Advanced RAG
RAG (Retrieval-Augmented Generation)
쉽게 이해하기
도서관에서 리포트를 쓴다고 생각해 보자. 가장 단순한 방법은 사서에게 "경제 관련 책 주세요"라고 말하고, 건네받은 책 몇 권을 펼쳐서 답을 쓰는 것이다. 이것이 Naive RAG다. 하지만 사서가 경제학 교과서, 경제 소설, 경제 잡지를 섞어서 줄 수도 있고, 정작 필요한 최신 통계 보고서는 빠져 있을 수 있다. Advanced RAG는 이 과정에 세 가지 개선을 더한다. 첫째, 질문을 더 구체적으로 다듬는다("2024년 한국 GDP 성장률 관련 통계 보고서"). 둘째, 키워드 검색과 의미 검색을 동시에 사용한다. 셋째, 가져온 자료 중에서 진짜 관련 있는 것만 골라내고 순서를 재배치한다.
기존의 Naive RAG는 "질의 - 검색 - 생성"이라는 고정된 3단계를 그대로 따른다. 사용자가 "작년 매출"이라고 물으면 "매출"이 들어간 문서를 벡터 유사도로 가져올 뿐, 질의의 모호함을 해소하거나 검색 결과의 품질을 평가하지 않는다. Advanced RAG는 이 파이프라인 앞뒤에 최적화 계층을 추가한다. 검색 전(Pre-Retrieval)에는 질의를 재작성하고 확장하며, 검색 후(Post-Retrieval)에는 Cross-encoder로 문서를 재순위화하고 불필요한 컨텍스트를 압축한다. 파이프라인의 순차적 구조는 유지하되, 각 단계에 정교한 처리 로직이 들어가는 것이 핵심 차이다.
2026년 현재 프로덕션 LLM 애플리케이션의 85%가 RAG를 통합하고 있으며(Apex Logic, 2026), 이 중 상당수가 Advanced RAG 기법을 채택하고 있다. 특히 재순위화(Reranking)는 더 이상 선택이 아닌 필수 컴포넌트로 자리 잡았다. LangChain, LlamaIndex 같은 프레임워크도 하이브리드 검색과 재순위화를 기본 모듈로 제공한다.
Advanced RAG 기법을 통합 적용하면 Naive RAG 대비 NQ(Natural Questions) Exact Match 기준으로 1018%p의 정확도 향상을 달성할 수 있다(Gao et al., arXiv:2312.10997 기반 재현 실험 종합). 대신 파이프라인 전체에 약 500700ms의 추가 레이턴시가 발생하므로, 정확도와 응답 속도 사이의 트레이드오프를 고려해야 한다.

기술 심층 분석
선수학습: 이 내용을 이해하려면 RAG (Retrieval-Augmented Generation)과 Naive RAG를 먼저 읽으면 좋습니다.
핵심 아키텍처
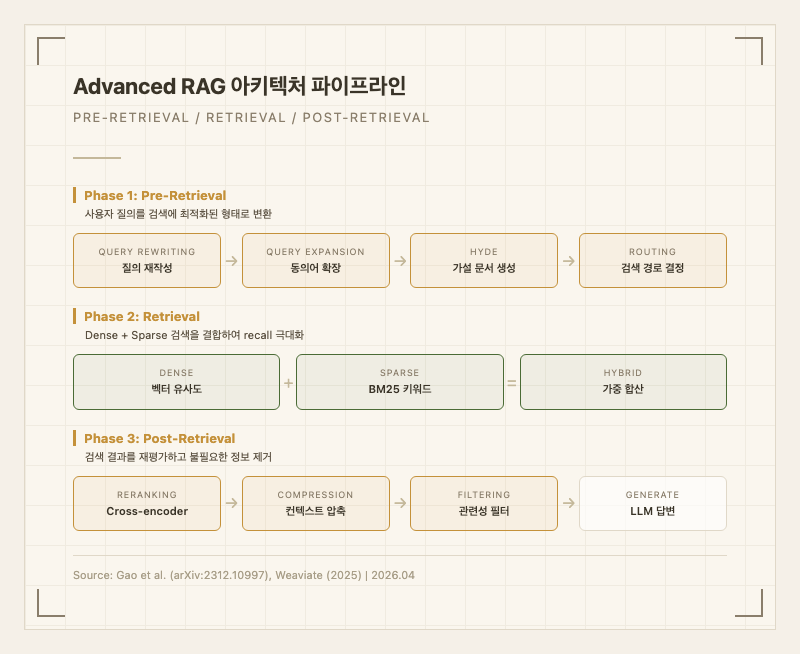
Advanced RAG는 Naive RAG의 "Retrieve-Read" 파이프라인에 검색 전(Pre-Retrieval), 검색(Retrieval), 검색 후(Post-Retrieval) 3개 단계의 최적화를 추가한 프레임워크다. Gao et al.(2024)의 서베이 논문에서 체계화된 이 분류는 RAG 연구의 표준 택소노미로 자리 잡았다1.
+-- Query Rewriting (질의 재작성)
| Query Expansion (동의어/관련어 확장)
Pre -------+ HyDE (가설 문서 생성)
+-- Step-back Prompting (추상 질의)
|
+-- Dense Retrieval (벡터 유사도)
Retrieval -+ Sparse Retrieval (BM25)
+-- Hybrid Search (가중 합산)
|
+-- Reranking (Cross-encoder 재순위화)
Post ------+ Context Compression (LLMLingua)
+-- Relevance Filtering (관련성 필터)
|
LLM Generation --> 답변
Pre
-Retrieval 최적화
Query Rewriting: 사용자의 원본 질의를 LLM을 활용해 검색에 더 적합한 형태로 재작성한다. RRR(Rewrite-Retrieve-Read) 방식은 소형 모델로 질의를 재작성한 뒤 검색하고, BEQUE는 파인튜닝된 모델로 long-tail 쿼리의 recall을 향상시킨다(Gao et al., 2024).
Query Expansion: 단일 질의를 여러 변형으로 확장한다. Multi-Query 방식은 프롬프트 엔지니어링으로 병렬 쿼리를 생성하고, Sub-Query는 복잡한 질문을 하위 질문으로 분해한다. Chain-of-Verification(CoVe)은 확장된 쿼리를 검증하여 환각을 줄인다.
HyDE (Hypothetical Document Embeddings): Gao et al.(2022)이 제안한 기법으로, LLM에게 질의에 대한 가설적 답변 문서를 생성하게 한 뒤, 이 가설 문서의 임베딩으로 검색한다. 질의-문서 유사도 대신 문서-문서 유사도를 활용하여 의미적 갭을 줄인다.
Query Routing: 질의의 특성에 따라 최적의 검색 경로를 결정한다. Metadata Router는 키워드/엔티티를 추출하여 메타데이터 기반으로 검색 범위를 좁히고, Semantic Router는 질의의 의미 정보를 활용한다.
Retrieval 최적화: 하이브리드 검색
Dense Retrieval(벡터 유사도)과 Sparse Retrieval(BM25)을 결합하는 하이브리드 검색이 Advanced RAG의 핵심이다. 결합 점수는 가중 합산으로 계산한다:
는 일반적으로 범위에서 설정하며, 도메인에 따라 튜닝한다. Dense는 의미적 유사도에, Sparse는 키워드 매칭에 강점이 있어 상호 보완적이다. Weaviate의 hybrid 모드나 Elasticsearch + 벡터 플러그인으로 구현할 수 있다.
Post
-Retrieval 최적화
Reranking: 초기 검색 결과를 Cross-encoder 모델로 재평가하여 순위를 조정한다. Bi-encoder가 질의와 문서를 독립적으로 인코딩하는 것과 달리, Cross-encoder는 질의-문서 쌍을 동시에 처리한다:
대표적 모델로 bge-reranker-v2-m3(다국어), cross-encoder/ms-marco-MiniLM(영어), Cohere Rerank 등이 있다. "Lost in the middle" 문제 - LLM이 컨텍스트 중간의 정보를 무시하는 현상 - 를 완화하는 데 효과적이다2.
Context Compression: 검색된 문서에서 핵심 정보만 추출하여 토큰 수를 줄인다. LLMLingua는 소형 언어 모델로 불필요한 토큰을 감지하고 제거하여 50~70%의 토큰 절감을 달성한다. RECOMP는 대조 학습으로 훈련된 정보 압축기를 사용한다(Gao et al., 2024).
