ALiBi (Attention with Linear Biases)
Context Window Management
쉽게 이해하기
도서관에서 책을 찾는 상황을 떠올려 보자. 기존 위치 인코딩 방식은 각 책에 고정된 번호표를 붙이는 것과 같다. 1번 책, 2번 책, 3번 책... 이렇게 번호를 미리 정해두면, 도서관이 확장되어 1,000번 이후의 책이 들어왔을 때 기존 번호 체계로는 그 책들의 위치를 제대로 파악할 수 없다. ALiBi(Attention with Linear Biases)는 이 문제를 완전히 다른 방식으로 접근한다. 번호표를 붙이는 대신, "지금 내가 보고 있는 책에서 얼마나 멀리 있는가"에 따라 관심도를 자동으로 조절하는 것이다.
기존의 sinusoidal이나 learned position embedding 방식은 토큰 임베딩에 위치 정보를 직접 더한다. 즉, 모델이 "3번 위치"라는 패턴을 학습하므로, 학습 시 본 적 없는 위치 번호(예: 2049번)가 나타나면 성능이 급격히 붕괴한다. 반면 ALiBi는 위치 임베딩을 아예 사용하지 않는다. 대신 어텐션 점수를 계산한 후, 두 토큰 사이의 거리에 비례하는 선형 페널티를 부과한다. 가까운 토큰은 거의 페널티 없이 높은 어텐션을 받고, 먼 토큰은 거리만큼 페널티를 받아 어텐션이 약해진다. 이 페널티는 학습하는 것이 아니라 고정된 값이므로, 학습 시 보지 못한 더 긴 시퀀스에서도 자연스럽게 작동한다.
ALiBi를 채택한 대표적인 모델로는 BigScience의 BLOOM(176B 파라미터), MosaicML의 MPT 시리즈, 일부 Falcon 모델, 그리고 MosaicBERT가 있다. Meta의 음성 모델인 VoiceBox와 AudioBox에서도 ALiBi가 활용되고 있어, 텍스트뿐 아니라 오디오 도메인까지 적용 범위가 넓다.
정량적으로 보면, ALiBi를 적용한 1.3B 파라미터 모델은 1,024 토큰으로 학습한 후 2,048 토큰 시퀀스에서 테스트했을 때, 2,048 토큰으로 직접 학습한 sinusoidal 모델과 동일한 perplexity를 달성했다. 동시에 학습 속도는 11% 빠르고, 메모리는 11%(1.6GB) 적게 사용했다1. 즉, 절반 길이의 데이터로 학습해도 동일한 성능을 얻을 수 있어 학습 비용을 크게 절감할 수 있다.

기술 심층 분석
선수학습: 이 내용을 이해하려면 Context Window Management를 먼저 읽으면 좋습니다. 형제 방법론인 RoPE와 Sliding Window Attention도 함께 참고하세요.
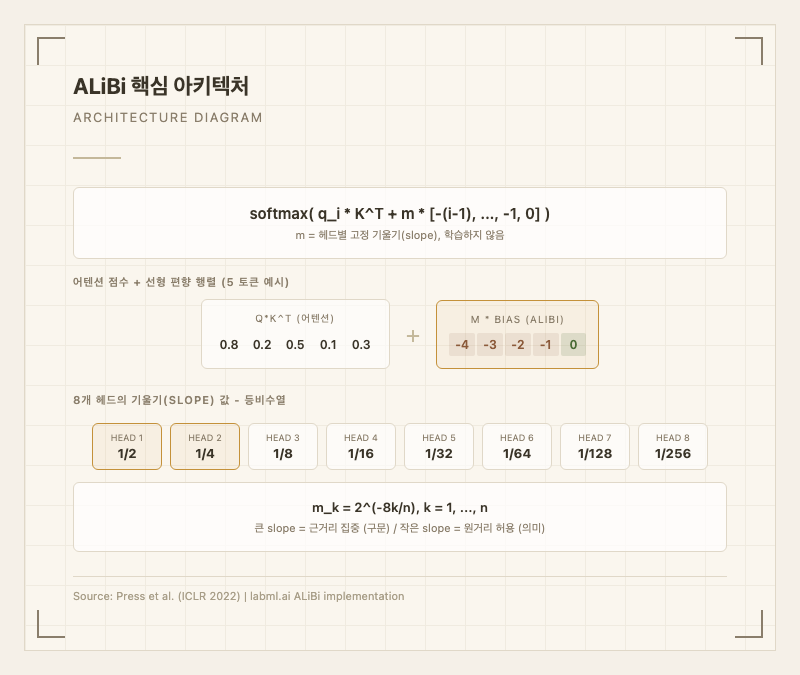
핵심 아키텍처
ALiBi의 핵심 수식은 다음과 같다. 기존 어텐션 메커니즘에서 softmax 계산 전 단계에 선형 편향(linear bias)을 추가한다:
여기서 는 위치 의 query 벡터, 는 key 행렬, 은 헤드별 고정 기울기(slope)다. 편향 벡터 은 현재 위치에서 각 이전 토큰까지의 거리를 음수로 표현한 것이다. 현재 토큰(거리 0)은 페널티 없이 원래 어텐션 점수를 유지하고, 멀리 있는 토큰일수록 큰 음수 페널티를 받는다2.
