Grok 4
xAILLM자연어 처리컴퓨터 비전오디오 처리256K 토큰
2025년 7월 10일Proprietary
Grok
4란?
xAI가 2025년 7월 10일에 출시한 플래그십 AI 모델이다. 일론 머스크가 이끄는 xAI의 Colossus 슈퍼컴퓨터에서 훈련되었으며, "공리 기반(axiom-based) 1차 원리 추론"을 핵심 설계 철학으로 내세운다. SuperGrok 및 Premium+ 구독자와 xAI API를 통해 사용할 수 있다.
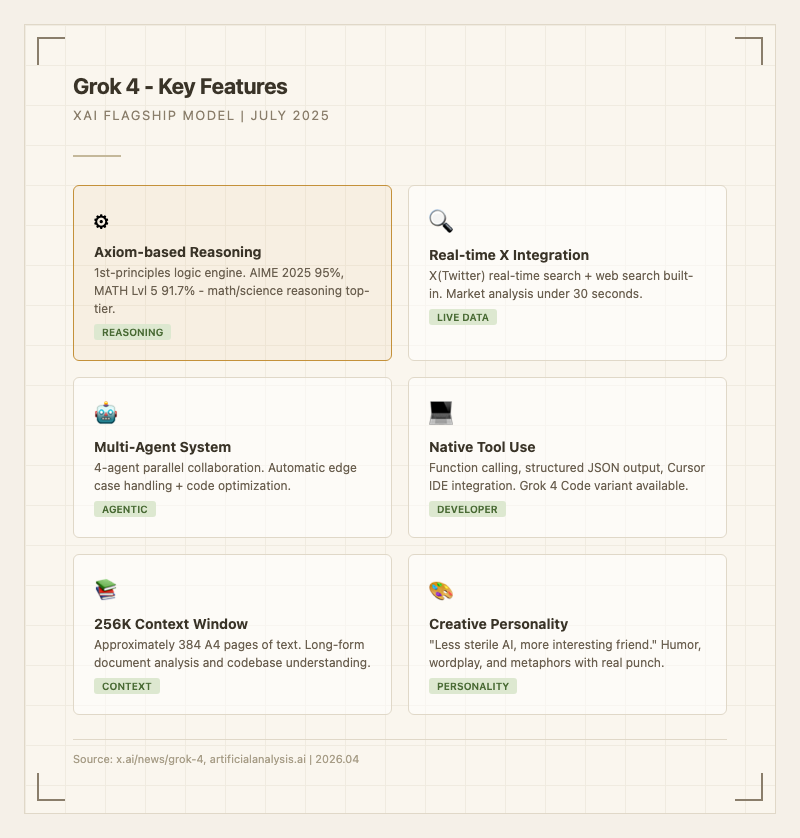
주요 특징Grok 4의 차별점은 크게 다섯 가지로 요약된다.
1차 원리 추론 엔진: 기존 패턴 매칭 방식과 달리 공리 기반 논리로 문제를 풀어간다. 수학 벤치마크에서 이 접근법이 빛을 발하는데, AIME 2025에서 95%, MATH Level 5에서 91.7%를 기록했다 (출처: 공식 발표, community benchmarks). 실사용자들도 수학 문제 풀이에서 "단계별로 왜 그런지 설명해주는 느낌"이라는 반응이 많다.
X(트위터) 실시간 통합: 다른 모델과 가장 크게 차이나는 부분이다. X 피드에서 실시간 정보를 끌어와서 시장 분석이나 트렌드 파악을 30초 안에 해치운다는 사용자 평가가 많다. 기자나 트렌드 워처들 사이에서 "소셜 미디어 감정 분석에 유일하게 쓸만한 AI"라는 평가를 받는다.
멀티 에이전트 시스템: Grok 4.20 버전부터 4개 에이전트가 병렬로 협업하는 구조를 도입했다. 코드 작성 시 에지 케이스를 자동으로 고려하고, 반응형 UI 코드를 요청하면 최적화된 구조를 제안해서 작업 시간을 절반으로 줄여준다는 한국 개발자 후기가 있다.
네이티브 도구 사용: 함수 호출(function calling), 구조화된 JSON 출력, 웹 검색, 코드 실행이 모델에 기본 내장되어 있다. Grok 4 Code 변형은 Cursor IDE와 직접 연동된다.
256K 컨텍스트 윈도우: A4 약 384페이지 분량의 텍스트를 한 번에 처리한다. 긴 문서 분석이나 대규모 코드베이스 이해에 유리하다.
할 수 있는 것
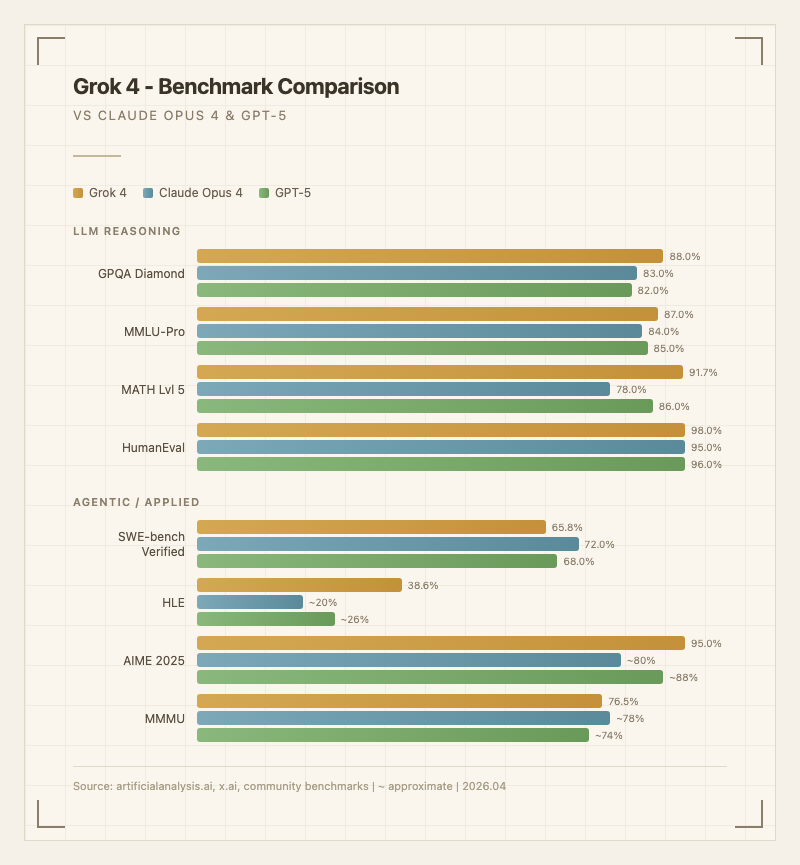
수학/과학 추론: Grok 4가 가장 강한 영역이다. 대학원 수준 과학 문제(GPQA Diamond 88%), 고난도 수학(MATH Lvl 5 91.7%, AIME 2025 95%)에서 최상위권 성능을 보인다. 한국 수능 수학 영역 LLM 평가에서 97.8/100으로 2위를 기록했다 (출처: 2026 한국 CSAT LLM 평가 리더보드). Reddit에서는 "수학 문제는 Grok 4가 가장 믿을 만하다"는 의견이 자주 올라온다.
코딩: HumanEval에서 약 98%로 코드 생성 능력이 뛰어나다. 다만 SWE-bench Verified(실제 소프트웨어 버그 수정)에서는 65.8%로 Claude Opus(72%)나 GPT-5(68%)보다 뒤처진다 (출처: community benchmarks). Reddit r/grok 커뮤니티에서는 "벤치마크는 높은데 실제 복잡한 코딩 세션에서는 실망스럽다"는 경고가 반복적으로 올라온다. 간단한 코드 생성은 빠르고 정확하지만, 대규모 프로젝트의 전략적 계획(systematizing)은 경쟁 모델 대비 약하다는 평가다.
실시간 정보 검색: X와 웹 검색이 내장되어 있어서 최신 뉴스, 소셜 미디어 트렌드, 주가 동향 같은 실시간 데이터에 접근할 수 있다. "플러그인 없이 바로 최신 정보를 가져오는 건 Grok만의 장점"이라는 사용자 평가가 있다.
창의적 대화: 사용자 리뷰에서 일관되게 등장하는 강점이다. "차가운 AI가 아니라 흥미로운 친구와 대화하는 느낌", "유머, 말장난, 비유가 진짜 펀치가 있다"는 평가다. 브레인스토밍이나 크리에이티브 작업에서 다른 모델을 압도한다는 의견이 많다.
한계: 전략적 계획 수립, 복잡한 워크플로우 설계, 꼼꼼한 팩트체킹에서는 Claude나 GPT 대비 약하다는 평가가 많다. 특히 코딩에서 "벤치마크 수치와 실제 체감이 다르다"는 피드백이 r/grok에서 반복된다.
성능
벤치마크 점수
| 벤치마크 | Grok 4 | 비고 |
|---|---|---|
| GPQA Diamond | 88.0% | 대학원 수준 과학 (출처: 공식 발표) |
| MMLU-Pro | 87.0% | 전문 지식 (출처: 공식 발표) |
| MATH Lvl 5 | 91.7% | 고난도 수학 (출처: community benchmarks) |
| HumanEval | ~98% | 코드 생성 (출처: 공식 발표) |
| SWE-bench Verified | 65.8% | 실제 버그 수정 (출처: community benchmarks) |
| AIME 2025 | 95% | 수학 올림피아드 (출처: 공식 발표) |
| HLE | 38.6% | Humanity's Last Exam (출처: community leaks) |
| MMMU | 76.5% | 멀티모달 이해 (출처: 공식 발표) |
Artificial Analysis Intelligence Index v4 기준 42점(126개 모델 중 30위)을 기록했다. 출시 당시 초기 인덱스에서는 73점으로 o3(70점), Gemini 2.5 Pro(70점)를 앞섰지만, 이후 평가 기준이 변경되면서 순위가 조정되었다 (출처: artificialanalysis.ai).
실사용 체감벤치마크만 보면 최상위권이지만, 실제 사용감은 좀 다르다.
- 속도가 느리다: 출력 속도 52.9 tokens/sec로 평균 이하(중간값 73.4 t/s). 첫 토큰 생성까지 약 15초 걸린다. 기본 질문에 8-12초, 복잡한 질문에 25-40초가 소요된다는 한국 사용자 후기가 있다.
- 수학은 진짜 강하다: "수학 문제만큼은 다른 모델에 맡기고 싶지 않다"는 반응이 많다.
- 코딩은 기대 이하: 벤치마크 수치가 높지만 "실제 복잡한 코딩 세션에서는 실망"이라는 Reddit 의견이 반복된다. 간단한 코드는 빠르게 뱉어내지만, 대규모 프로젝트의 체계적 계획은 약하다.
- 창의성은 최고: "유머와 비유에서 다른 모델을 압도한다"는 평가가 지배적이다.
경쟁 모델 대비: Claude Opus 4.6이 코딩/안정성/팩트체킹에서 1위, GPT-5.4가 범용/컴퓨터 사용에서 1위, Grok 4는 창의성/가격에서 강세를 보인다. "완벽한 1등은 없고, 용도에 맞는 모델을 골라야 한다"는 게 커뮤니티 합의다.
사용 방법
웹/앱 (일반 사용자)
grok.com에서 무료로 사용할 수 있다. 무료 티어는 2시간당 약 10회 프롬프트 제한이 있다. 더 많은 사용량이 필요하면 SuperGrok(40/월)에 가입하면 된다. 모델 메뉴에서 "Grok 4"를 수동 선택해야 활성화되는 점에 주의.
API (개발자)
xAI API(api.x.ai)를 통해 접근한다. 모델 ID는 grok-4-0709(별칭: grok-4, grok-4-latest). OpenAI SDK 호환 형식이라 기존 코드에서 base_url만 바꾸면 된다.
python
from openai import OpenAI
client = OpenAI(
api_key="YOUR_XAI_API_KEY",
base_url="https://api.x.ai/v1"
)
response = client.chat.completions.create(
model="grok-4",
messages=[{"role": "user", "content": "Hello Grok 4"}]
)
공식 문서: docs.x.ai
가격
구독 플랜
| 플랜 | 월 요금 | 주요 혜택 |
|---|---|---|
| Free | $0 | ~10 프롬프트/2시간, 기본 검색 |
| SuperGrok Lite | $10 | 이미지/영상 생성, 높은 사용량 |
| SuperGrok | $30 | DeepSearch, 무제한 이미지 생성 |
| SuperGrok Heavy | $300 | 최대 용량, Grok 4 Heavy 접근 |
X Premium+($40/월)에도 Grok 접근이 포함되어 있어서, X 소셜 미디어 기능까지 필요하다면 이쪽이 더 합리적일 수 있다.
API 비용
- Input: $3.00 / 1M 토큰
- Output: $15.00 / 1M 토큰
- Cached Input: $0.75 / 1M 토큰
- Blended (3:1): $6.00 / 1M 토큰
경쟁사 대비: Claude Opus 4.6(25)보다는 저렴하고, GPT-5.4(15)와 비슷하다. Grok 4.20(6)이 출시되면서 "무거운 추론은 Grok 4, 가벼운 작업은 4.20으로" 쓰는 패턴이 생겼다. 한국 사용자들 사이에서 SuperGrok Heavy의 $300/월은 "일반인에게는 너무 비싸다"는 반응이 지배적이다.