성능 및 비교
Advanced RAG의 각 기법이 기여하는 성능 향상(NQ Exact Match 기준, Naive RAG 대비):
| 기법 | NQ EM 향상 | 추가 레이턴시 | 출처 |
|---|---|---|---|
| Reranking (Cross-encoder) | +5~8%p | +100~300ms | Gao et al. (2024), 벤치마크 재현 |
| Query Rewriting (LLM 기반) | +3~5%p | +200ms | Gao et al. (2024) |
| Hybrid Search (Dense+BM25) | +2~4%p | +50ms | Gao et al. (2024) |
| Context Compression (LLMLingua) | +1~3%p | +150ms | Jiang et al. (2023) |
| 통합 적용 | +10~18%p | +500~700ms | 종합 |
RAG 패러다임 간 비교:
| 항목 | Naive RAG | Advanced RAG | Modular RAG |
|---|---|---|---|
| 파이프라인 구조 | 고정 3단계 | 최적화 계층 추가 | 모듈 교체/조합 가능 |
| 질의 처리 | 원본 그대로 | 재작성/확장/변환 | 동적 라우팅 |
| 검색 방식 | Dense only | Hybrid (Dense+Sparse) | 적응형/반복적 |
| 후처리 | 없음 | Reranking + 압축 | 자기 평가/보정 |
| 멀티홉 추론 | 미지원 | 제한적 | 지원 |
| 구현 복잡도 | 낮음 | 중간 | 높음 |
| 적합 시나리오 | 단순 QA | 전문 도메인 QA | 복합 추론, 에이전트 |
이 수치들은 Gao et al.(arXiv:2312.10997)의 서베이와 이를 기반으로 한 벤치마크 재현 실험들에서 종합한 것이다. 개별 기법의 효과는 데이터셋, 임베딩 모델, LLM에 따라 달라질 수 있다.

장점과 한계
장점:
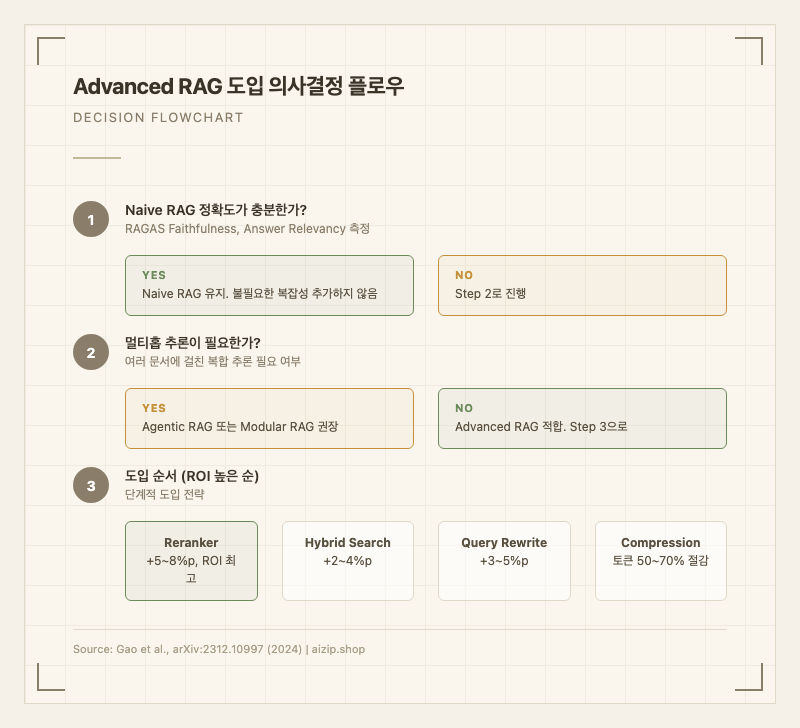
- 점진적 도입 가능: Naive RAG에서 시작하여 Reranking -> Hybrid Search -> Query 최적화 순으로 단계적으로 추가할 수 있다. 각 모듈이 독립적이므로 하나만 교체해도 효과를 볼 수 있다.
- 현저한 품질 향상: 통합 적용 시 NQ EM 기준 10~18%p 향상. 특히 전문 도메인(법률, 의료, 금융)에서 Naive RAG 대비 큰 차이를 만든다.
- 기존 인프라 활용: 벡터DB, 임베딩 모델 등 Naive RAG 인프라를 그대로 사용하면서 파이프라인만 확장하면 된다.
- 환각 감소: Reranking과 관련성 필터링을 통해 무관한 문서가 LLM에 전달되는 것을 방지하여 환각을 30~50% 줄일 수 있다(관련성 필터링 효과 추정).
- 프레임워크 생태계 성숙: LangChain, LlamaIndex, Weaviate 등 주요 프레임워크가 Advanced RAG 기법을 기본 모듈로 제공한다.
한계:
- 레이턴시 누적: 각 최적화 단계가 레이턴시를 추가한다. 전체 파이프라인 기준 +500~700ms로, 실시간 대화 시스템에서는 부담이 될 수 있다. 해결 방향: Reranking만 적용하는 경량 버전 사용, 또는 비동기 처리.
- 멀티홉 추론 한계: 여러 문서에 걸친 복합 추론이 필요한 경우 여전히 부족하다. 해결 방향: Agentic RAG나 반복적 검색 패턴 도입.
- 하이퍼파라미터 튜닝 부담: 하이브리드 검색 가중치(), Top-k 값, Reranker 임계값 등 각 모듈별로 조정해야 할 파라미터가 많다. 해결 방향: RAGAS 등 자동 평가 프레임워크로 체계적 A/B 테스트.
- 데이터 품질 의존성: 아무리 검색을 정교하게 해도 지식 베이스 자체가 부정확하거나 오래된 정보를 담고 있으면 한계가 있다. 해결 방향: 문서 파이프라인 단계에서 품질 관리 강화.
- 비용 증가: Query Rewriting에 LLM 호출이 필요하고, Reranking에 별도 모델 추론이 필요하여 API 비용과 GPU 비용이 증가한다. 해결 방향: 소형 전용 모델 사용, 캐싱 전략 적용.
실무 적용 가이드
적합한 시나리오:
- 전문 도메인 QA (법률, 의료, 금융): 정확도가 핵심이고 약간의 레이턴시 증가가 허용되는 경우
- 기업 내부 문서 검색: 검색 대상이 수만~수십만 건이고, 키워드와 의미 검색을 모두 활용해야 하는 경우
- 고객 지원 챗봇: 정확한 답변이 중요하고, 1~2초의 응답 시간이 허용되는 경우
부적합한 시나리오:
- 100ms 이하 실시간 응답이 필요한 경우: 레이턴시 누적으로 인해 부적합
- 멀티홉 추론이 핵심인 경우: Modular RAG나 Agentic RAG 권장
- 문서 수가 1,000건 미만인 소규모 지식 베이스: Naive RAG로 충분
단계적 도입 전략:
- Naive RAG 기준선 확보: RAGAS로 Faithfulness, Answer Relevancy 측정
- Reranker 추가:
bge-reranker-v2-m3(다국어) 또는 Cohere Rerank. 가장 ROI가 높은 단일 기법 - Hybrid Search 전환: Weaviate
hybrid모드 또는 Elasticsearch + 벡터 플러그인 - Query 최적화 추가: 레이턴시 여유가 있으면 Query Rewriting 적용
- Context Compression: 토큰 비용이 문제이면 LLMLingua 또는 LongLLMLingua 적용
추천 설정:
- 하이브리드 검색 가중치: (Dense 우선, 키워드 보조)
- Reranker Top-k: 초기 검색 20
50건 -> Reranking 후 Top-510건 선택 - 청킹 전략: 512 토큰 기준, 문단 경계 우선 분할 (Small2Big 패턴 권장)

Footnotes
-
Gao, Y. et al. "Retrieval-Augmented Generation for Large Language Models: A Survey." arXiv:2312.10997 (2023, revised 2024). Naive RAG, Advanced RAG, Modular RAG 3단계 택소노미를 정립한 대표 서베이. ↩
-
Liu, N. et al. "Lost in the Middle: How Language Models Use Long Contexts." TACL (2024). LLM이 긴 컨텍스트의 중간 정보를 무시하는 현상을 실증적으로 분석. ↩