헤드별 기울기(slope) 설정
개의 어텐션 헤드가 있을 때, 각 헤드 의 기울기는 등비수열로 결정된다:
8개 헤드 기준으로 구체적인 값은 다음과 같다:
| 헤드 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| slope () | 1/2 | 1/4 | 1/8 | 1/16 | 1/32 | 1/64 | 1/128 | 1/256 |
큰 slope(1/2)를 가진 헤드는 먼 토큰에 강한 페널티를 부과해 근거리 토큰에 집중하며, 주로 구문(syntax) 패턴을 포착한다. 작은 slope(1/256)를 가진 헤드는 약한 페널티로 먼 토큰까지 어텐션을 허용하여 전체 문맥의 의미(semantics)를 파악한다. 이 기울기 값은 학습하지 않으며, 모든 도메인과 모델 크기에서 동일한 공식으로 설정한다(논문 Table 3)2.
기존 방식과의 구조적 차이
기존 방식 (Sinusoidal / Learned):
input = token_embedding + position_embedding
attention = softmax(QK^T / sqrt(d))
ALiBi:
input = token_embedding (위치 임베딩 없음)
attention = softmax(QK^T / sqrt(d) + m * distance_bias)
위치 정보가 임베딩 공간이 아닌 어텐션 점수 공간에서 작용하므로, 학습 시 보지 못한 위치에 대해서도 거리 기반 페널티가 자연스럽게 적용된다.
성능 및 비교
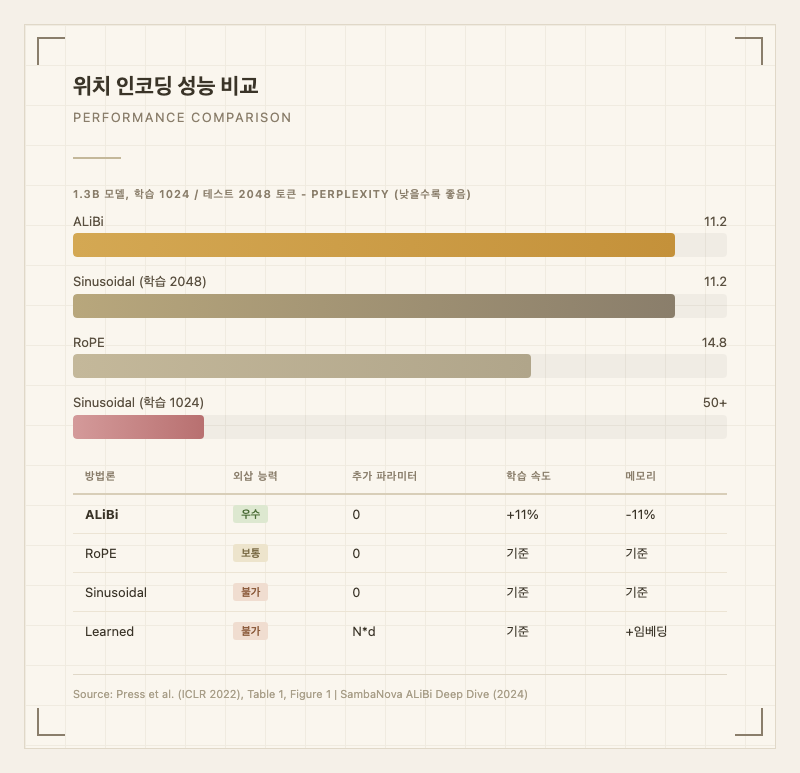
| 방법론 | 학습 길이 | 테스트 길이 | Perplexity | 외삽 가능 여부 | 출처 |
|---|---|---|---|---|---|
| ALiBi | 1024 | 2048 | 11.2 | 가능 (2-10x) | 논문 Table 1 |
| Sinusoidal | 2048 | 2048 | 11.2 | 불가 | 논문 Table 1 |
| Sinusoidal | 1024 | 2048 | 50+ | 불가 (급격 붕괴) | 논문 Figure 1 |
| RoPE | 1024 | 2048 | ~14.8 | 제한적 | 논문 Figure 1 |
| T5 Bias | 1024 | 2048 | ~13.5 | 제한적 | 논문 Figure 1 |
ALiBi는 1,024 토큰으로 학습한 모델이 2,048 토큰까지 외삽했을 때 perplexity가 거의 증가하지 않으며, 심지어 16,000 토큰까지도 안정적인 성능을 유지한다. 반면 sinusoidal과 RoPE는 학습 길이를 넘어서면 perplexity가 급격히 상승한다(논문 Figure 1)1.
