Qwen3.5 397B A17B
QwenLLM자연어 처리컴퓨터 비전오디오 처리262K 토큰
2026년 2월 16일Apache 2.0
Qwen3.5 397B A17B는 Alibaba Qwen 팀이 2026년 2월에 공개한 오픈 웨이트 플래그십 모델로, 총 397B 파라미터 중 토큰당 17B만 활성화하는 대규모 MoE(Mixture-of-Experts) 아키텍처를 통해 1조 파라미터급 Qwen3-Max에 필적하는 성능을 훨씬 적은 연산으로 달성한다.
주요 특징
Qwen3.5 397B의 가장 눈에 띄는 차별점은 하이브리드 어텐션 아키텍처다. 기존 Transformer의 표준 어텐션 대신, 전체 60개 레이어의 75%에 Gated DeltaNet(선형 어텐션)을 적용하고 나머지 25%에만 표준 Gated Attention을 사용한다. 이 구조 덕분에 Qwen3-Max 대비 32K 컨텍스트에서 디코딩 처리량이 8.6배, 256K에서는 19배 빨라졌다 (출처: 공식 블로그).
512개 전문가 중 토큰당 10개 라우팅 + 1개 공유 전문가만 활성화하는 MoE 구조로, 파라미터 효율성이 극단적으로 높다. Elon Musk가 X에서 "Impressive intelligence density"라고 반응한 것도 이 때문이다. 실제로 커뮤니티에서도 "이 정도 성능을 17B 활성 파라미터로 낸다는 게 놀랍다"는 반응이 지배적이었다.
네이티브 멀티모달도 핵심이다. 별도의 비전 인코더 없이 텍스트, 이미지, 비디오, GUI를 단일 모델에서 처리한다. MMMU 85.0, MMBench 93.7, AI2D 93.9 등 비전 벤치마크에서도 프리미엄 모델에 필적하는 수치를 기록했다 (출처: HuggingFace 모델 카드).
언어 지원도 119개(Qwen3)에서 201개로 대폭 확대되었다. 컨텍스트 윈도우는 기본 262K, YaRN 확장 시 최대 1,010,000 토큰까지 지원한다.

할 수 있는 것
코딩 에이전트로서의 능력이 가장 두드러진다. SWE-bench Verified 76.4%로, 실제 GitHub 이슈의 약 3/4을 자동 수정할 수 있는 수준이다 (출처: HuggingFace 모델 카드). TerminalBench 2.0에서 52.5%를 기록해 Qwen3-Max-Thinking(22.5%) 대비 27 포인트 이상 향상되었다 (출처: artificialanalysis.ai).
웹 브라우징과 도구 사용 능력도 강하다. BrowseComp에서 78.6으로 경쟁 모델들을 앞섰고, TAU2-Bench(도구 사용 벤치마크)에서 86.7을 기록했다 (출처: HuggingFace 모델 카드). OSWorld-Verified 62.2, AndroidWorld 66.8로 데스크톱 및 모바일 환경 자동화에도 실용적인 성능을 보여준다.
수학 올림피아드 문제에서도 강력하다. AIME 2026 91.3, HMMT Feb 2025 94.8을 기록했고, IMOAnswerBench 80.9로 국제수학올림피아드 수준의 문제도 상당 부분 해결한다 (출처: HuggingFace 모델 카드).
다만 Reddit 사용자 후기에 따르면, 코딩 작업에서 "Gemini 수준은 되지만 Claude Opus와는 격차가 있다"는 평가도 있었다. 벤치마크 수치와 실사용 체감 사이에 간극이 존재한다는 의견이다. 특히 복잡한 에이전트 워크플로우에서 Claude Opus 4.6이 더 안정적이라는 평가가 많았다.
비전 분석 능력도 실용적이다. OmniDocBench 90.8로 문서 이해, OCRBench 93.1로 텍스트 인식, MathVision 88.6으로 수학적 시각 추론에서 모두 높은 점수를 기록했다 (출처: HuggingFace 모델 카드).
성능
벤치마크 종합
| 벤치마크 | Qwen3.5 397B | 비고 |
|---|---|---|
| GPQA Diamond | 88.4 | 대학원 수준 과학 추론 (출처: HuggingFace) |
| MMLU-Pro | 87.8 | 전문 영역 지식 (출처: HuggingFace) |
| IFEval | 92.6 | 지시 따르기 (출처: HuggingFace) |
| LiveCodeBench v6 | 83.6 | 실시간 코딩 (출처: HuggingFace) |
| SWE-bench Verified | 76.4 | 실무 버그 수정 (출처: HuggingFace) |
| TAU2-Bench | 86.7 | 도구 사용 (출처: HuggingFace) |
| OSWorld-Verified | 62.2 | 데스크톱 에이전트 (출처: HuggingFace) |
| AIME 2026 | 91.3 | 수학 올림피아드 (출처: HuggingFace) |
| HLE | 28.7 | 최고난도 시험 (출처: HuggingFace) |
| TerminalBench 2.0 | 52.5 | 터미널 자동화 (출처: HuggingFace) |
| MMMU | 85.0 | 멀티모달 이해 (출처: HuggingFace) |
| MMBench | 93.7 | 비전-언어 (출처: HuggingFace) |
| MMStar | 83.8 | 비전 추론 (출처: HuggingFace) |
| AI2D | 93.9 | 다이어그램 이해 (출처: HuggingFace) |
경쟁 모델 비교
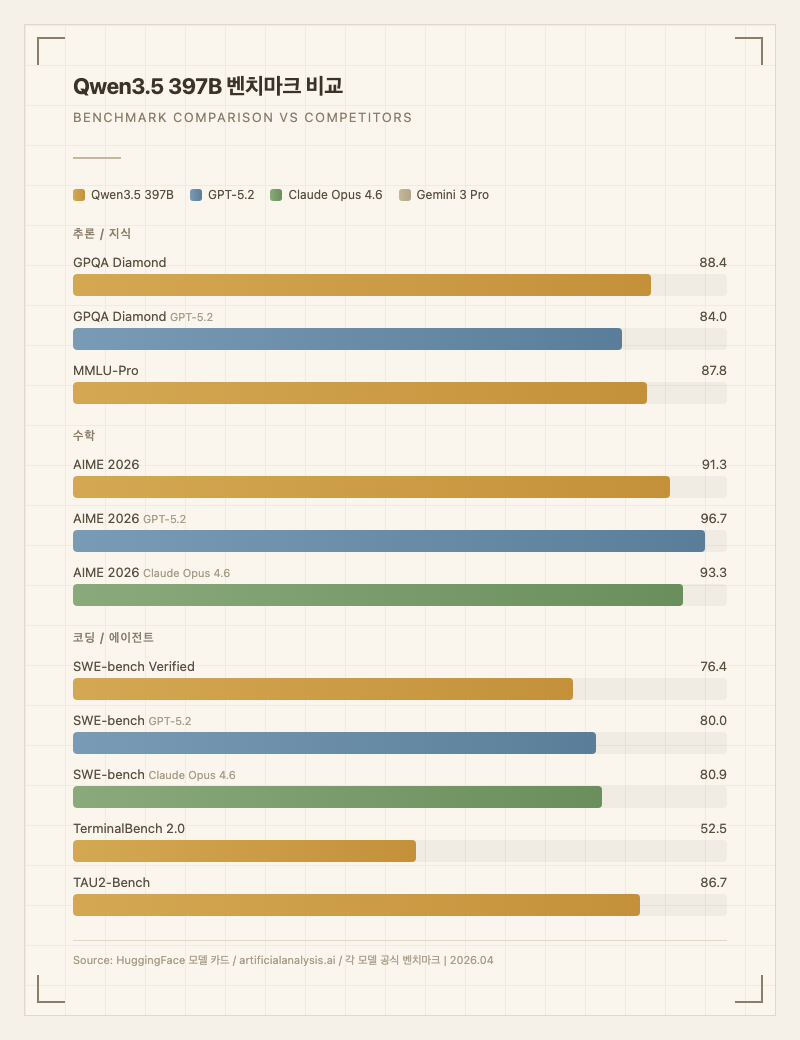
GPQA Diamond 88.4는 오픈소스 모델 중 최상위권이며, GPT-5.2(84.0 수준)를 능가한다. 하지만 SWE-bench Verified에서는 76.4로 GPT-5.2(80.0)와 Claude Opus 4.6(80.9)에 뒤진다 (출처: 각 모델 공식 벤치마크). 수학에서도 AIME 2026 91.3은 강력하지만 GPT-5.2(96.7)와 Claude Opus 4.6(93.3)보다는 낮다.
Artificial Analysis Intelligence Index에서 45점으로, 오픈 웨이트 모델 중 3위(GLM-5 Reasoning 50, Kimi K2.5 Reasoning 47에 이어)를 기록했다 (출처: artificialanalysis.ai).
실사용에서 "벤치마크는 좋은데 실제 코딩 작업에서는 Claude에 미치지 못한다"는 의견이 Reddit과 Hacker News에서 반복적으로 나타났다. 반면 "이 가격에 이 성능이면 가성비는 압도적"이라는 평가도 동시에 존재했다. 환각(hallucination) 문제도 지적되었는데, AA-Omniscience Index -32로 Qwen3 235B(-48)보다는 개선되었지만 여전히 최상위 오픈 웨이트 모델 대비 높은 환각률을 보인다 (출처: artificialanalysis.ai).
사용 방법
일반 사용자
Alibaba Cloud의 Tongyi Qianwen(통의천문) 웹/앱에서 Qwen3.5를 직접 사용할 수 있다. 별도 설치 없이 브라우저에서 접속하면 된다. 또한 OpenRouter, Together AI, NVIDIA NIM 등 다양한 서드파티 플랫폼에서도 제공된다.
개발자 (API)
DashScope(Alibaba Cloud Model Studio)를 통해 API로 접근할 수 있다. OpenAI 호환 API 형식을 지원하므로 기존 OpenAI SDK를 거의 그대로 사용할 수 있다.
python
from openai import OpenAI
client = OpenAI(
base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
api_key="YOUR_DASHSCOPE_API_KEY"
)
response = client.chat.completions.create(
model="qwen3.5-397b-a17b",
messages=[{"role": "user", "content": "Hello"}]
)
오픈 웨이트 모델이므로 HuggingFace에서 가중치를 다운로드해 자체 호스팅도 가능하다. vLLM, SGLang 등의 추론 프레임워크를 통해 로컬 배포할 수 있으며, FP8 양자화 버전도 공식 제공된다. 커뮤니티에서는 2-bit, 3-bit 양자화를 통해 소비자급 GPU에서 구동하는 실험도 활발하게 진행 중이다.
공식 문서: https://www.alibabacloud.com/help/en/model-studio/models
가격
API 가격은 프로바이더에 따라 다르다.
| 프로바이더 | Input / 1M 토큰 | Output / 1M 토큰 |
|---|---|---|
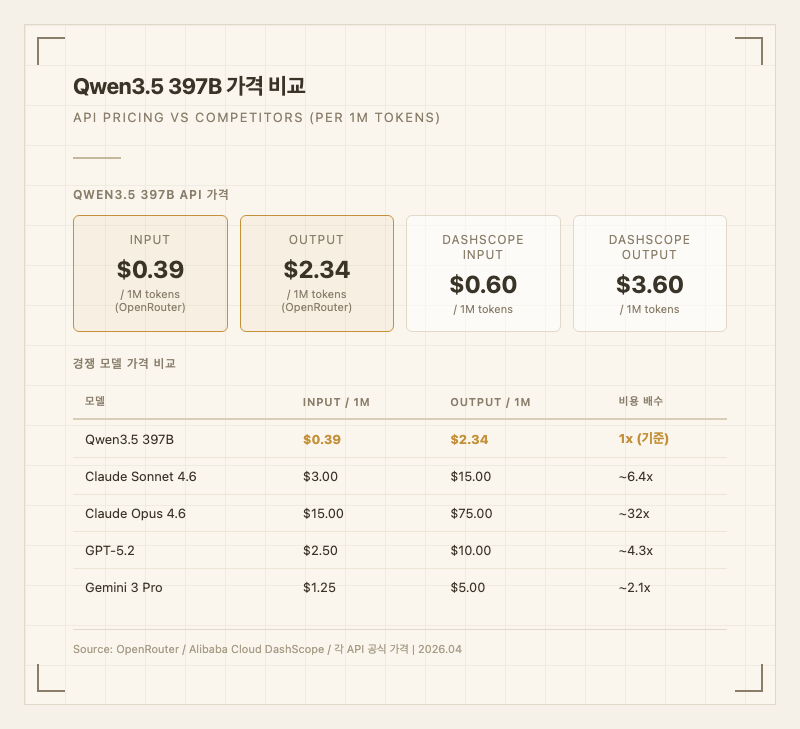
| OpenRouter | $0.39 | $2.34 |
| DashScope (Alibaba) | $0.60 | $3.60 |
| Together AI | 별도 확인 필요 | 별도 확인 필요 |
경쟁 모델과 비교하면 가격 경쟁력이 압도적이다. Claude Sonnet 4.6(Input 15.00) 대비 약 6배 저렴하고, Claude Opus 4.6(Input 75.00) 대비 약 32배 저렴하다. GPT-5.2(Input 10.00) 대비로도 약 4배 저렴하다.
커뮤니티에서 "비용 대비 성능으로는 이길 모델이 없다"는 평가가 지배적이다. 다만 Qwen3.5-Flash가 $0.10/1M input으로 훨씬 저렴한 옵션도 제공하므로, 간단한 작업에는 Flash가 더 적합하다는 의견도 있었다.
오픈 웨이트이므로 자체 호스팅 시 API 비용 자체가 발생하지 않는다. 다만 397B 모델을 서빙하려면 상당한 GPU 자원이 필요하다. FP8 양자화 기준으로도 최소 수십 GB의 VRAM이 요구된다.
한국어 토큰 효율에 대한 공식 데이터는 미공개 상태다. 다만 Qwen 계열 토크나이저가 중국어/한국어/일본어에 최적화되어 있어, 같은 텍스트 기준으로 영어 중심 모델(GPT, Claude 등) 대비 한국어 토큰 수가 적을 수 있다. Qwen3 시리즈에서 비영어 언어의 추론 토큰이 영어 대비 28% 절감된다는 보고가 있었다 (출처: MindStudio).
기술 사양
| 항목 | 사양 |
|---|---|
| 총 파라미터 | 397B |
| 활성 파라미터 | 17B (토큰당) |
| 아키텍처 | Hybrid MoE (Gated DeltaNet + Gated Attention) |
| 레이어 | 60 (15 x [3 GDN-MoE + 1 GA-MoE]) |
| 전문가 구성 | 512 전문가, 10 라우팅 + 1 공유 활성화 |
| Hidden Dimension | 4,096 |
| 컨텍스트 윈도우 | 262,144 (YaRN: 1,010,000) |
| 최대 출력 | 65,536 토큰 |
| 어휘 크기 | 248,320 |
| 지원 언어 | 201개 |
| 멀티모달 | 텍스트, 이미지, 비디오, GUI |
| 라이선스 | Apache 2.0 |
| 출시일 | 2026년 2월 16일 |
Gated DeltaNet은 선형 복잡도(O(n))의 어텐션 메커니즘으로, 표준 어텐션(O(n^2))의 긴 시퀀스 처리 병목을 해소한다. 전체 레이어의 75%를 GDN으로 채우고, 정밀한 주의 집중이 필요한 25%에만 표준 어텐션을 남겨둔 것이 Qwen3.5의 핵심 설계 결정이다.
한국어 사용자 후기에 따르면, 397B 모델의 한국어 이해력은 전반적으로 우수하나, 122B-A10B 모델에서 비추론 모드로 번역 요청 시 영어 단어가 간헐적으로 섞이는 현상이 보고되었다 (출처: arca.live). 397B 모델에서는 이러한 문제가 덜하다는 평가다.

참고 자료




스펙
컨텍스트 윈도우
262K 토큰
라이선스
Apache 2.0
출시일
2026년 2월 16일
가성비 지수
3.3
API 가격 (혼합)
입력 $0.390/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.39 / 1M 토큰
출력 (Completion)
$2.34 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
92.6
복잡한 지시사항 이해 및 수행
멀티모달
89.1
이미지, 비디오 등 멀티모달 이해
일반지식
87.8
다양한 분야 지식 및 이해
코딩
70.8
코드 생성, 버그 수정, 소프트웨어 엔지니어링
Provider
Qwen
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Qwen3.5 397B A17B | 88.1 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |