Research는 LLM API 호출 비용이 실험 복잡도에 따라 크게 변동한다. Karpathy 루프는 실험당 정확히 5분으로 시간을 고정해서 이 문제를 부분적으로 해결했지만, LLM 토큰 소비량은 실험마다 다르다.
신뢰성 - Auto Research 5/9 vs AutoML 8/9. AutoML은 deterministic 알고리즘 기반으로 동일 입력에 동일 결과를 보장한다. Auto Research의 LLM은 비결정론적(non-deterministic)이라 같은 가설이 매번 다른 코드를 생성한다. Sakana AI Scientist v2의 독립 평가에서 42%의 실험이 코딩 오류로 실패했다는 결과가 보고되었다. 또한 잘 알려진 기법(예: SGD 미니배치)을 "새로운 아이디어"로 잘못 분류하는 참신성 평가 오류도 확인되었다. (출처: arXiv 2502.14297)
항목별 상세 비교
작동 방식: 탐색 공간 vs 자유 코드 수정
AutoML의 핵심은 사전 정의된 탐색 공간(search space) 내 최적화다. 사용자가 batch_size를 [16, 32, 64, 128] 중에서 고르도록 정하면, 베이지안 최적화나 TPE(Tree-structured Parzen Estimator)가 그 범위 안에서 최적값을 찾는다. 이 방식은 탐색 공간 정의만 잘하면 안정적이지만, 탐색 공간 밖의 해결책은 영원히 찾지 못한다.
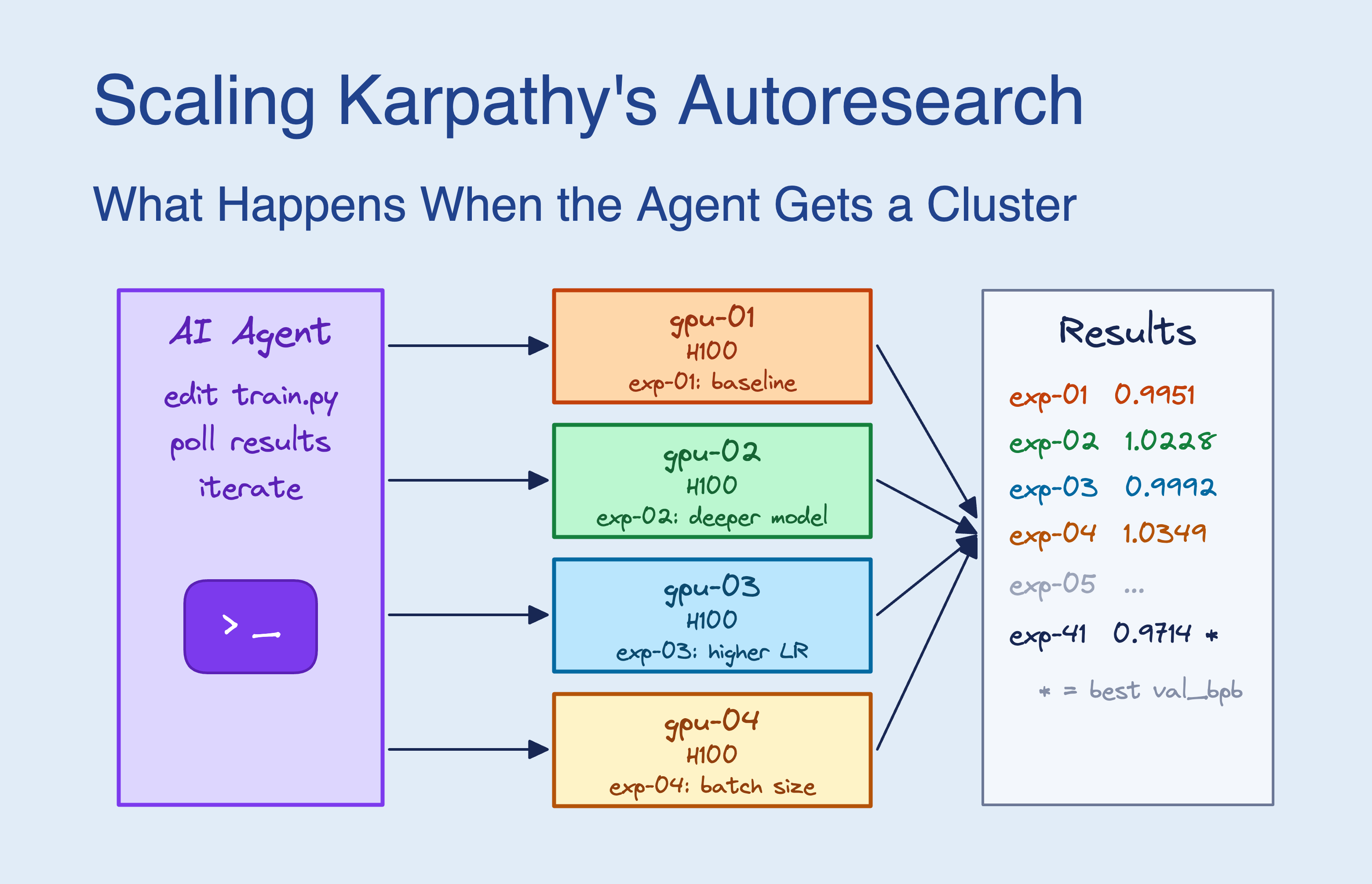
Auto Research는 LLM에게 train.py 같은 단일 파일을 통째로 수정할 권한을 준다. Karpathy의 AutoResearch에서 에이전트는 program.md 파일의 지시를 읽고, 코드를 수정하고, 5분간 학습을 돌리고, validation loss가 개선되면 커밋하는 루프를 반복한다. 이 "래칫(ratchet) 루프"에서 loss가 악화된 변경은 자동으로 폐기되고, 개선된 변경만 누적된다. 시간당 약 12개 실험, 하룻밤이면 약 100개 실험이 가능하다. (출처: The New Stack, DataCamp 2026.03)