학습 효율 측면에서, ALiBi 모델은 동일 성능 달성 시 sinusoidal 대비 학습 속도 11% 향상, 메모리 사용량 11%(1.6GB) 절감을 보인다. 이는 위치 임베딩 테이블이 불필요하고, 더 짧은 시퀀스로 학습할 수 있기 때문이다(논문 Section 5)1.
실무적으로 이 수치가 의미하는 것은, 1K 토큰으로 학습한 ALiBi 모델을 2K-10K 토큰 추론에 바로 배포할 수 있어 학습 비용을 대폭 줄일 수 있다는 점이다.
BLOOM-7B 모델의 SCROLLS 벤치마크에서, ALiBi 보간(interpolation) 방식은 외삽(extrapolation) 대비 NarrativeQA에서 F1 4.17 vs 1.63, GovReport에서 ROUGE1 18.39 vs 14.21로 크게 앞섰다(SambaNova, 2024)3.
장점과 한계
장점
- 길이 외삽 능력: 학습 길이의 2-10배까지 추론 가능. 1K 토큰 학습으로 10K+ 토큰 추론 시에도 perplexity가 완만하게 상승(논문 Figure 1)1
- 제로 추가 파라미터: 위치 임베딩 테이블이 없어 모델 파라미터가 증가하지 않음. 기울기 은 고정값으로 학습 대상이 아님2
- 학습 효율: 짧은 시퀀스로 학습 가능하므로 동일 성능 대비 학습 속도 11% 향상, 메모리 11% 절감(논문 Section 5)1
- 구현 단순성: 어텐션 계산에 편향 행렬 한 줄 추가만으로 구현 가능. 기존 트랜스포머 아키텍처 수정 최소화
- 도메인 범용성: 텍스트(BLOOM, MPT), 오디오(VoiceBox), 인코더 모델(MosaicBERT) 등 다양한 도메인에서 검증됨
한계
- FP16/BF16 정밀도 문제: 8K+ 시퀀스에서 FP16은 마지막 20개 위치가 5개 고유값으로 축소되고, BF16은 모두 동일 값으로 붕괴. 해결 방향: ALiBi 편향 계산을 FP32로 수행(SambaNova, 2024)3
- 일부 NLU 태스크에서 성능 저하: GLUE의 CoLA, MRPC, RTE에서 ALiBi가 오히려 해로운 결과. 해결 방향: 인코더 모델에서는 양방향 ALiBi 변형 사용 검토(ICLR Blogposts, 2024)4
- 최소 학습 길이 제약: 학습 시퀀스 길이 256 미만에서는 성능 급격 저하. 256 이상의 시퀀스 길이 필수(OpenReview, 2024)5
- RoPE 대비 생태계 열세: 2023-24년 이후 LLaMA, Mistral 등 주류 모델이 RoPE를 채택하고, RoPE 스케일링(NTK-aware, YaRN) 기법이 발전하면서 ALiBi의 외삽 우위가 약화됨. 대안: 새 모델 학습 시에만 ALiBi 고려, 기존 RoPE 모델 확장 시에는 RoPE 스케일링 사용