한국어 토큰 효율: 한국어 토큰 효율에 대한 공식 데이터는 미공개다. 한국어 사용 시 영어보다 토큰 소비가 많을 가능성이 높으며, 실사용자들은 "한국어 품질이 경쟁사 대비 부족하고, 도메인 전문 텍스트에서 직역체가 나온다"고 보고하고 있다.

기술 사양
| 항목 | 상세 |
|---|---|
| 개발사 | xAI (Elon Musk) |
| 출시일 | 2025년 7월 10일 |
| 모델 ID | grok-4-0709 |
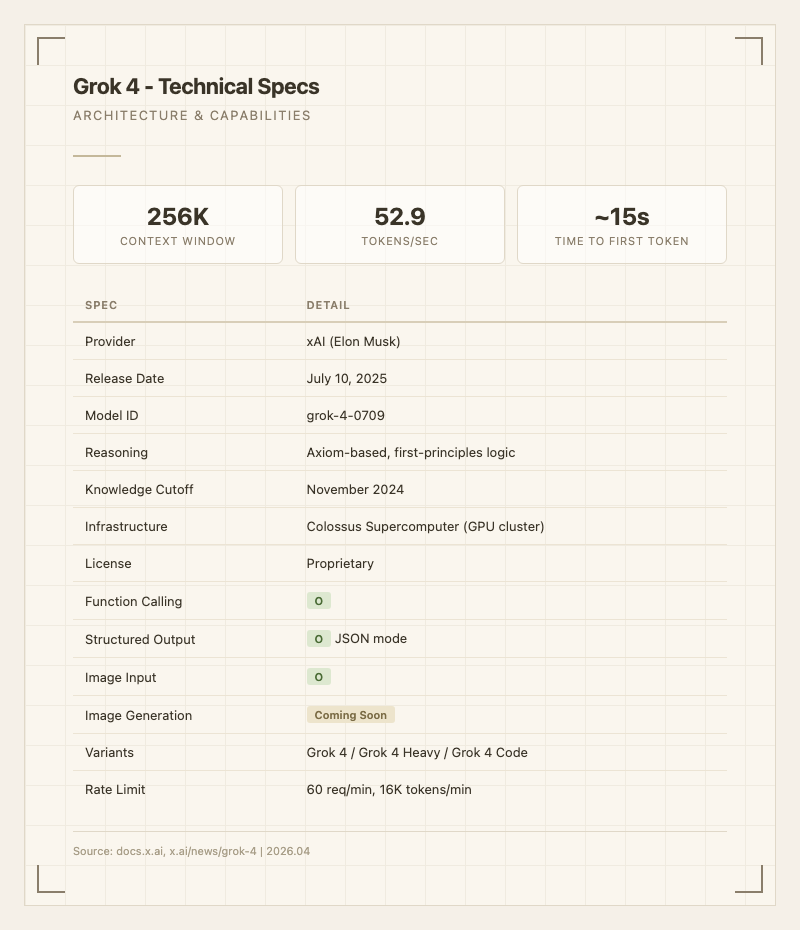
| 컨텍스트 윈도우 | 256,000 토큰 |
| 추론 방식 | Axiom-based, first-principles logic |
| 학습 데이터 기준일 | 2024년 11월 |
| 인프라 | Colossus Supercomputer |
| 라이선스 | Proprietary |
| 변형 | Grok 4 / Grok 4 Heavy / Grok 4 Code |
| 출력 속도 | 52.9 tokens/sec |
| TTFT | ~15초 |
| Rate Limit | 60 req/min, 16K tokens/min |
| 지원 기능 | Function calling, JSON mode, Image input |
파라미터 수는 공식 미공개. Colossus 슈퍼컴퓨터의 GPU 클러스터에서 훈련되었으며, xAI는 훈련 효율을 6배 향상시켰다고 밝혔다. 후속 모델인 Grok 4.20은 컨텍스트 윈도우를 2,000,000 토큰으로 대폭 확장했다.
참고 자료


스펙
컨텍스트 윈도우
256K 토큰
라이선스
Proprietary
출시일
2025년 7월 10일
학습 마감일
2025년 7월 31일
가성비 지수
0.5
API 가격 (혼합)
입력 $3.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$3.00 / 1M 토큰
출력 (Completion)
$15.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
95.0
복잡한 지시사항 이해 및 수행
일반지식
87.0
다양한 분야 지식 및 이해
코딩
85.3
코드 생성, 버그 수정, 소프트웨어 엔지니어링
멀티모달
76.5
이미지, 비디오 등 멀티모달 이해
Provider
xAI
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1483.0 | elo |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Grok 4 | 92.0 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |