Grok 4.20 Beta
xAILLM자연어 처리컴퓨터 비전오디오 처리2.0M 토큰
2026년 2월 17일Proprietary
Grok 4.20 Beta는 Elon Musk가 이끄는 xAI가 2026년 2월에 출시한 차세대 대규모 언어 모델이다. Grok 4.1 출시 3개월 만에 나온 모델로, 4개 AI 에이전트가 동시에 작동하는 멀티에이전트 아키텍처와 배포 후에도 매주 개선되는 Rapid Learning이 핵심이다.
주요 특징
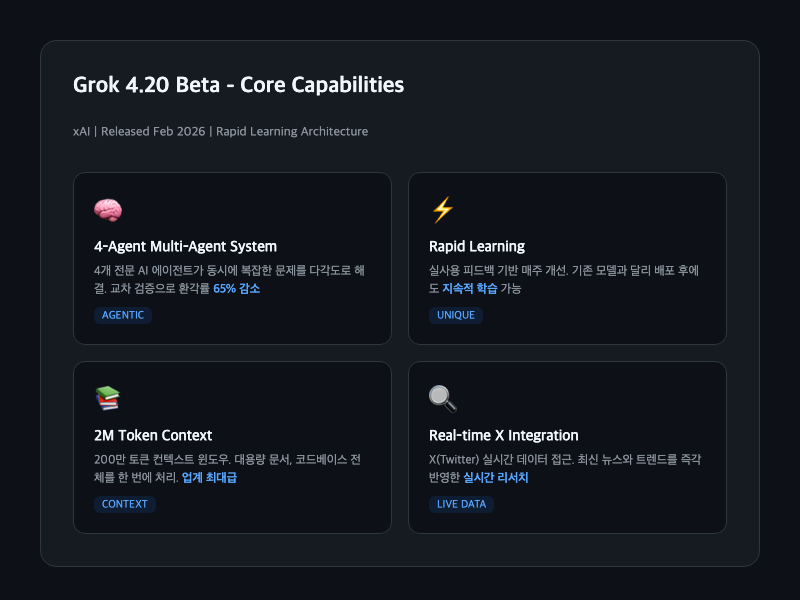
Grok 4.20 Beta가 기존 Grok 시리즈와 확실히 다른 점은 크게 네 가지다.
첫째, 4-Agent Multi-Agent System. 4개의 전문 AI 에이전트가 복잡한 문제를 동시에 다각도로 분석한다. 에이전트 간 교차 검증으로 환각률이 단일 모델 대비 65% 줄었다(약 12%에서 4.2%로). Reddit에서 실사용자들이 가장 많이 언급하는 포인트이기도 하다. "답변의 신뢰도가 확 올라갔다"는 반응이 많다.
둘째, Rapid Learning. 기존 모델들은 한번 배포하면 다음 버전까지 고정이지만, Grok 4.20은 실사용 피드백을 반영해서 매주 업데이트된다. 실제로 Beta 1(2월 17일) -> Beta 2(3월 3일) -> Stable(3월 18일)로 빠르게 진화했고, Beta 2에서 지시 따르기 개선, 환각 감소, LaTeX 지원, 이미지 검색 정확도 향상 등 5가지 업그레이드가 있었다.
셋째, 200만 토큰 컨텍스트 윈도우. 업계 최대급이다. 대형 코드베이스 전체를 한 번에 넣거나, 긴 법률 문서 묶음을 처리할 때 진가를 발휘한다.
넷째, X(Twitter) 실시간 데이터 접근. 최신 뉴스, 트렌드를 실시간으로 반영한 리서치가 가능하다. 이 점은 GPT나 Claude에 없는 Grok만의 차별점이다.
할 수 있는 것
공식적으로는 코딩, 리서치, 분석, 의료 문서 분석(사진 업로드), 멀티모달 입력(텍스트+이미지) 등을 지원한다.
실사용자 후기를 보면 상황이 더 구체적이다:
- 리서치/분석: Reddit에서 "데일리 드라이버로 쓴다"는 사용자가 많다. 실시간 X 데이터 접근과 낮은 환각률 덕분에 정보 검증이 필요한 리서치 작업에 강하다. ForecastBench에서 2위를 기록해서 예측 능력도 검증됐다.
- 주식 트레이딩: Alpha Arena Season 1.5(실시간 주식 트레이딩 대회)에서 유일하게 수익을 낸 모델이다. 실제 금융 의사결정에 활용하는 사용자가 늘고 있다.
- 코딩: 코딩도 되긴 하지만, 솔직히 이 영역은 Claude가 더 강하다. Reddit에서 "Claude is 2x better than OpenAI and 3-4x better than Grok in consistency"라는 평가가 나올 정도. Grok 4.20은 빠른 프로토타이핑이나 간단한 코드 작성에는 좋지만, 복잡한 소프트웨어 엔지니어링에는 아직 부족하다는 의견이 지배적이다.
- 창작/대화: "sterile AI가 아니라 재미있는 친구랑 얘기하는 느낌"이라는 평가. 다만 2026년 1월에 안전 정책이 강화되면서 일부 창작 요소가 제한됐고, 이에 불만을 표하는 사용자도 있다.
- 한국어: 여기가 약점이다. 한국어를 직접 처리하지 않고 내부적으로 번역 레이어를 거치는 방식이라, 특정 단어가 다른 언어로 출력되거나 어색한 표현이 나오는 경우가 있다.
성능벤치마크 수치와 실사용 체감은 다르다. 둘 다 살펴보자.
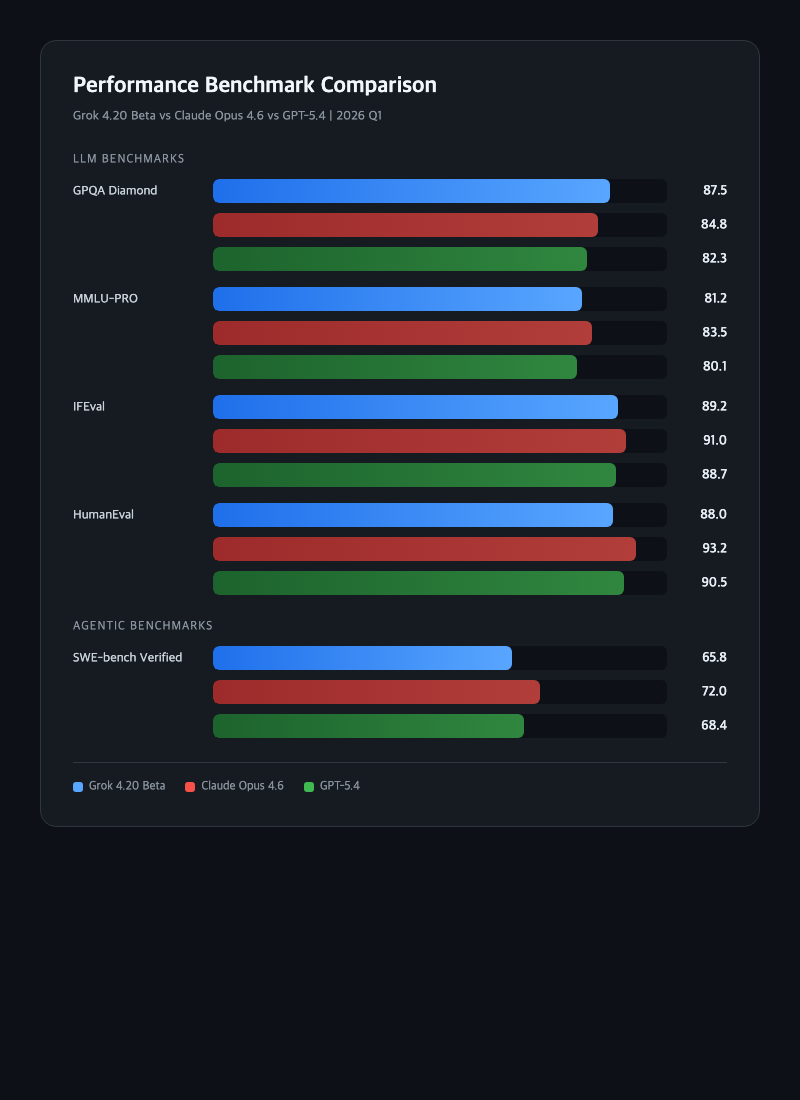
| 벤치마크 | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| GPQA Diamond | 87.5 | 84.8 | 82.3 |
| MMLU-PRO | 81.2 | 83.5 | 80.1 |
| IFEval | 89.2 | 91.0 | 88.7 |
| HumanEval | 88.0 | 93.2 | 90.5 |
| SWE-bench Verified | 65.8 | 72.0 | 68.4 |
Artificial Analysis Intelligence Index에서 48.5점(추론 모드), Agentic Index에서 68.7점을 기록했다. GPQA Diamond에서는 경쟁 모델을 앞서지만, MMLU-PRO, IFEval, HumanEval에서는 Claude Opus 4.6에 밀린다. SWE-bench Verified(코딩 에이전트)에서도 65.8%로 Claude(72.0%)보다 6% 이상 뒤처진다.
실사용 체감: 벤치마크에서 GPQA가 높다고 실제 전문 지식 QA가 좋은 건 아니다. 실사용자들은 "벤치마크는 비슷한데 코딩 일관성에서 Claude랑 차이가 난다"고 말한다. 반면 속도는 압도적이다. 약 251 토큰/초로 Claude보다 3배, GPT-5.4보다 2배 빠르다. "답변이 빠르니까 반복 작업할 때는 Grok이 더 생산적"이라는 의견도 있다.
한계: 코딩 정밀도에서 Claude에 밀리고, 한국어 처리가 불안정하다. 안전 필터가 강화되면서 일부 창작 작업에서 제한이 생겼다는 불만도 있다.
사용 방법
일반 사용자: grok.com, iOS/Android 앱에서 바로 사용 가능. X(Twitter) Premium+ 구독자는 추가 비용 없이 접근할 수 있다.
개발자 (API): xAI API를 통해 접근. OpenAI 호환 형식이라 기존 코드에서 base URL만 바꾸면 된다.
POST https://api.x.ai/v1/chat/completions
Model: grok-4.20-beta-0309
API 변형 3종:
grok-4.20-beta- Non-Reasoning (기본)grok-4.20-beta-reasoning- Reasoning Previewgrok-4.20-multi-agent-beta- Multi-Agent (4-Agent)
주의: logprobs 필드는 지원하지 않는다. 서버 사이드 도구 호출 시 토큰 비용 외에 도구 호출 비용이 별도로 발생한다.
가격
구독: X Premium+ 구독(20/월)나 Claude Pro($20/월)와 차별화되는 포인트.
API 가격:
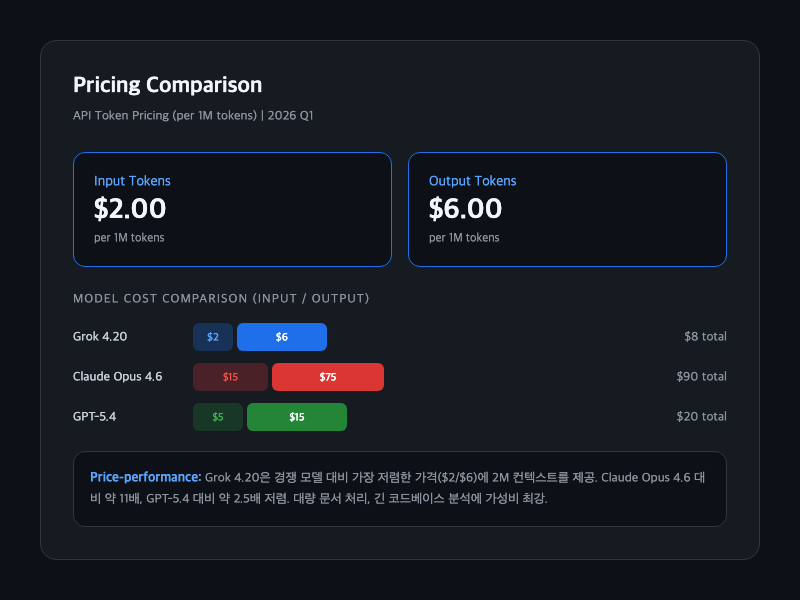
- Input: $2 / 1M tokens
- Output: $6 / 1M tokens
경쟁 모델 대비 압도적으로 저렴하다. Claude Opus 4.6(75)과 비교하면 약 11배 싸고, GPT-5.4(15)과 비교해도 2.5배 저렴하다. 200만 토큰 컨텍스트까지 합치면 대용량 처리 가성비는 독보적이다.
실사용자들도 "가격 대비 성능이 가장 좋다", "대량 문서 처리에는 Grok 외에 선택지가 없다"는 평가를 내리고 있다. 다만 한국어 토큰 효율은 영어보다 떨어진다. 번역 레이어를 거치면서 토큰 소모가 더 많아질 수 있다.
기술 사양
| 항목 | 사양 |
|---|---|
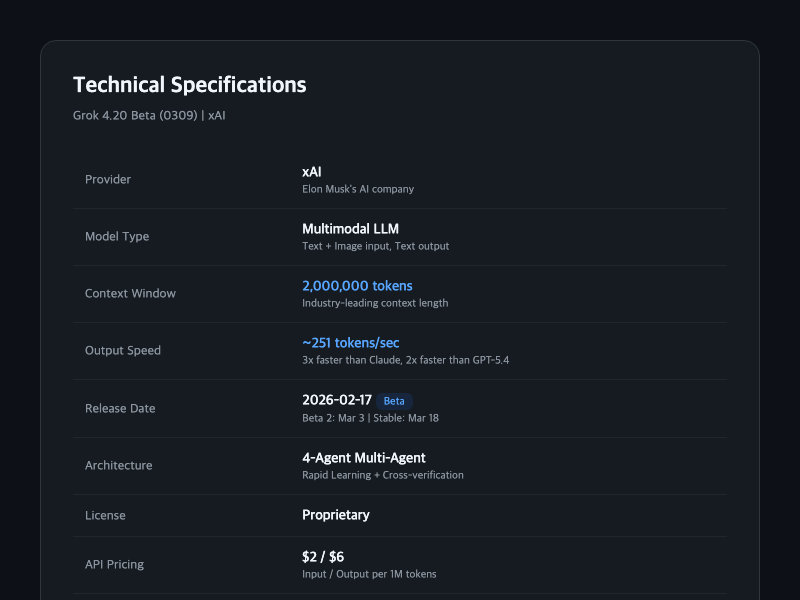
| Provider | xAI |
| Model Type | Multimodal LLM (Text+Image -> Text) |
| Context Window | 2,000,000 tokens |
| Output Speed | ~251 tokens/sec |
| Release Date | 2026-02-17 (Beta) |
| Architecture | 4-Agent Multi-Agent + Rapid Learning |
| License | Proprietary |
| API ID | grok-4.20-beta-0309 |
스펙
컨텍스트 윈도우
2.0M 토큰
라이선스
Proprietary
출시일
2026년 2월 17일
학습 마감일
2025년 12월 1일
조회수
0
API 가격 (USD 기준)
unit
$1.00 / 1M 토큰
입력 (Prompt)
$2.00 / 1M 토큰
출력 (Completion)
$6.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
89.2
복잡한 지시사항 이해 및 수행
수학/추론
87.5
수학, 과학, 논리적 추론
일반지식
81.2
다양한 분야 지식 및 이해
Provider
xAI
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GPQA | 87.5 | % |
| HumanEval | 88.0 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Grok 4.20 Beta | 85.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |