R1
DeepSeekLLM자연어 처리컴퓨터 비전오디오 처리64K 토큰
2025년 1월 20일MIT License
DeepSeek R1이란
DeepSeek R1은 중국 AI 스타트업 DeepSeek이 2025년 1월 20일에 공개한 추론 특화 대형 언어 모델이다. 671B 파라미터의 Mixture-of-Experts(MoE) 아키텍처를 사용하며, 추론 시에는 37B만 활성화된다. 가장 주목받은 점은 학습 방식이다. 기존 모델들이 의존하던 대규모 지도 학습(SFT) 대신, 강화학습(GRPO)만으로 추론 능력을 끌어올렸다. MIT 라이선스로 전체 가중치를 공개했고, 출시 일주일 만에 미국 iOS 앱스토어에서 ChatGPT를 제치고 1위를 차지하며 업계에 충격을 줬다. 학습 비용이 약 100M 추정)의 6% 수준이라는 점이 알려지면서, Nvidia 주가가 하루 18% 빠지기도 했다.
주요 특징
R1의 가장 핵심적인 차별점은 강화학습 기반 추론이다. 대부분의 추론 모델이 인간이 만든 고품질 데이터로 SFT를 먼저 하고 나서 RL로 보정하는 구조인데, R1은 SFT를 거치지 않고 GRPO(Group Relative Policy Optimization) 강화학습만으로 추론 패턴을 자체 발견했다. 정답 여부만 보상 신호로 주고, 추론 과정 자체는 모델이 알아서 만들게 했다는 것이 논문의 핵심 주장이다 (출처: 공식 논문 arxiv 2501.12948).
두 번째는 완전 공개 정책이다. 671B 풀사이즈 모델 전체를 MIT 라이선스로 공개했다. 상업적 사용, 증류, 파인튜닝이 모두 자유롭다. 여기에 Qwen 기반(1.5B/7B/14B/32B)과 Llama 기반(8B/70B) 증류 모델 6종도 함께 배포했다. 특히 14B 증류 모델이 커뮤니티에서 인기가 높은데, 개인 PC에서 돌릴 수 있으면서도 추론 성능이 상당히 나오기 때문이다.
세 번째는 사고 과정의 투명성이다. OpenAI o1이 추론 과정(Chain-of-Thought)을 숨기는 것과 달리, R1은 전체 사고 과정을 그대로 노출한다. 사용자가 모델이 어떤 경로로 답에 도달했는지 직접 확인할 수 있다. 이 투명성 덕분에 교육용이나 디버깅 용도로 선호하는 사용자가 많다.
실사용자 반응을 보면, "수학과 코딩에서는 o1과 구분이 안 된다"는 긍정 평가가 지배적이다. Reddit에서는 "ChatGPT Plus 구독을 해지하고 DeepSeek으로 갈아탔다"는 후기가 다수 올라왔다. 반면 긴 대화 세션에서 "탈선"하거나 "완전히 엉뚱한 말"을 하는 경우가 보고되며, 일상 대화나 창작 글쓰기에서는 ChatGPT나 Claude에 비해 자연스럽지 못하다는 지적이 반복된다 (출처: reddit, toksta.com).

