Contrastive Learning
Pretraining
쉽게 이해하기
대조 학습(Contrastive Learning)은 AI가 "무엇이 비슷하고 무엇이 다른지"를 스스로 배우는 학습 기법이다. 일상적인 비유로 설명하면, 와인 소믈리에가 수백 종의 와인을 비교 시음하면서 "이 두 잔은 같은 포도 품종이다", "이 둘은 전혀 다른 산지다"를 반복하며 감각을 훈련하는 과정과 같다. 소믈리에에게 정답표가 주어지지 않아도, 충분한 비교 경험을 쌓으면 처음 맛보는 와인의 특성도 정확히 파악할 수 있게 된다. 대조 학습은 이와 동일한 원리로, 데이터 쌍의 유사/비유사를 비교하는 것만으로 강력한 표현(representation)을 학습한다.
기존의 지도학습(Supervised Learning)은 모든 데이터에 사람이 붙인 레이블이 필요하다. 이미지 100만 장에 "고양이", "자동차", "산" 같은 정답을 일일이 붙이는 것은 비용이 크고 확장이 어렵다. 대조 학습은 이 문제를 우회한다. 같은 이미지를 두 가지 방식으로 변형(자르기, 색상 변경 등)하여 "이 둘은 같은 것"이라는 양성 쌍(positive pair)을 자동 생성하고, 다른 이미지와는 "다른 것"이라는 부정 쌍(negative pair)으로 대비시킨다. 레이블 없이도 데이터 자체에서 학습 신호를 만들어내는 자기지도학습(Self-supervised Learning)의 핵심 기법이다.
대조 학습의 실제 영향력은 이미 널리 입증되었다. OpenAI의 CLIP은 4억 개의 이미지-텍스트 쌍을 대조 학습으로 훈련하여, 별도 파인튜닝 없이 ImageNet 분류에서 76.2% 정확도를 달성했다(논문 Table 1)[^1]. 구글 브레인의 SimCLR은 비전 분야에서 지도학습에 근접한 성능을 보여주었고, Princeton의 SimCSE는 문장 임베딩 품질을 BERT 대비 21.5%p 향상시켰다(STS 벤치마크 기준, EMNLP 2021)[^2]. 이 기법은 RAG 시스템의 검색 품질, 이미지 검색, 추천 시스템 등 실무 전반에 걸쳐 핵심 역할을 하고 있다.
이 비유의 한계: 와인 소믈리에는 맛의 차원이 제한적이지만, 대조 학습은 수백~수천 차원의 임베딩 공간에서 작동한다. 또한 소믈리에는 순차적으로 비교하지만, 대조 학습은 배치 내 수천 개 샘플을 동시에 비교한다.
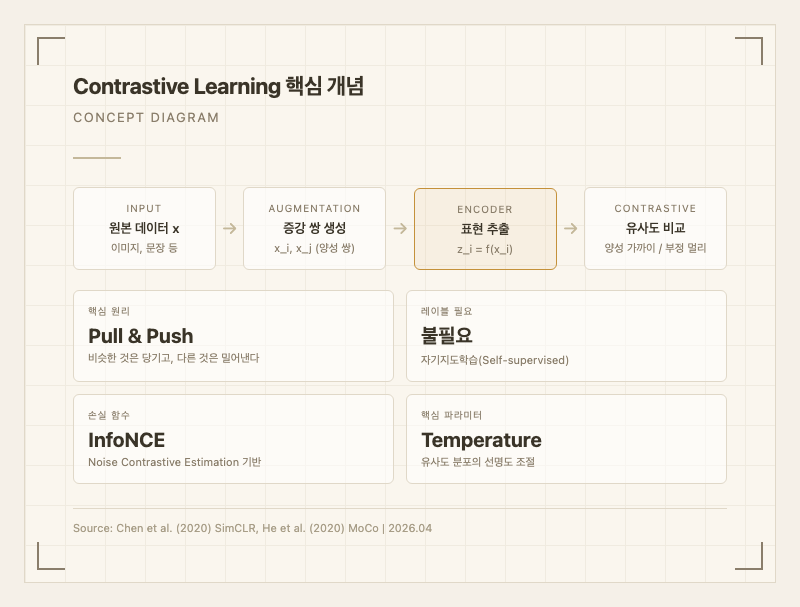
기술 심층 분석
선수학습: 이 내용을 이해하려면 Pretraining을 먼저 읽으면 좋습니다.
핵심 아키텍처
대조 학습의 핵심은 임베딩 공간에서 양성 쌍은 가깝게, 부정 쌍은 멀게 배치하는 것이다. 이를 수학적으로 구현한 것이 InfoNCE(Noise Contrastive Estimation) 손실 함수다.
InfoNCE 손실 함수
배치 내 개 샘플에서 앵커 와 양성 쌍 에 대해:
eq i]} \exp(\text{sim}(z_i, z_k) / \tau)}$$ 여기서: - $z_i = g(f_\theta(x_i))$: 인코더 $f_\theta$ + 프로젝션 헤드 $g$의 출력 - $\text{sim}(a, b) = \frac{a \cdot b}{\|a\| \|b\|}$: 코사인 유사도 - $\tau$: 온도(temperature) 파라미터 - 분자: 양성 쌍의 유사도 (높일수록 좋다) - 분모: 배치 내 모든 쌍의 유사도 합 (부정 쌍을 낮출수록 좋다) 이 손실 함수의 기원은 van den Oord et al. (2018)의 CPC(Contrastive Predictive Coding) 논문이며, 정보 이론의 상호정보량(Mutual Information) 하한과 연결된다[^3]. **온도 파라미터 $\tau$의 역할** $\tau$는 유사도 분포의 선명도를 조절한다: - $\tau \to 0$: 분포가 날카로워짐 (가장 유사한 것에 집중, hard margin) - $\tau \to \infty$: 분포가 균일해짐 (모든 쌍을 비슷하게 취급, soft margin) 실무에서 CLIP은 $\tau = 0.07$, SimCLR은 $\tau = 0.1$을 사용한다(각 논문 기준). 너무 작으면 학습이 불안정하고, 너무 크면 양성/부정 쌍의 구분력이 떨어진다. **주요 프레임워크 비교** ``` SimCLR 파이프라인: x -> [Aug_1] -> x_i -> [Encoder f] -> h_i -> [Proj g] -> z_i x -> [Aug_2] -> x_j -> [Encoder f] -> h_j -> [Proj g] -> z_j InfoNCE(z_i, z_j) MoCo 파이프라인: x_q -> [Encoder f_q] -> q (쿼리) x_k -> [Momentum Enc f_k] -> k (키, 큐에 저장) theta_k <- m * theta_k + (1-m) * theta_q ``` **SimCLR** (Chen et al., 2020, Google Brain): 동일 이미지에서 두 가지 증강(Random Crop + Color Jitter + Gaussian Blur)을 적용해 양성 쌍을 생성한다. 배치 크기 $N$에서 $2(N-1)$개의 부정 쌍이 생성되므로, 대형 배치(4096~8192)가 필수적이다. 핵심 발견은 프로젝션 헤드 $g$가 표현 품질을 크게 향상시킨다는 것이다(ICML 2020)[^4]. **MoCo** (He et al., 2020, FAIR): 모멘텀 인코더와 큐(queue)를 활용하여 대형 배치 없이도 충분한 부정 샘플을 확보한다. 키 인코더의 파라미터를 쿼리 인코더의 지수이동평균(EMA)으로 업데이트한다: $$\theta_k \leftarrow m\theta_k + (1-m)\theta_q, \quad m = 0.999$$ 이 방식으로 배치 크기 256만으로도 65,536개의 부정 샘플을 큐에 유지할 수 있다(CVPR 2020)[^5]. **CLIP** (Radford et al., 2021, OpenAI): 이미지 인코더와 텍스트 인코더를 동시에 훈련하여, $N$개의 이미지-텍스트 쌍에서 $N \times N$ 유사도 행렬의 대각선 요소를 최대화한다: $$\mathcal{L}_{\text{CLIP}} = \frac{1}{2}\left[\mathcal{L}_{\text{image} \to \text{text}} + \mathcal{L}_{\text{text} \to \text{image}}\right]$$ 400M 이미지-텍스트 쌍으로 학습하여 Zero-shot ImageNet Top-1 76.2% 달성. 