- 산술 등 정밀 위치 의존 태스크 실패: 산술 태스크에서 3-4 위치 이상이면 정확도가 0에 근접. 해결 방향: 위치 정밀도가 요구되는 태스크에서는 다른 위치 인코딩 사용(OpenReview, 2024)5
실무 적용 가이드
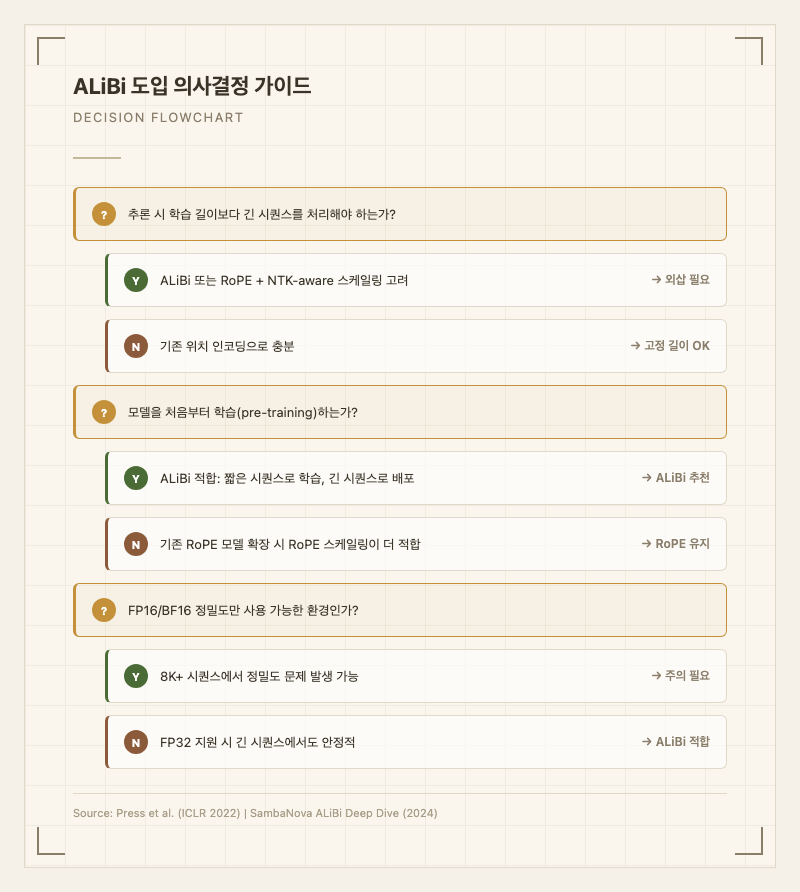
적합한 시나리오
- 모델을 처음부터 사전학습(pre-training)할 때
- 학습 시 짧은 시퀀스를 사용하고 추론 시 긴 시퀀스를 처리해야 할 때
- 위치 임베딩 파라미터를 줄여 모델을 경량화하고 싶을 때
- FP32 연산이 가능한 환경에서 긴 컨텍스트를 처리할 때
부적합한 시나리오
- 이미 RoPE 기반으로 학습된 모델의 컨텍스트를 확장할 때 (RoPE 스케일링이 더 적합)
- FP16/BF16만 지원하는 하드웨어에서 8K+ 시퀀스를 처리할 때
- 산술이나 코드 생성 등 정밀한 위치 정보가 필수인 태스크
- 학습 데이터의 시퀀스 길이가 256 미만인 경우
도입 판단 기준
- 추론 시퀀스 길이가 학습 길이의 2배 이상이면 ALiBi 또는 RoPE+스케일링 검토
- 새 모델 사전학습 시 ALiBi가 구현 단순성과 학습 효율에서 유리
- 기존 모델 확장 시에는 해당 모델의 위치 인코딩 방식을 유지하는 것이 안전
ALiBi를 사용하는 주요 모델: BLOOM (BigScience), MPT (MosaicML), Falcon (일부), MosaicBERT, VoiceBox (Meta)

Footnotes
-
Press, O., Smith, N., Lewis, M. "Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation." ICLR 2022. ↩ ↩2 ↩3 ↩4 ↩5
-
labml.ai ALiBi implementation (nn.labml.ai/transformers/alibi) ↩ ↩2 ↩3
-
SambaNova Systems. "ALiBi Deep Dive: Interpolation vs. Extrapolation." 2024. ↩ ↩2
-
ICLR Blogposts 2024. "Masked Language Model with ALiBi and CLAP head." ↩
-
OpenReview. "From Interpolation to Extrapolation." Under review at ICLR 2024. ↩ ↩2