Grok 4 Fast
xAILLM자연어 처리컴퓨터 비전오디오 처리2.0M 토큰
2025년 9월 19일Proprietary
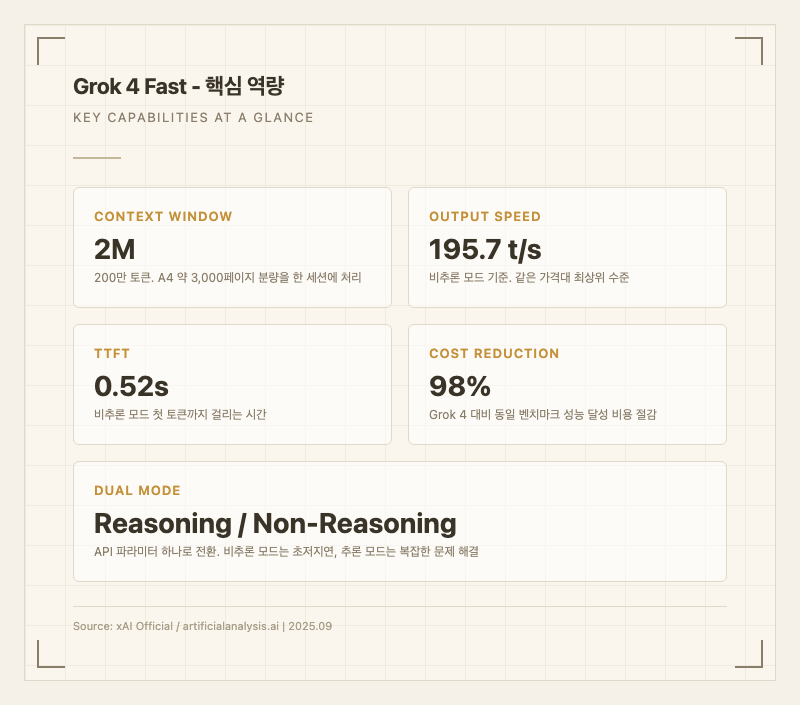
Grok 4 Fast는 xAI가 2025년 9월에 출시한 효율 특화 멀티모달 모델이다. Grok 4의 추론 능력을 거의 그대로 유지하면서 지연 시간과 비용을 대폭 낮춘 모델로, 추론(reasoning) 모드와 비추론(non-reasoning) 모드를 API 파라미터 하나로 전환할 수 있다. 입력 0.50/1M 토큰이라는 파격적인 가격에 200만 토큰 컨텍스트 윈도우까지 제공한다.
주요 특징
Grok 4 Fast의 핵심은 "프리미엄 성능을 경제적 가격에"라는 포지셔닝이다. Grok 4 대비 벤치마크에서 비슷한 성능을 내면서 사고 토큰(thinking tokens)을 평균 40% 적게 사용한다. 이로 인해 동일 성능 달성 비용이 Grok 4 대비 98% 절감된다 (출처: xAI 공식 발표).
다섯 가지 핵심 차별점:
-
추론/비추론 모드 전환: API의
reasoning.enabled파라미터 하나로 추론 모드를 켜고 끌 수 있다. 비추론 모드에서는 TTFT 0.52초로 거의 즉각 응답하고, 추론 모드에서는 복잡한 문제를 단계적으로 풀어낸다. -
200만 토큰 컨텍스트 윈도우: 현존 프론티어 모델 중 최대 수준이다. A4 용지 약 3,000페이지 분량의 텍스트를 한 번에 처리할 수 있어, 대규모 코드베이스나 법률 문서 전체를 한 세션에 올려놓고 작업할 수 있다.
-
도구 사용 강화 학습(Tool-use RL): 사전학습 후 웹 검색, 코드 실행 등 도구 호출을 end-to-end로 강화 학습했다. 단순히 도구를 호출하는 수준이 아니라, 언제 도구를 사용할지 판단하는 능력이 훈련되어 있다.
-
속도: 비추론 모드에서 초당 약 195.7 토큰을 생성한다 (출처: artificialanalysis.ai). 같은 가격대 모델 중 최상위 수준의 처리 속도다.
-
X 플랫폼 실시간 검색 통합: LMArena Search Arena에서 grok-4-fast-search가 Elo 1163으로 1위를 기록했다 (출처: LMArena). 실시간 뉴스나 소셜 미디어 트렌드 파악에서 다른 모델 대비 확실한 우위가 있다.
실사용자들은 특히 속도 면에서 인상적이라는 반응이 많다. "컨텍스트 스위칭할 시간도 안 될 만큼 빠르지만, 플로우를 유지하기엔 충분히 빠르다"는 개발자 후기가 대표적이다 (출처: DEV Community). 다만 Reddit r/grok 커뮤니티에서는 "벤치마크만 믿지 말고 실제 코딩 세션에서 테스트해보라"는 경고도 있다. 긴 코딩 작업에서 요구사항을 잊거나 결과물이 깨지는 경우가 보고되었다.
할 수 있는 것
Grok 4 Fast는 범용 모델이지만, 특히 다음 영역에서 실사용자들이 가치를 체감하고 있다.
실시간 리서치와 트렌드 분석: X 플랫폼 데이터를 즉시 반영하는 DeepSearch 기능이 강점이다. 시장 분석, 실시간 이슈 리서치를 30초 안에 처리한다는 사용자 평가가 많다 (출처: 한국어 사용 후기). 저널리스트나 트렌드 워처들 사이에서는 "소셜 미디어 감정 분석이나 최신 팩트 확인에 플러그인 없이 바로 쓸 수 있는 유일한 AI"라는 평가를 받고 있다.
대량 추론 파이프라인: 비추론 모드의 낮은 가격($0.20/1M 입력)과 빠른 속도를 활용하면, 수천 건의 문서를 분류하거나 요약하는 대량 처리 파이프라인을 경제적으로 구축할 수 있다. 추론이 필요한 복잡한 항목만 추론 모드로 전환하는 하이브리드 전략도 가능하다.
코딩 에이전트: 도구 사용 RL 훈련 덕분에 코드 실행, 웹 검색, 파일 조작을 자율적으로 수행하는 에이전트 구축에 적합하다. Cursor, Cline 등 AI 코딩 도구에서 Grok 4 Fast를 사용하는 개발자들은 "응답이 워낙 빨라서 워크플로우 자체가 바뀌었다"고 보고한다 (출처: DEV Community).
대규모 문서 분석: 200만 토큰 컨텍스트 윈도우 덕분에 전체 코드베이스, 법률 계약서 묶음, 학술 논문 다수를 한 번에 올려놓고 교차 참조하거나 요약할 수 있다.
반면 한계도 분명하다. Reddit 사용자들은 긴 코딩 세션에서 모델이 앞의 요구사항을 잊어버리는 현상을 보고했고, 이미지 생성 관련해서는 2025년 말 업데이트 이후 "활기 넘치던 이미지가 무미건조한 일반적 이미지로 바뀌었다"는 불만이 r/grok 커뮤니티에서 제기되었다 (출처: Reddit r/grok).