캡션 예측 방식 대비 4배의 데이터 효율을 보였다(ICML 2021)[^1]. **SimCSE** (Gao et al., 2021, Princeton): NLP용 대조 학습으로, 동일 문장을 인코더에 두 번 통과시켜 드롭아웃 마스크만 다른 양성 쌍을 생성한다. 이 최소한의 증강만으로 STS 벤치마크에서 BERT-base 기준 76.3% Spearman 상관계수를 달성했다. 지도학습 버전은 NLI 데이터셋의 함의(entailment) 쌍을 양성, 모순(contradiction) 쌍을 하드 네거티브로 활용하여 81.6%를 달성했다(EMNLP 2021)[^2].  ### 성능 및 비교 | 프레임워크 | 도메인 | 벤치마크 | 성능 | 비교 대상 | 출처 | |-----------|--------|---------|------|----------|------| | SimCLR v2 | 비전 | ImageNet Top-1 (Linear) | 71.7% | Supervised 76.5% | SimCLR v2 논문 Table 1 | | MoCo v2 | 비전 | ImageNet Top-1 (Linear) | 71.1% | SimCLR 69.3% (동일 배치) | MoCo v2 논문 Table 1 | | BYOL | 비전 | ImageNet Top-1 (Linear) | 74.3% | SimCLR 69.3% | BYOL 논문 Table 1 | | CLIP | 비전+언어 | ImageNet Top-1 (Zero-shot) | 76.2% | Supervised ResNet-50 76.5% | CLIP 논문 Table 1 | | SimCSE (Unsup) | NLP | STS-B Spearman | 76.3% | BERT CLS 54.8% | SimCSE 논문 Table 2 | | SimCSE (Sup) | NLP | STS-B Spearman | 81.6% | SBERT 77.0% | SimCSE 논문 Table 2 | 실무적 해석: 대조 학습은 비전에서 지도학습 대비 약 94~97% 수준의 성능을 레이블 없이 달성한다. NLP 문장 임베딩에서는 기존 방법 대비 압도적 개선을 보여, RAG 검색 품질 향상에 직접 기여한다. 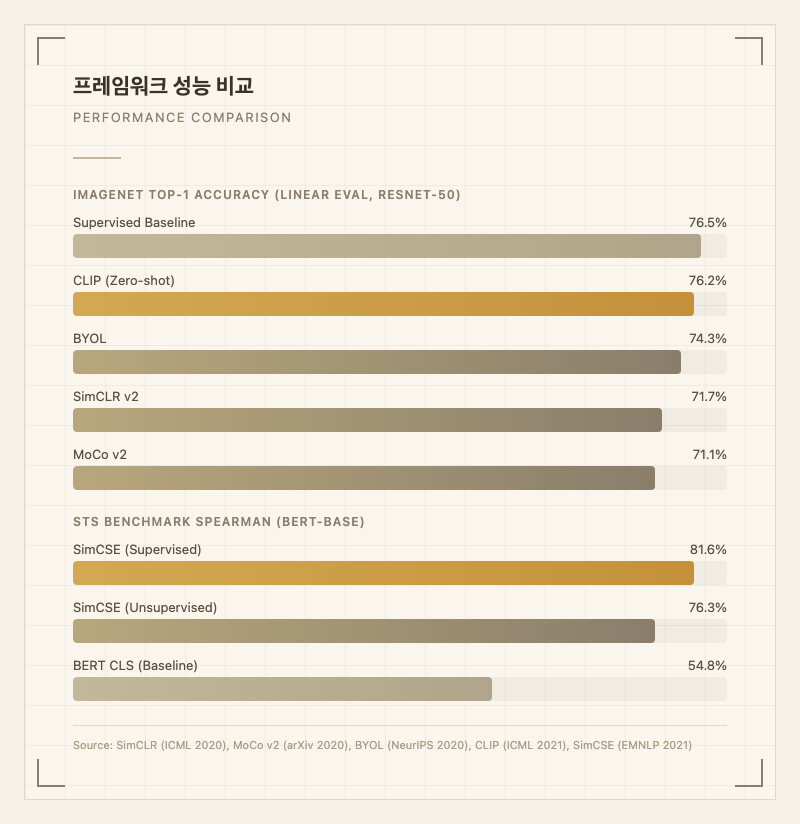 ### 장점과 한계 **장점** 1. **레이블 불필요**: 수억 개의 비정형 데이터를 레이블 없이 활용 가능. 레이블링 비용이 높은 의료, 위성, 산업 도메인에서 특히 유효하다. 2. **전이 학습 성능**: 사전학습된 대조 학습 모델은 소량 데이터 파인튜닝에서 지도학습 사전학습보다 우수한 경우가 많다. SimCLR v2는 1% 레이블로도 73.9% 정확도를 달성했다(논문 Table 3). 3. **멀티모달 정렬**: CLIP으로 대표되는 이미지-텍스트 정렬은 Zero-shot 분류, 이미지 검색, 생성 모델 가이드(Stable Diffusion의 텍스트 조건) 등 다양한 응용을 가능케 한다. 4. **표현 품질**: 대조 학습으로 얻은 임베딩은 uniformity(균일성)와 alignment(정렬성)이 우수하여, 다운스트림 태스크에서 범용적으로 사용 가능하다. **한계** 1. **대형 배치 의존성**: SimCLR은 4096~8192 배치 크기가 필요하며, 이는 TPU/대형 GPU 클러스터를 요구한다. 해결 방향: MoCo의 큐 기반 접근, GatherLayer로 분산 학습. 2. **증강 전략 민감성**: 성능이 데이터 증강 조합에 크게 좌우된다. 비전에서는 Random Crop + Color Jitter가 핵심이지만, 도메인(의료, NLP 등)마다 적합한 증강이 다르다. 해결 방향: 도메인별 증강 탐색(AutoAugment), SimCSE처럼 드롭아웃 활용. 3. **거짓 부정(False Negative) 문제**: 배치 내 부정 샘플 중 실제로는 의미적으로 유사한 샘플이 포함될 수 있다(예: 같은 품종의 다른 강아지). 이는 학습 신호를 오염시킨다. 해결 방향: Debiased Contrastive Learning, Hard Negative Mining 기법. 4. **표현 붕괴(Collapse) 위험**: 모델이 모든 입력에 동일한 표현을 출력하는 trivial solution에 빠질 수 있다. BYOL/SimSiam은 stop-gradient로 이를 방지하지만, 이론적 이해가 완전하지 않다. 5. **고수준 의미 포착 한계**: 대조 학습은 저/중수준 시각 특징을 잘 포착하지만, 추상적 의미(물체 개수 세기, 관계 추론 등)에서는 지도학습보다 약하다. CLIP도 counting이나 spatial reasoning에서 어려움을 보인다(CLIP 논문 Section 7). ### 실무 적용 가이드 **적합한 시나리오** - 레이블 없는 대량 데이터가 있고 범용 표현이 필요한 경우 - 멀티모달(이미지-텍스트, 오디오-텍스트) 정렬이 필요한 경우 - 문장/문서 임베딩 품질 향상이 필요한 RAG 시스템 - 소량 레이블 데이터로 파인튜닝할 사전학습 모델이 필요한 경우 **부적합한 시나리오** - 충분한 레이블 데이터가 이미 확보된 경우 (지도학습이 더 직접적) - GPU 자원이 매우 제한적인 경우 (배치 크기 256 미만) - 고수준 추론(counting, spatial reasoning)이 핵심인 태스크 **도입 판단 기준** - 데이터: 비정형 데이터 10만 건 이상이면 효과적, 100만 건 이상이면 강력히 권장 - 배치 크기: SimCLR 계열은 최소 2048, MoCo 계열은 256부터 가능 - GPU 메모리: SimCLR은 32GB+ GPU 4~8장, MoCo는 단일 GPU에서도 실행 가능 - NLP 적용: SimCSE는 BERT-base 단일 GPU에서 2시간 내 학습 완료 **프레임워크 선택 가이드** | 조건 | 추천 프레임워크 | |------|--------------| | 대형 GPU 클러스터 보유 | SimCLR v2 | | 단일/소수 GPU | MoCo v3 | | 이미지-텍스트 정렬 | CLIP / SigLIP | | 문장 임베딩 | SimCSE | | 부정 샘플 설계가 어려운 경우 | BYOL / DINO | 형제 방법론: [Autoregressive Pretraining](/methodologies/autoregressive-pretraining), [Denoising Pretraining](/methodologies/denoising-pretraining), [Masked Language Modeling](/methodologies/masked-language-modeling-mlm)   [^1]: Radford, A. et al. (2021). *Learning Transferable Visual Models From Natural Language Supervision (CLIP)*. ICML 2021. 400M 이미지-텍스트 쌍으로 학습, Zero-shot ImageNet 76.2%. [^2]: Gao, T. et al. (2021). *SimCSE: Simple Contrastive Learning of Sentence Embeddings*. EMNLP 2021. 드롭아웃 기반 증강으로 STS 최고 성능 달성. [^3]: van den Oord, A. et al. (2018). *Representation Learning with Contrastive Predictive Coding*. arXiv:1807.03748. InfoNCE 손실 함수 최초 제안. [^4]: Chen, T. et al. (2020). *A Simple Framework for Contrastive Learning of Visual Representations (SimCLR)*. ICML 2020. 증강 + 대형 배치 + MLP 프로젝션 헤드 조합이 핵심. [^5]: He, K. et al. (2020). *Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)*. CVPR 2020. 큐 기반 부정 샘플 관리로 배치 크기 제약 해소.