실무적 차이는 크다. AutoML에게 "Flash Attention을 적용해봐"라고 요청할 방법은 없다. 하지만 Auto Research의 LLM은 GPU 메모리 부족 에러를 보고 스스로 Flash Attention 코드를 작성하는 것이 가능하다.
연구 자동화 범위: 파라미터 최적화 vs 논문 작성
AutoML이 담당하는 영역은 ML 워크플로우의 마지막 10-18%에 해당한다. Delphina의 분석에 따르면, 데이터 과학자가 모델 선택과 학습에 쏟는 시간은 전체의 18%에 불과하며, 나머지 82%는 문제 정의, 데이터 전처리, 피처 엔지니어링, 결과 해석에 사용된다. AutoML은 이 18%를 자동화하고, 나머지는 건드리지 않는다. (출처: Delphina "Why AutoML Failed to Live Up to the Hype")
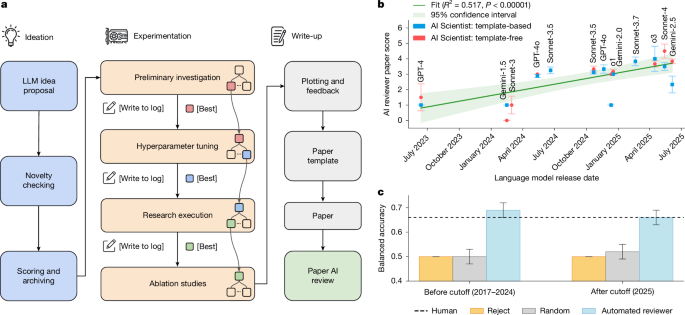
Auto Research 시스템들은 연구 전체 라이프사이클을 자동화하려 한다. AI Scientist v2(Sakana AI, 2025.04)는 아이디어 생성부터 코드 작성, 실험, 논문 작성, 자동 리뷰까지 수행한다. 실제로 3편의 완전 자율 논문을 ICLR 워크숍에 제출했고, 그 중 1편은 평균 리뷰어 점수 6.33을 받아 상위 45%에 해당하는 수준을 달성했다. 이 논문이 인간이 작성한 것이었다면 수락되었을 것이라는 평가를 받았으며, 이것은 완전 AI 생성 논문이 피어리뷰를 통과한 최초 사례로 기록되었다. 이 연구는 2026년 3월 Nature에도 게재되었다. (출처: Sakana AI Scientist v2 Paper, Nature 2026.03)
AI-Researcher(NeurIPS 2025 Spotlight)는 문헌 리뷰부터 알고리즘 구현, 출판 가능 수준의 원고 작성까지 최소한의 인간 개입으로 수행하는 시스템이다. EvoScientist(2026.03)는 여기에 진화적 자기개선을 더했다. Researcher Agent, Engineer Agent, Evolution Manager Agent 3개의 에이전트와 6개의 서브 에이전트가 협력하며, 이전 실험에서 배운 전략을 영구 메모리에 저장해 다음 실험에 재활용한다. (출처: arXiv 2603.08127, arXiv 2505.18705)
비용 구조: 예측 가능한 GPU vs GPU + LLM API

AutoML의 비용은 GPU 컴퓨팅에 집중된다. 100회 trial을 A100에서 돌리면 대략 $3-8 수준이고, trial 수를 늘려도 선형적으로 예측 가능하다. 숨겨진 비용이 거의 없다.
Auto Research는 GPU 비용에 LLM API 비용이 추가된다. Karpathy 루프에서 각 실험마다 LLM이 코드를 분석하고 수정 방향을 제안하고 코드를 생성하는 과정에서 수천-수만 토큰을 소비한다. 하룻밤 100회 실험이면 GPT-4o 기준 대략 50-200 수준으로 추정된다.
반면, AutoML이 아예 할 수 없는 작업(아키텍처 탐색, 전체 연구 자동화)에서는 비용 비교 자체가 성립하지 않는다. 인간 연구자가 동일 작업을 수행하는 비용과 비교해야 한다. Kosmos의 독립 평가에서 협력 연구자들은 "단일 20사이클 실행이 자신들의 평균 6개월 연구량에 해당한다"고 보고했는데, 이를 연구원 인건비로 환산하면 Auto Research의 $50-200은 파격적으로 저렴한 셈이다.
한국어 사용자 관련 참고
Auto Research와 AutoML 모두 한국어 사용자에게 특별한 장벽이 있지는 않다. AutoML 도구(Optuna, Auto-Keras, H2O)는 글로벌 오픈소스 프로젝트로 한국어 문서화는 제한적이지만, API 자체가 언어 무관하다. Auto Research 시스템의 경우, LLM이 영어 논문 지식을 기반으로 작동하므로 program.md를 영어로 작성하는 것이 권장된다. Karpathy의 AutoResearch는 MIT 라이센스 오픈소스로 국내에서도 바로 사용 가능하다. 국내 Auto Research 활용 사례는 2026년 4월 현재 공개적으로 확인된 것이 없다.
실사용자는 뭐라고 하나
Reddit r/MachineLearning 커뮤니티 반응. Karpathy의 AutoResearch 공개 직후 Reddit에서 상당한 논의가 이루어졌다. SkyPilot 블로그에서는 "단일 GPU 제약을 벗어나 GPU 클러스터로 확장하면 어떻게 되는가"를 실험해서 공유했다. 핵심 반응은 "5분 고정 시간이 실험 간 공정한 비교를 가능하게 한다"는 점에 대한 긍정과, "5분으로는 대형 모델 실험이 불가능하다"는 한계 지적이 공존했다. (출처: SkyPilot Blog, Reddit)
AI Scientist에 대한 학계 반응. Sakana AI Scientist v2가 ICLR 워크숍 피어리뷰를 통과한 것에 대해, arXiv에 독립 평가 논문(2502.14297)이 제출되었다. 제목 자체가 "Bold Claims, Mixed Results, and a Promising Future?"로, 기대와 우려를 동시에 반영한다. 독립 평가자들은 42% 실험 실패율, 문헌 리뷰의 표면적 키워드 검색 의존, 참신성 평가 오류를 지적했다. 하지만 "이 방향 자체가 유망하며 앞으로 빠르게 개선될 것"이라는 전망도 제시했다. (출처: arXiv 2502.14297, ACM SIGIR Forum)
AutoML 회의론. Delphina의 "Why AutoML Failed to Live Up to the Hype" 분석에서는 AutoML이 ML 워크플로우의 극히 일부만 자동화하며, 실제 데이터 과학자의 업무에서 차지하는 비중이 제한적이라는 점을 지적했다. Google AutoML에 대해서도 "학술 연구실이 영리 기업에 내장되면서, 실제 필요를 충족하는지보다 연구 결과를 제품화하려는 유인이 작동한다"는 비판이 있었다. HBR도 "AutoML의 리스크"를 다루며 블랙박스 특성과 과적합 위험을 경고했다. (출처: Delphina Blog, Harvard Business Review, fast.ai)
누가 뭘 쓰면 되나 (Editor's Pick)

명확한 승자 선언: 연구자라면 Auto Research, 엔지니어라면 AutoML. 이 둘은 경쟁 관계가 아니라 상호 보완 관계다.
하이퍼파라미터 튜닝이 목적이면 AutoML이 정답이다. Optuna, Ray Tune, Auto-Keras 같은 도구는 10년 이상 검증된 알고리즘을 사용하고, 결과가 재현 가능하며, CI/CD 파이프라인에 통합하기 쉽다. LLM을 끌어다 쓸 이유가 없다.
"지금 돌리는 모델을 더 잘 학습시킬 방법이 없을까?"라는 질문에는 Auto Research가 답한다. AutoML의 탐색 공간에 없는 아이디어, 예를 들어 새로운 optimizer 조합, data augmentation 전략, 아키텍처 변형 등을 LLM이 제안하고 직접 실험한다.
논문급 연구 자동화를 원한다면 Auto Research 진영의 시스템(AI Scientist v2, EvoScientist, Kosmos)을 검토하라. 다만 현재 42% 실험 실패율과 참신성 평가 오류가 존재하므로, 인간 감수(human-in-the-loop) 없이 결과를 그대로 제출하는 것은 권장하지 않는다.
프로덕션 MLOps 환경에서는 AutoML을 유지하라. LLM의 비결정론적 특성은 프로덕션 환경에서 감사 추적(audit trail)과 재현성 요구사항을 충족하기 어렵다.
예외: 스타트업이나 해커톤에서는 둘을 병행하는 전략이 유효하다. AutoML로 baseline을 빠르게 잡고, Auto Research로 차별화 실험을 병행하면 최소 비용으로 최대 탐색 범위를 확보할 수 있다.
6개월 후 재평가이 비교가 뒤집힐 수 있는 조건 3가지:
1. LLM 추론 비용이 10배 이상 하락하는 경우. 현재 Auto Research의 약점인 비용 예측성이 크게 개선된다. GPT-4o급 모델의 API 비용이 1-3 수준으로 떨어져 AutoML과 비용 차이가 사실상 사라진다. OpenAI, Anthropic, Google의 가격 인하 경쟁이 이 방향으로 진행 중이다.
2. Auto Research의 신뢰성이 90% 이상으로 올라가는 경우. 현재 42% 실험 실패율이 10% 이하로 떨어지면, 프로덕션 환경에서도 Auto Research 도입을 검토할 수 있게 된다. EvoScientist의 자기진화 메모리가 이 방향의 기술적 기반이 될 수 있다.
3. AutoML 도구들이 LLM을 내장하는 경우. Frontiers in AI(2025)에서 이미 LLM-driven AutoML의 인간 중심 평가를 다룬 논문이 발표되었고, AutoM3L(Automated Multimodal ML)처럼 LLM이 AutoML을 오케스트레이션하는 하이브리드 접근이 연구되고 있다. 이 방향이 주류가 되면, Auto Research와 AutoML의 경계 자체가 흐려질 수 있다.