성능
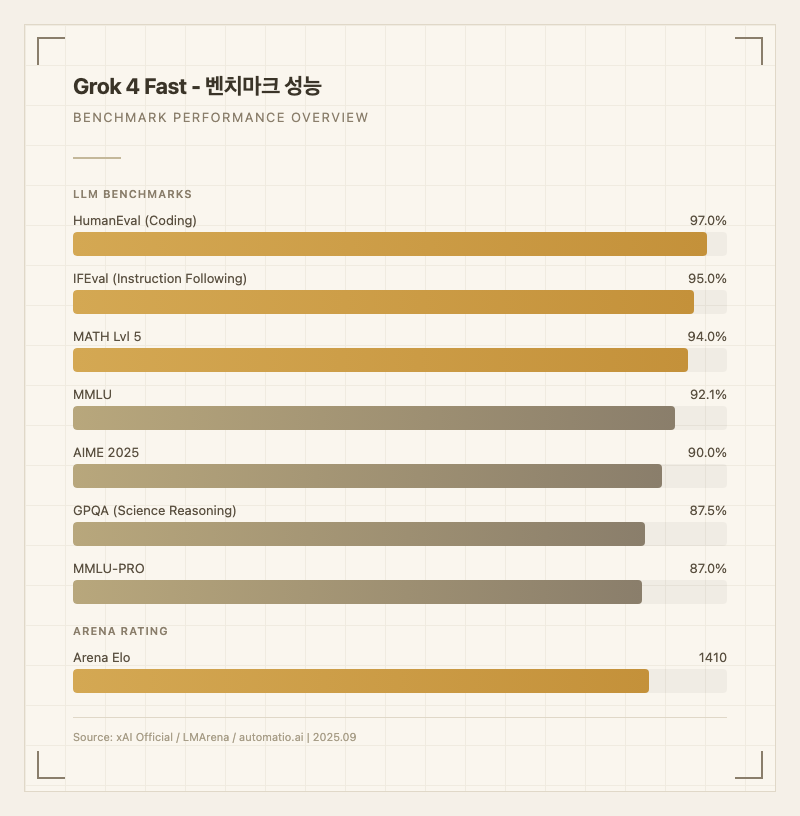
Grok 4 Fast는 비용 대비 성능에서 독보적인 포지션을 차지한다. 주요 벤치마크 결과:
| 벤치마크 | 점수 | 비고 |
|---|---|---|
| MMLU | 92.1 | 출처: 공식 발표 |
| GPQA | 87.5 | 출처: 공식 발표 |
| MMLU-PRO | 87.0 | 출처: 공식 발표 |
| MATH Lvl 5 | 94.0 | 출처: 공식 발표 |
| IFEval | 95.0 | 출처: 공식 발표 |
| HumanEval | 97.0 | 출처: 공식 발표 |
| AIME 2025 | 90.0 | 출처: automatio.ai |
| Arena Elo | 1410 | 출처: LMArena |
LMArena Text Arena에서 grok-4-fast는 8위로, Grok 4(grok-4-0709)와 대등한 수준이며 비슷한 크기의 모델들은 모두 18위 이하다 (출처: LMArena).
Artificial Analysis Intelligence Index에서 비추론 모드 23점, 추론 모드 35점을 기록했다 (출처: artificialanalysis.ai). 비추론 모드 기준 출력 속도 195.7 토큰/초, TTFT 0.52초로 같은 가격대에서 최상위 수준이다.
경쟁 모델과 비교하면:
- Grok 4 대비: 벤치마크 성능은 거의 동급이지만 가격이 15-30배 저렴하다. 입력 0.20, 출력 0.50.
- GPT-4o mini 대비: GPQA 87.5점이라는 프리미엄급 과학 추론 성능을 GPT-4o mini보다 저렴한 가격에 제공한다.
- Claude Sonnet 4 대비: Claude Sonnet 4는 SWE-bench Verified 72.7%로 코딩에서 더 안정적이라는 평가가 있다. 가격은 Claude Sonnet 4가 15.00으로 Grok 4 Fast보다 15배 비싸다.
실사용 체감에서는 벤치마크와 다소 차이가 있다. Reddit 커뮤니티의 종합 평가는 "벤치마크 숫자는 화려하지만, 실제 복잡한 코딩 작업에서는 Claude Sonnet이 더 안정적"이라는 쪽이 우세하다. 특히 긴 대화에서 맥락을 놓치는 문제, 리팩토링 시 기존 코드를 깨뜨리는 문제가 지적된다 (출처: Reddit r/grok). 다만 단순 질의응답, 요약, 분류 같은 작업에서는 가격 대비 성능이 압도적이라는 데에는 대부분 동의한다.
사용 방법
일반 사용자 (웹/앱):
- grok.com에서 무료 계정으로 바로 사용 가능하다. 무료 티어에서도 Grok 4 Fast를 포함한 최신 모델에 접근할 수 있다.
- 무료 티어는 2시간당 약 10회 요청 제한이 있다.
- SuperGrok($30/월)으로 업그레이드하면 일일 메시지 제한이 크게 완화되고 우선 라우팅이 적용된다.
개발자 (API):
- xAI API (api.x.ai)에서 직접 호출하거나, OpenRouter 등 서드파티를 통해 접근할 수 있다.
- 모델 ID:
grok-4-fast-reasoning(추론 모드),grok-4-fast-non-reasoning(비추론 모드) - 추론 모드 전환은 요청 본문의
reasoning.enabled파라미터로 제어한다. - 공식 문서: docs.x.ai
가격
Grok 4 Fast의 가격 구조는 크게 구독형(소비자)과 종량형(API)으로 나뉜다.
구독 플랜:
| 플랜 | 월 요금 | 주요 특징 |
|---|---|---|
| Free | $0 | 최신 모델 접근, 2시간당 ~10회 제한 |
| SuperGrok | $30/월 | 높은 사용량, 우선 라우팅, Grok 4/4.1 접근 |
| SuperGrok 연간 | $300/년 | 월 대비 16% 할인 (2개월 무료) |
| SuperGrok Heavy | $300/월 | 파워 유저용, 프론티어 수준 AI |
| X Premium+ 번들 | $40/월 | X 플랫폼 기능 + Grok 접근 |
API 가격:
| 모델 | 입력 (1M 토큰) | 출력 (1M 토큰) |
|---|---|---|
| Grok 4 Fast | $0.20 | $0.50 |
| Grok 4 (프리미엄) | $3.00 | $15.00 |
도구 호출(웹 검색, 코드 실행)에는 1,000회당 5.00의 추가 요금이 발생한다 (출처: xAI 공식 문서).
실사용자 가성비 평가: "이 가격에 이 성능은 미친 가성비"라는 반응이 주류다. 특히 Grok 4 대비 98% 비용 절감이라는 점에서, 대부분의 프로덕션 워크로드에서는 Grok 4를 쓸 이유가 거의 없다는 평가다. 다만 API 사용 시 도구 호출 추가 요금을 간과하기 쉽다는 지적도 있다.
한국어 토큰 효율: 한국어 토큰 효율에 대한 공식 데이터는 미공개 상태다. 영어가 가장 강한 언어이며, 한국어는 내부적으로 다른 언어로 이해한 뒤 번역하는 과정을 거치는 것으로 보인다는 한국어 사용자 평가가 있다 (출처: 나무위키). 2025년 4월 다국어 업데이트 이후 다소 개선되었으나, 주동/사동, 능동/피동 전환 등에서 여전히 부자연스러운 부분이 있다.

기술 사양
| 항목 | 사양 |
|---|---|
| 개발사 | xAI |
| 모델명 | Grok 4 Fast |
| 출시일 | 2025년 9월 19일 |
| 컨텍스트 윈도우 | 2,000,000 토큰 (200만) |
| 입력 모달리티 | 텍스트, 이미지 |
| 출력 모달리티 | 텍스트 |
| 학습 데이터 기준일 | 2025년 9월 30일 |
| 추론 모드 | 추론/비추론 전환 가능 |
| API 모델 ID | grok-4-fast-reasoning, grok-4-fast-non-reasoning |
| 출력 속도 (비추론) | 195.7 토큰/초 |
| TTFT (비추론) | 0.52초 |
| 학습 방법 | 사전학습 + 도구 사용 RL + RLHF + SFT |
| 라이선스 | 독점 (Proprietary) |
| 파라미터 수 | 미공개 |

참고 자료


스펙
컨텍스트 윈도우
2.0M 토큰
라이선스
Proprietary
출시일
2025년 9월 19일
학습 마감일
2025년 9월 30일
가성비 지수
17.0
API 가격 (혼합)
입력 $0.200/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.20 / 1M 토큰
출력 (Completion)
$0.50 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
코딩최강
97.0
코드 생성, 버그 수정, 소프트웨어 엔지니어링
지시따르기
95.0
복잡한 지시사항 이해 및 수행
수학/추론
90.5
수학, 과학, 논리적 추론
Provider
xAI
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
LLM 종합 90.7
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| AIME 2026 | 90.0 | % |
| Arena Elo |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Grok 4 Fast | 90.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |