Chain-of-Thought Prompting (CoT)
Foundation Model API Strategy
쉽게 이해하기
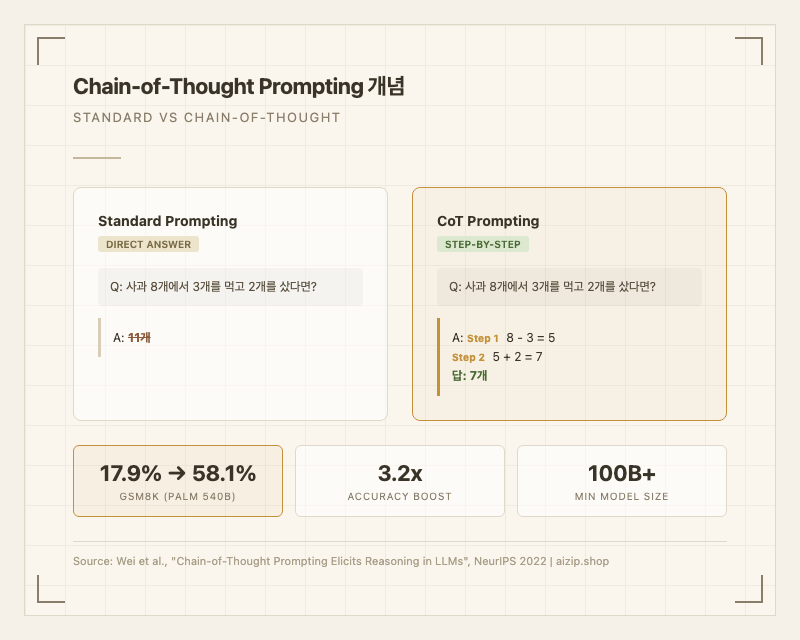
탐정이 사건을 해결하는 과정을 떠올려 보자. 숙련된 탐정은 증거를 보자마자 범인을 지목하지 않는다. 먼저 현장의 단서를 하나씩 살펴보고, 각 단서가 의미하는 바를 추론하며, 논리적으로 연결해서 결론에 도달한다. Chain-of-Thought(CoT) 프롬프팅은 대규모 언어 모델(LLM)에게 이 탐정의 사고 과정을 요구하는 기법이다. "답만 말해"가 아니라 "풀이 과정을 보여줘"라고 요청하는 것이다.
기존 프롬프팅 방식은 질문을 던지면 모델이 곧바로 최종 답을 출력한다. 예를 들어 "사과 8개에서 3개를 먹고 2개를 샀다면 몇 개인가?"라는 질문에 일반 프롬프팅은 "11개"라고 틀린 답을 내놓기 쉽다. 반면 CoT 프롬프팅은 모델이 "8 - 3 = 5, 5 + 2 = 7"이라는 중간 추론 단계를 거치게 해서 정답 "7개"에 도달하도록 유도한다. 핵심은 모델의 가중치나 아키텍처를 건드리지 않고, 프롬프트만 바꿔서 추론 능력을 끌어낸다는 점이다.
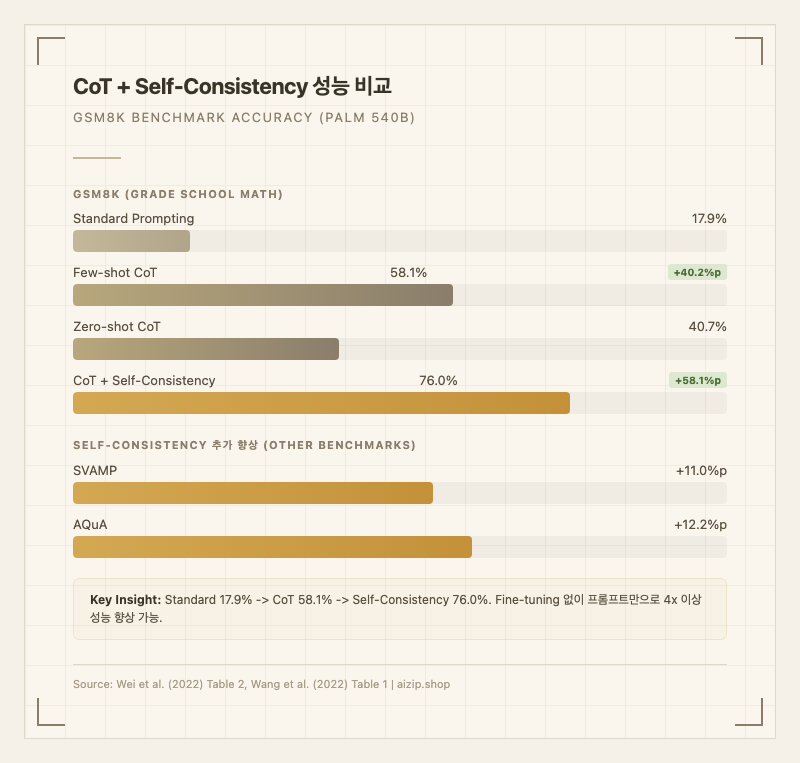
2022년 Google Brain의 Jason Wei 등이 발표한 원 논문1에서 CoT 프롬프팅은 PaLM 540B 모델의 GSM8K(초등 수학) 정확도를 17.9%에서 58.1%로 끌어올렸다. 이후 @ChatGPT, @Claude, @Gemini 등 주요 LLM 서비스들은 내부적으로 CoT를 활용하거나, 아예 학습 단계에서 추론 체인을 내재화하는 방향으로 발전했다. 2025-2026년에는 OpenAI o1, GPT-5의 "thinking mode", Claude의 Extended Thinking 등 CoT가 프롬프트 기법을 넘어 모델 아키텍처의 핵심 구성 요소로 자리잡았다.
이 비유의 한계: 탐정은 새로운 증거가 나타나면 기존 추론을 수정할 수 있지만, 기본 CoT는 한 번 생성한 추론 체인을 역추적하지 못한다. 이 문제를 해결하기 위해 Tree of Thoughts(ToT) 같은 변형이 등장했다.
기술 심층 분석
선수학습: 이 내용을 이해하려면 Foundation Model API Strategy와 Few-shot Prompting을 먼저 읽으면 좋습니다.
핵심 아키텍처
CoT 프롬프팅의 구조는 단순하다. 기존 Few-shot 프롬프팅에서 예시의 답변 부분에 중간 추론 단계(rationale)를 추가하는 것이 전부다.
[Standard Few-shot]
Q: Roger has 5 tennis balls...
A: The answer is 11.
[Few-shot CoT]
Q: Roger has 5 tennis balls...
A: Roger started with 5 balls. 2 cans of 3 = 6. 5 + 6 = 11. The answer is 11.
CoT의 핵심 변형은 세 가지다:
1) Few-shot CoT (Wei et al., 2022)1: 풀이 과정이 포함된 예시 3-8개를 프롬프트에 포함시킨다. 모델은 예시의 추론 패턴을 따라 새로운 문제에도 단계적으로 답변한다. 예시의 품질이 성능을 좌우하며, 도메인별로 신중한 설계가 필요하다.
2) Zero-shot CoT (Kojima et al., 2022)2: 예시 없이 프롬프트 끝에 "Let's think step by step"이라는 한 문장만 추가한다. 2단계 프로세스로 작동한다: (1) 첫 번째 프롬프트로 추론 체인을 생성하고, (2) 두 번째 프롬프트로 체인에서 최종 답을 추출한다. GPT-3(175B)에서 MultiArith 정확도를 17.7%에서 78.7%로, GSM8K를 10.4%에서 40.7%로 향상시켰다 (논문 Table 1)2.
3) Auto-CoT (Zhang et al., 2022)3: 수동 예시 설계를 자동화한다. (1) 데이터셋의 질문들을 클러스터링하고, (2) 각 클러스터에서 대표 질문을 선정한 뒤, (3) Zero-shot CoT로 추론 체인을 자동 생성한다. 다양한 질문 유형을 커버함으로써 단일 유형 편향을 줄인다.
Self-Consistency (Wang et al., 2022)4: CoT의 확장으로, greedy decoding 대신 여러 추론 경로를 샘플링한 뒤 다수결(marginalization)로 최종 답을 선택한다. "복잡한 문제에는 정답에 도달하는 여러 가지 올바른 추론 경로가 존재한다"는 직관에 기반한다.
Tree of Thoughts (Yao et al., 2023)5: CoT의 선형 추론을 트리 구조로 확장한다. 각 추론 단계에서 여러 후보를 생성(branch)하고, 각 후보를 평가(evaluate)하며, 유망하지 않은 경로는 역추적(backtrack)한다. 게임 오브 24 과제에서 기존 CoT가 10% 미만인 반면 ToT는 74% 성공률을 달성했다 (논문 Table 1)5.

성능 및 비교
CoT 프롬프팅의 효과는 모델 크기에 강하게 의존한다. Wei et al.(2022)은 이를 "emergent ability"라 명명했다: 약 100B 파라미터 이상에서만 유의미한 성능 향상이 나타나며, 소형 모델에서는 오히려 비논리적 추론 체인이 생성되어 정확도가 하락한다1.
| 기법 | GSM8K (출처) | SVAMP (출처) | AQuA (출처) |
|---|---|---|---|
| Standard Prompting | 17.9% (Wei 2022 Table 2) | - | - |
| Few-shot CoT | 58.1% (Wei 2022 Table 2) | - | - |
| Zero-shot CoT | 40.7% (Kojima 2022 Table 1) | - | - |
| CoT + Self-Consistency | 76.0% (Wang 2022 Table 1) | +11.0%p (Wang 2022 Table 1) | +12.2%p (Wang 2022 Table 1) |
실무적 의미: GSM8K에서 Standard 17.9% -> CoT 58.1% -> Self-Consistency 76.0%의 향상은, 추론 기법만으로 fine-tuning 없이도 모델의 수학적 추론 능력을 4배 이상 끌어올릴 수 있음을 보여준다.
2026년 최신 연구에 따르면6, 14B 이상의 최신 모델(Qwen2.5, LLaMA3 등)에서는 Zero-shot CoT만으로도 Few-shot CoT에 필적하거나 오히려 이를 능가하는 성능을 보인다. Few-shot 예시의 역할이 "추론 능력 향상"에서 "출력 형식 정렬"로 변화한 것이다.
장점과 한계
장점:
- 추가 학습 불필요: 모델 가중치를 수정하지 않고 프롬프트만 변경하여 추론 성능을 대폭 향상시킨다. GSM8K 기준 3.2배 향상 (17.9% -> 58.1%, PaLM 540B)1.
- 해석 가능성 향상: 중간 추론 단계가 명시적으로 출력되므로, 모델이 왜 그 답에 도달했는지 확인하고 디버깅할 수 있다.
- 범용성: 수학, 상식 추론, 기호 추론 등 다양한 추론 과제에 일관되게 효과적이다.
- Self-Consistency와 결합 시 추가 향상: 다중 샘플링과 다수결로 GSM8K에서 +17.9%p 추가 향상을 달성한다4.
- Zero-shot 변형으로 비용 절감: 예시 설계 없이 "Let's think step by step" 한 문장으로도 상당한 효과를 얻을 수 있다.
한계:
- 모델 크기 의존성: 약 100B 파라미터 미만 모델에서는 비논리적 추론 체인이 생성되어 오히려 정확도가 하락한다1. 해결 방향: 소형 모델 전용 추론 기법(DR-CoT 등) 연구 진행 중.
- CoT가 해로운 과제 존재: 암묵적 통계 학습(Artificial Grammar), 얼굴 인식, 예외 패턴 분류 등에서 CoT가 성능을 최대 36.3%p 떨어뜨린다7. o1-preview에서 인공 문법 과제 정확도가 94% -> 57.7%로 하락. 대안: 직관적 판단이 필요한 과제에는 Standard Prompting 사용.
- 토큰 비용 증가: 추론 단계가 출력에 포함되므로 응답 길이가 2-5배 증가하여 API 비용과 지연 시간이 늘어난다. 대안: 중요한 추론 과제에만 선택적으로 적용.
- 역추적 불가: 기본 CoT는 한 방향으로만 추론이 진행되어, 초기 단계의 오류가 후속 단계에 전파된다. 대안: Tree of Thoughts로 분기 탐색 + 역추적.
- 내장 추론 모델과의 중복: o1, GPT-5 thinking mode 등 추론이 내재화된 모델에서는 CoT 프롬프팅의 추가 효과가 미미하다(o3-mini +2.9%, o4-mini +3.1%)8. 치명적 시나리오: 이미 내장 추론을 수행하는 모델에 CoT를 강제하면 불필요한 비용만 발생.
실무 적용 가이드
적합한 시나리오:
- 다단계 수학 문제 해결 (GSM8K 수준 이상)
- 논리적 추론이 필요한 질의응답
- 코드 디버깅 (단계별 실행 추적)
- 복잡한 의사결정 과정 설명이 필요한 경우
부적합한 시나리오:
- 패턴 인식, 직관적 분류 과제 (CoT가 오히려 해로움)
- 단순 사실 검색 ("한국의 수도는?")
- 100B 미만 소형 모델에서의 추론
- 이미 내장 추론을 수행하는 모델 (o1, o3 등)
도입 판단 기준:
- 모델이 100B+ 파라미터이거나 최신 추론 모델이 아닌 경우 -> CoT 적용 권장
- 과제가 2단계 이상의 논리적 추론을 요구하는 경우 -> CoT 적용 권장
- 정확도가 비용보다 중요한 경우 -> CoT + Self-Consistency 적용
- 예시 설계 비용을 줄이고 싶은 경우 -> Zero-shot CoT 적용
- 탐색/계획이 필요한 복잡한 문제 -> Tree of Thoughts 적용
추천 설정:
- Few-shot CoT 예시 수: 3-8개 (Wei et al. 권장)
- Self-Consistency 샘플 수: 5-40개 (정확도-비용 트레이드오프)
- Zero-shot CoT 트리거 문구: "Let's think step by step" (가장 높은 효과, Kojima et al. 실험 결과)
형제 방법론: Few-shot Prompting, Prompt Engineering


Footnotes
-
Wei, J. et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." NeurIPS 2022. arXiv:2201.11903 ↩ ↩2 ↩3 ↩4 ↩5
-
Kojima, T. et al. (2022). "Large Language Models are Zero-Shot Reasoners." NeurIPS 2022. arXiv:2205.11916 ↩ ↩2
-
Zhang, Z. et al. (2022). "Automatic Chain of Thought Prompting in Large Language Models." arXiv:2210.03493 ↩
-
Wang, X. et al. (2022). "Self-Consistency Improves Chain of Thought Reasoning in Language Models." ICLR 2023. arXiv:2203.11171 ↩ ↩2
-
Yao, S. et al. (2023). "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." NeurIPS 2023. ↩ ↩2
-
Chen et al. (2026). "Revisiting Chain-of-Thought Prompting: Zero-shot Can Be Stronger than Few-shot." arXiv:2506.14641 ↩
-
Sprague, Z. et al. (2024). "Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse." arXiv:2410.21333 ↩
-
Meincke, L. et al. (2025). "The Decreasing Value of Chain of Thought in Prompting." Wharton Generative AI Labs. ↩