할 수 있는 것
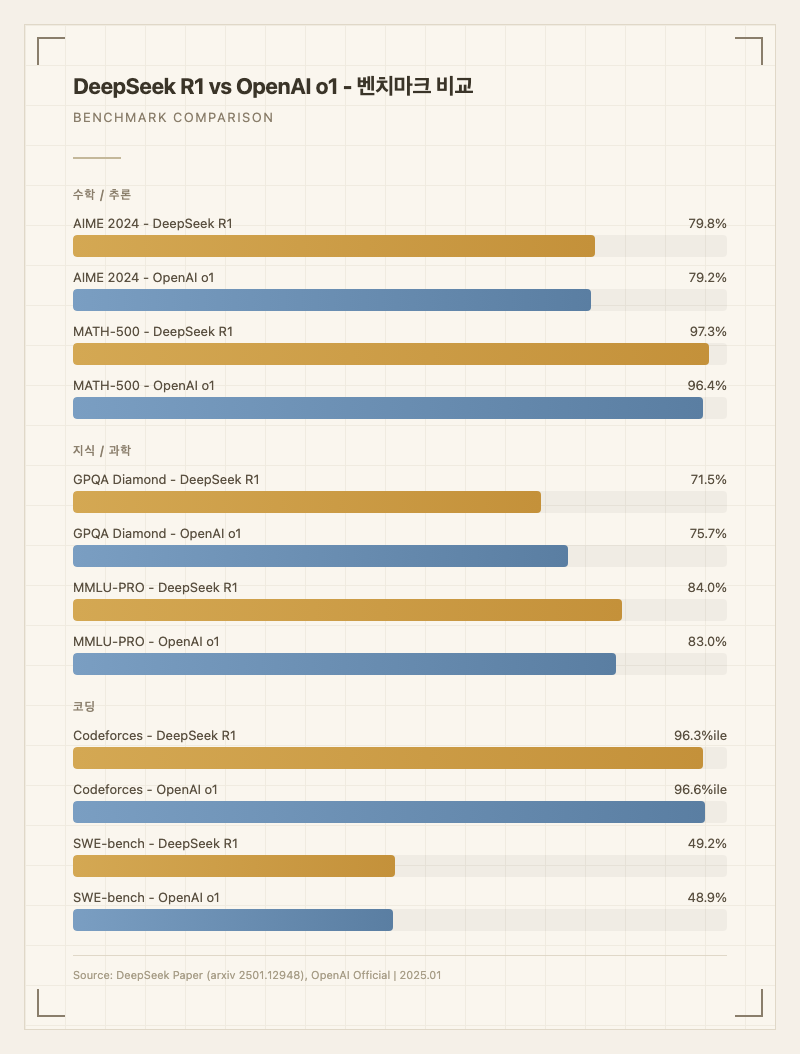
수학과 과학 추론이 R1의 가장 강한 영역이다. AIME 2024에서 79.8%, MATH-500에서 97.3%를 달성했으며, Codeforces에서는 2029 Elo(상위 96.3%)를 기록했다 (출처: 공식 논문). 실사용자들도 "수학 문제 풀이에서는 o1과 체감 차이가 없다"고 평가한다.
코딩에서도 강한 면모를 보인다. LiveCodeBench 65.9%, SWE-bench Verified 49.2%를 기록했으며, Codeforces 기준으로 o1(96.6%)과 거의 동일한 수준이다. Reddit과 개발자 커뮤니티에서 "코딩 챌린지를 한 번에 해결해줬다"는 후기가 올라오는 한편, "긴 코딩 세션에서 맥락을 놓치고 탈선하는 경우가 있다"는 경고도 함께 나온다 (출처: reddit, getbind.co).
반면 일상 대화와 창작 글쓰기는 약점이다. "대화가 끊기거나 중간에 뜬금없는 말이 섞인다", "역할극이나 창작에서 완전히 깨지는 경우가 있다"는 후기가 다수 있다. 일반적인 AI 어시스턴트 용도로는 ChatGPT나 Claude가 더 안정적이라는 것이 커뮤니티의 중론이다 (출처: neuriflux.com, toksta.com).
한국어의 경우, 풀사이즈 모델(671B)은 한국어로 답변이 나오지만 내부 사고 과정(think)은 영어나 중국어로 진행되는 경향이 있다. 클리앙 등 한국 커뮤니티에서는 "추론 능력은 오픈소스 최강인데 한국어 능력은 아직 별로"라는 평가가 대세다. 증류 모델(70B 이하)에서는 한국어만 사용하라고 지시해도 외국어가 섞여 나오는 문제가 보고된다 (출처: clien.net, wikidocs.net).
성능
| 벤치마크 | DeepSeek R1 | OpenAI o1 | 비고 |
|---|---|---|---|
| AIME 2024 | 79.8% | 79.2% | 수학 경시대회 (출처: 공식 논문) |
| MATH-500 | 97.3% | 96.4% | 수학 추론 (출처: 공식 논문) |
| GPQA Diamond | 71.5% | 75.7% | 대학원 과학 (출처: 공식 논문) |
| MMLU-PRO | 84.0% | 83.0% | 전문 지식 (출처: 공식 논문) |
| IFEval | 83.3% | - | 명령어 따르기 (출처: 공식 논문) |
| Codeforces | 96.3%ile | 96.6%ile | 경쟁 코딩 (출처: 공식 논문) |
| LiveCodeBench | 65.9% | - | 코드 생성 (출처: 공식 논문) |
| SWE-bench Verified | 49.2% | 48.9% | 실무 코딩 (출처: 공식 논문) |
| AlpacaEval 2.0 | 87.6% | - | 일반 대화 (출처: 공식 논문) |
o1과 비교하면 수학에서는 대등하거나 약간 우위(AIME +0.6p, MATH +0.9p), 과학 추론에서는 열세(GPQA -4.2p)인 구도다. 코딩은 거의 동일한 수준. 하지만 API 비용이 o1의 약 3.6% 수준이라 가성비에서는 압도적이다.
벤치마크와 실사용 체감의 괴리도 있다. 벤치마크 점수는 o1에 필적하지만, 실제 사용에서는 레이턴시가 문제다. 추론 모델 특성상 긴 사고 과정을 거치기 때문에 첫 응답까지 시간이 걸린다. 또한 "벤치마크에서는 잘 풀지만 실무 코딩에서는 맥락 유지가 불안정하다"는 지적도 있다. 중국 서버 의존도 때문에 피크 시간대(베이징 기준 오전-오후)에 "Server is busy" 오류가 빈번하다는 것도 실사용자들의 공통 불만이다 (출처: neuriflux.com, designforonline.com).
사용 방법
웹에서는 chat.deepseek.com에서 무료로 사용 가능하다. 회원 가입 후 DeepThink(R1) 모드를 선택하면 된다. 별도 구독이나 사용량 제한 없이 무료로 제공되지만, 피크 시간대에는 서버 혼잡으로 대기가 발생할 수 있다. 모바일 앱도 iOS/Android 모두 제공된다.
API 연동의 경우, platform.deepseek.com에서 API 키를 발급받아 사용한다. OpenAI SDK 호환이므로 기존 코드에서 base_url을 https://api.deepseek.com으로, model을 deepseek-reasoner로 변경하면 된다. 신규 가입 시 무료 크레딧이 제공된다.
OpenRouter, DeepInfra, Together.ai, Fireworks 등 서드파티 제공자를 통해서도 API 접근이 가능하며, 제공자별로 가격과 속도가 다르다. 로컬 구동을 원한다면 HuggingFace에서 가중치를 다운로드하거나 GGUF 양자화 버전을 사용할 수 있다. 다만 671B 풀사이즈 모델은 상당한 GPU 메모리가 필요하므로, 14B 증류 모델이 개인 사용에 현실적이다.
가격
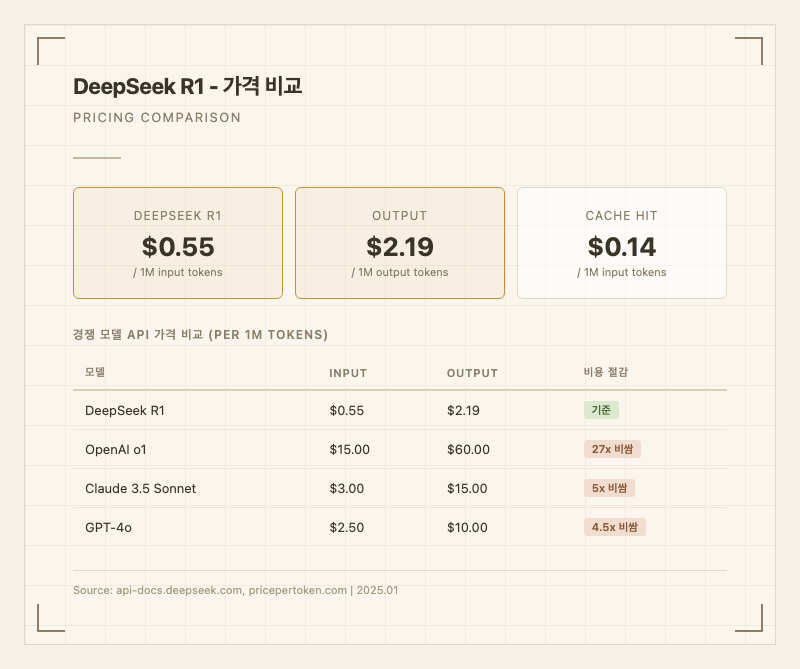
DeepSeek 공식 API 기준 입력 2.19/1M 토큰이다 (출처: api-docs.deepseek.com). 캐시 히트 시 입력 비용은 $0.14/1M 토큰으로 대폭 할인된다.
경쟁 모델과 비교하면 OpenAI o1(입력 60) 대비 약 27배 저렴하다. Claude 3.5 Sonnet(입력 15) 대비로도 5배 이상 저렴하고, GPT-4o(입력 10) 대비로도 4.5배 차이가 난다 (출처: pricepertoken.com).
서드파티 제공자를 통하면 추가 절감이 가능하다. DeepInfra 블렌딩 1.15/1M, Nebius 7-8/1M으로 비싼 편.
실사용자들의 가성비 평가는 압도적으로 긍정적이다. "o1급 성능을 o1 비용의 3.6%에 쓸 수 있다"는 것이 핵심이고, Reddit에서 "ChatGPT Plus 해지하고 DeepSeek API로 전환했다"는 후기가 반복적으로 등장한다. 다만 추론 모델 특성상 긴 사고 과정이 출력 토큰에 포함되므로, 복잡한 질문일수록 실제 비용이 예상보다 높아질 수 있다.
한국어 토큰 효율 데이터는 공식적으로 미공개 상태다. Byte-level BPE 토크나이저(128K 어휘)가 다국어 압축을 지원하긴 하지만, 한국어 특화 효율 수치는 확인되지 않는다. 비영어권 언어로 추론 시 영어 대비 20-40% 토큰 절감이 관찰되었다는 연구 결과가 있으나, 이는 한국어에 특정된 수치가 아니다 (출처: numberanalytics.com).
기술 사양
| 항목 | 사양 |
|---|---|
| 파라미터 | 671B 총 / 37B 활성화 (MoE) |
| 전문가 구성 | 256개/레이어, 8개 활성 + 1개 공유 |
| 아키텍처 | Transformer + MoE + Multi-head Latent Attention (MLA) |
| 학습 방법 | SFT 2단계 + GRPO 강화학습 2단계 |
| 학습 데이터 | 14.8T tokens (DeepSeek-V3-Base 기반) |
| 컨텍스트 윈도우 | 64,000 토큰 |
| 최대 출력 | 16,000 토큰 |
| 토크나이저 | Byte-level BPE, 128K 어휘 |
| 기반 모델 | DeepSeek-V3-Base |
| 학습 데이터 기준일 | 2024년 7월 |
| 출시일 | 2025년 1월 20일 |
| 라이선스 | MIT License |
| 학습 비용 | 약 $6M (추정) |
| 증류 모델 | 6종 (Qwen 1.5B/7B/14B/32B, Llama 8B/70B) |
R1의 핵심 아키텍처 혁신은 DeepSeek-V3에서 이어받은 것들이다. MLA(Multi-head Latent Attention)로 추론 시 KV 캐시 메모리를 대폭 절감하고, MoE 구조로 671B 파라미터 중 37B만 활성화해 연산 효율을 높였다. 여기에 GRPO 강화학습을 적용해 추론 능력을 별도로 강화한 것이 R1의 독자적 기여다. 학습 과정에서 약 600K의 추론 관련 샘플과 200K의 비추론 샘플을 사용했다 (출처: 공식 논문 arxiv 2501.12948).

참고 자료





스펙
컨텍스트 윈도우
64K 토큰
라이선스
MIT License
출시일
2025년 1월 20일
학습 마감일
2024년 7월 31일
가성비 지수
3.0
API 가격 (혼합)
입력 $0.550/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.55 / 1M 토큰
출력 (Completion)
$2.19 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
수학/추론최강
84.4
수학, 과학, 논리적 추론
일반지식
84.0
다양한 분야 지식 및 이해
지시따르기
83.3
복잡한 지시사항 이해 및 수행
Provider
DeepSeek
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GAIA | 30.3 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| R1 | 84.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |