Agentic RAG
RAG (Retrieval-Augmented Generation)
쉽게 이해하기
숙련된 탐정이 사건을 수사하는 과정을 떠올려 보자. 탐정은 첫 단서를 발견하면 거기서 새로운 질문을 만들고, 다른 장소를 수색하고, 필요하면 감식 전문가에게 의뢰하기도 한다. 한 번의 수색으로 끝내지 않고, "이 증거가 충분한가?" 스스로 판단하면서 수사를 반복한다. Agentic RAG는 AI가 바로 이 탐정처럼 행동하는 검색-생성 방법론이다. 질문 하나에 검색 한 번으로 끝내는 것이 아니라, 여러 도구를 오가며 자율적으로 정보를 모으고 검증한다.
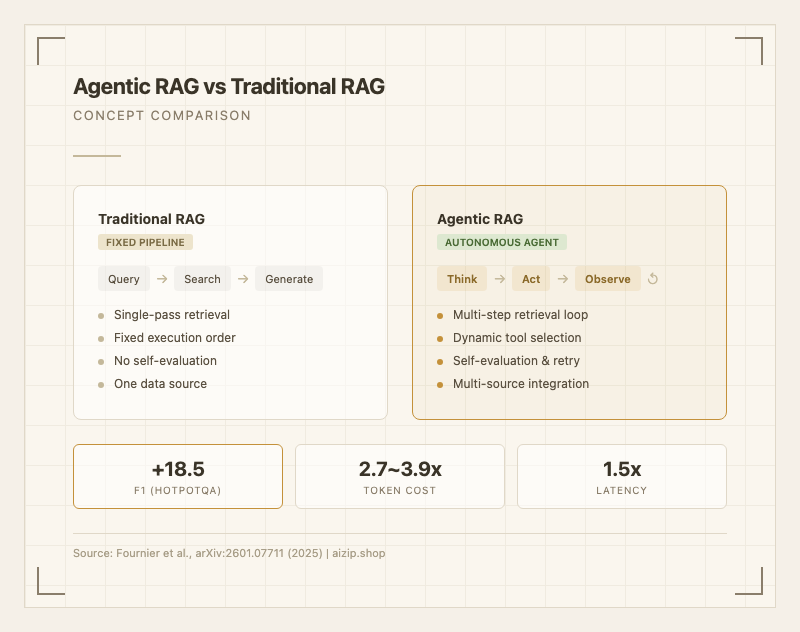
기존 Naive RAG는 "질문 -> 검색 -> 답변"이라는 단일 패스 파이프라인을 따른다. 검색 결과가 부족하든, 질문이 여러 단계를 요구하든 관계없이 한 번 검색한 결과로 답변을 생성한다. Advanced RAG는 쿼리 재작성이나 재순위화 같은 최적화 모듈을 추가했지만, 여전히 미리 정해진 순서대로 실행되는 고정 파이프라인이다. Agentic RAG는 이 한계를 근본적으로 바꾼다. LLM 에이전트가 "어떤 도구를 쓸지", "검색을 더 할지", "결과가 충분한지"를 매 단계마다 스스로 결정한다.
@Perplexity가 대표적인 사례다. 복잡한 질문을 입력하면 여러 웹사이트를 순차적으로 검색하고, 정보를 교차 검증한 뒤 출처까지 정리해서 답변한다. 투자 리서치에서 "삼성전자 투자 전망"을 물으면 재무제표, 뉴스, 경쟁사 현황을 각각 별도 검색으로 수집한 뒤 종합 분석을 내놓는다. Morgan Stanley, PwC, ServiceNow 같은 기업들도 내부 문서 검색에 에이전트 기반 RAG 아키텍처를 도입해 운영 중이다1.
정량적으로 보면, Agentic RAG는 복합 추론(multi-hop) 질의에서 Naive RAG 대비 F1 점수 +18.5 포인트 향상을 보인다(HotpotQA 기준). 다만 토큰 사용량이 2.7-3.9배 증가하고 응답 시간이 1.5배 길어지는 트레이드오프가 있어, 단순 질의에는 오히려 비효율적이다(arXiv:2601.07711).
기술 심층 분석
선수학습: 이 내용을 이해하려면 RAG (Retrieval-Augmented Generation)와 Modular RAG를 먼저 읽으면 좋습니다.
핵심 아키텍처
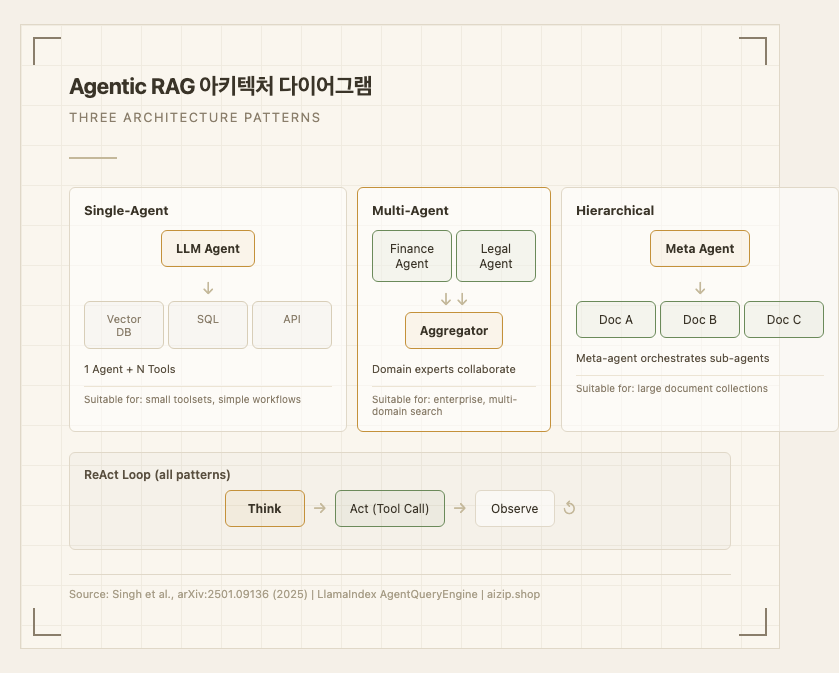
Agentic RAG는 LLM 에이전트가 자율적으로 검색 전략을 계획하고 실행하는 RAG 패러다임이다. Singh et al.(2025)의 서베이 논문2에 따르면, Agentic RAG는 네 가지 에이전트 설계 패턴을 활용한다: 반성(Reflection), 계획(Planning), 도구 사용(Tool Use), 멀티 에이전트 협업(Multi-Agent Collaboration).
핵심 실행 구조는 ReAct(Reasoning + Acting) 프레임워크3를 따른다:
각 단계에서 에이전트는 (1) 현재 상태 에서 다음 행동을 추론하고, (2) 도구를 호출하며, (3) 결과를 관찰한 뒤, (4) 추가 행동이 필요한지 판단한다. 충분한 정보가 모이면 최종 답변을 생성한다.
User Query: "2024년 노벨 물리학상 수상자의 소속 대학 설립 연도는?"
Step 1: [Think] 먼저 수상자를 검색해야 한다
[Act] search("2024 노벨 물리학상 수상자")
[Obs] "Geoffrey Hinton, University of Toronto"
Step 2: [Think] University of Toronto 설립 연도를 찾아야 한다
[Act] search("University of Toronto founded")
[Obs] "1827년 설립"
Step 3: [Think] 충분한 정보를 얻었다
[Answer] "1827년입니다."
아키텍처 유형은 세 가지로 분류된다(Singh et al., 2025):
- Single-Agent: 하나의 에이전트가 N개 도구를 관리. 소규모 도구셋에 적합.
- Multi-Agent: 도메인별 전문 에이전트가 분업. 금융 에이전트, 법률 에이전트 등이 각자 검색 후 결과를 통합.
- Hierarchical: 메타 에이전트가 하위 문서 에이전트들을 조율. LlamaIndex의 AgentQueryEngine이 이 패턴을 구현한다4.
성능 및 비교
Fournier et al.(2025)의 실험 연구 "Is Agentic RAG worth it?"5는 Naive RAG, Enhanced RAG, Agentic RAG를 4개 데이터셋에서 체계적으로 비교했다.
| 방법론 | FIQA F1 (arXiv:2601.07711) | CQADupStack F1 (arXiv:2601.07711) | NDCG@10 평균 (arXiv:2601.07711) |
|---|---|---|---|
| Naive RAG | 66.7 | 66.7 | 50.3 |
| Enhanced RAG | 95.7 | 96.6 | 52.8 |
| Agentic RAG | 98.8 | 99.8 | 55.6 |
단, FEVER(사실 검증) 데이터셋에서는 Enhanced RAG가 F1 87.9로 Agentic RAG(64.6)를 크게 앞섰다. 넓고 노이즈가 많은 도메인에서는 Enhanced RAG의 체계적 모듈이 더 효과적이다(arXiv:2601.07711).
비용 측면: Agentic RAG는 Enhanced RAG 대비 입력 토큰 2.7-3.9배, 출력 토큰 1.7-2.0배, 응답 시간 1.5배가 소요된다(arXiv:2601.07711). 이 비용 증가가 정당화되려면 복합 추론이 필요한 태스크여야 한다.
실무적 의미: 잘 최적화된 Enhanced RAG가 대부분의 단일 질의 시나리오에서 Agentic RAG와 비슷하거나 더 나은 성능을 보이면서 비용은 훨씬 낮다. Agentic RAG는 multi-hop 추론, 다중 소스 통합, 도구 활용이 필수인 시나리오에서만 우위를 점한다.

장점과 한계
장점:
- 적응적 검색: 질의 복잡도에 따라 검색 깊이와 범위를 자동 조절한다. Multi-hop 질의에서 F1 +18.5 포인트 향상(HotpotQA 기준, arXiv:2601.07711).
- 도구 확장성: 벡터 검색 외에 SQL, API, 계산기, 코드 실행 등 다양한 도구를 통합할 수 있다. 새 도구 추가 시 에이전트 재학습 없이 도구 설명만 등록하면 된다.
- 설명 가능성: ReAct의 Think 단계가 추론 과정을 명시적으로 기록한다. 에이전트가 어떤 판단으로 어떤 도구를 호출했는지 추적 가능하다.
- 멀티 소스 통합: 단일 질의에 대해 여러 데이터 소스(문서, DB, 웹)를 자동으로 교차 참조한다.
한계:
- 비용 폭증: 에이전트 루프당 LLM 호출이 3-5회 발생하여 토큰 비용이 2.7-3.9배 증가한다(arXiv:2601.07711). 해결 방향: Query Router로 단순 질의를 직접 RAG로 분기.
- 무한 루프 위험: 종료 조건 미달 시 에이전트가 도구를 무한 반복 호출한다. 해결 방향: max_iterations 설정(보통 5-7회), 토큰 예산 상한 설정.
- 도구 선택 오류: 잘못된 도구 호출이 전체 추론 체인을 오염시킨다. 해결 방향: 도구 설명(description)을 정밀하게 작성하고, fallback 전략 마련.
- 보안 취약점: 외부 검색 결과에 포함된 악의적 지시문이 에이전트 행동을 조작할 수 있다(Indirect Prompt Injection). 특히 다단계 워크플로우에서 초기 오류가 연쇄적으로 확대되는 Cascading Failure 위험이 있다6.
- 프로덕션 실패율: 기업 RAG 구현의 72-80%가 첫 해에 기대 성능에 미달한다는 보고가 있다. Agentic RAG의 추가 복잡성은 이 리스크를 높인다7.
실무 적용 가이드
적합한 시나리오:
- Multi-hop 질의가 빈번한 리서치/분석 도구 (투자 리서치, 법률 검토, 경쟁 분석)
- 여러 데이터 소스(DB, 문서, 웹)를 동시에 활용해야 하는 엔터프라이즈 검색
- 계산, 코드 실행 등 비검색 도구가 필요한 복합 태스크
- 응답 정확도가 속도/비용보다 우선인 시나리오
부적합한 시나리오:
- 단순 Q&A (단일 문서 검색으로 충분한 경우) - Enhanced RAG가 더 효율적
- 실시간 응답이 필요한 챗봇 (1.5배 레이턴시 증가는 UX 저하)
- 예산이 제한된 소규모 서비스 (토큰 비용 3-4배 증가)
- 정형화된 FAQ 봇 (고정 파이프라인으로 충분)
도입 판단 기준:
- 질의의 50% 이상이 2단계 이상의 추론을 필요로 하면 Agentic RAG 도입 고려
- GPU/API 예산이 기존 RAG의 3배 이상 확보 가능해야 함
- 단순 질의 비율이 높으면 Query Router를 두어 하이브리드 운영
추천 프레임워크:
- LangGraph: 상태 관리와 순환 그래프 지원. 복잡한 에이전트 루프 구현에 적합.
- LlamaIndex AgentQueryEngine: 문서별 sub-agent + meta-agent 계층 구조. 대규모 문서 컬렉션에 적합.
- CrewAI: 멀티 에이전트 협업 시나리오에 특화.
추천 설정:
max_iterations: 5-7 (무한 루프 방지)- 도구 설명을 구체적이고 명확하게 작성 (에이전트의 도구 선택 정확도에 직접 영향)
- 토큰 예산 상한 설정 (에이전트 실행당 비용 모니터링)
- 단순 질의 바이패스: Query Router로 복잡도 판별 후 단순 질의는 직접 RAG 처리
@Perplexity가 Agentic RAG를 프로덕션에서 가장 성공적으로 구현한 서비스 중 하나이며, 200억+ URL 인덱스 기반의 멀티 소스 에이전트 검색을 운영 중이다.


Footnotes
-
Toloka AI, "Agentic RAG Systems for Enterprise-Scale Information Retrieval" (2025); DXC Technology, "RAG joins the agentic stack" (2025) ↩
-
Singh, A., Ehtesham, A., Kumar, S., Khoei, T.T., Vasilakos, A.V. "Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG" (2025) arXiv:2501.09136 ↩
-
Yao, S. et al. "ReAct: Synergizing Reasoning and Acting in Language Models" (2023) ICLR 2023 ↩
-
LlamaIndex, "Agentic RAG with LlamaIndex" Architecture Guide (2024) ↩
-
Fournier, C. et al. "Is Agentic RAG worth it? An experimental comparison of RAG approaches" (2025) arXiv:2601.07711 ↩
-
CSO Online, "Why 2025's agentic AI boom is a CISO's worst nightmare" (2025) ↩
-
Meilisearch, "What is agentic RAG? How it works, benefits, challenges & more" (2025) ↩