DeepSeek V3
DeepSeekLLM자연어 처리컴퓨터 비전오디오 처리164K 토큰
2024년 12월 27일MIT
DeepSeek V3는 중국 AI 기업 DeepSeek가 2024년 12월에 공개한 671B Mixture-of-Experts(MoE) 대규모 언어 모델이다. 총 671B 파라미터 중 토큰당 37B만 활성화하는 희소 아키텍처로, 약 $5.5M이라는 파격적 저비용으로 훈련되며 오픈소스 AI 모델의 경제성에 대한 기존 상식을 완전히 뒤집은 모델이다.
주요 특징
DeepSeek V3의 가장 큰 차별점은 비용 대비 성능이다. GPT-4급 모델의 훈련에 수억 달러가 투입되던 시장에서, DeepSeek V3는 2.788M H800 GPU Hours만으로 훈련을 완료했다 (출처: 공식 기술 보고서). 이를 가능하게 한 핵심 기술은 세 가지다.
첫째, DeepSeekMoE 아키텍처. 256개의 라우팅 전문가와 1개의 공유 전문가로 구성되어 있으며, 각 토큰은 8개의 전문가만 동적으로 활성화한다. 보조 손실 없는(auxiliary-loss-free) 로드 밸런싱 전략을 최초로 도입하여 전문가 할당의 효율성을 높였다.
둘째, Multi-head Latent Attention(MLA). DeepSeek-V2에서 검증된 이 기법은 어텐션 키/밸류를 잠재 공간으로 압축하여 KV 캐시 메모리를 대폭 절감한다.
셋째, FP8 혼합 정밀도 훈련. 학습 안정성을 유지하면서도 연산 효율을 끌어올려 훈련 비용을 추가로 절감했다.
실사용자들이 체감하는 차이는 주로 속도와 가격에 집중된다. Reddit의 r/LocalLLaMA 커뮤니티에서는 "GPT-4o 대비 90% 수준의 성능을 1/50 가격에 쓸 수 있다"는 평가가 지배적이다. 특히 코딩 작업에서 응답 속도가 경쟁 모델 대비 20-30% 빠르다는 후기가 다수 있다.

할 수 있는 것
DeepSeek V3가 실제로 잘하는 영역은 코드 생성과 수학 문제 풀이다. Reddit의 r/ChatGPTCoding에서는 "다른 AI에서 막힌 코딩 문제를 DeepSeek가 바로 풀어줬다"는 후기가 반복적으로 등장한다. Python/JavaScript 코드 생성, 버그 수정, 리팩토링에서 특히 강점이 있으며, API 연동 코드 작성에서도 안정적인 결과를 보여준다.
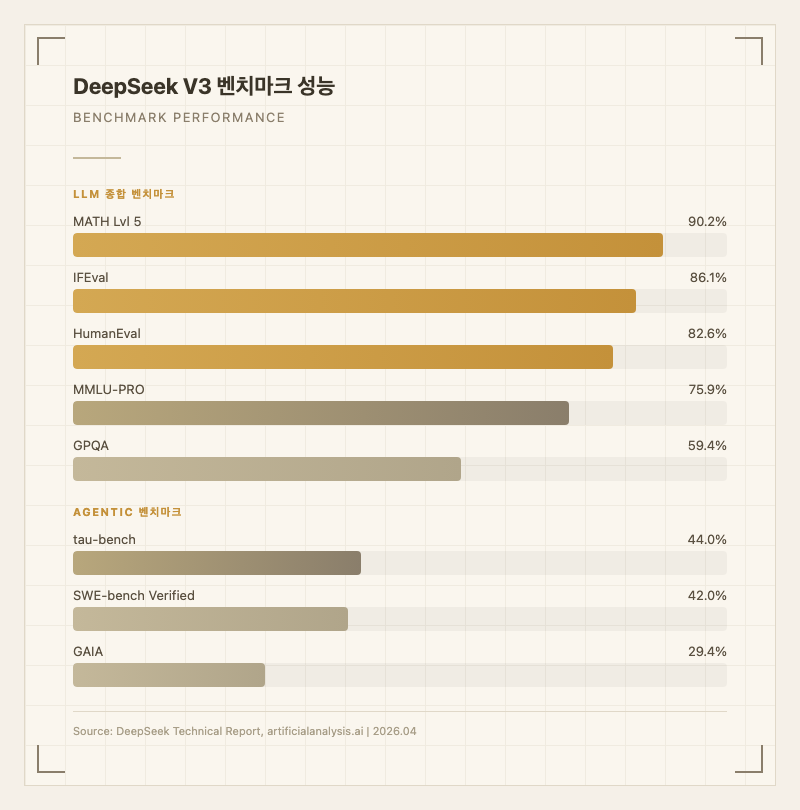
수학에서는 MATH Lvl 5 90.2%로 고급 수학 문제 풀이에서 최상위권 성능을 보여주며, 지시 따르기(IFEval 86.1%) 능력도 안정적이다.
반면 한계도 명확하다. 복잡한 시스템 설계나 다중 언어 폴리글랏 코딩에서는 GPT-4o가 여전히 우위에 있다는 평가가 많다. 일반 대화나 창의적 글쓰기에서는 "응답이 갑자기 깨지거나(garbled) 중간에 끊기는 경우가 있다"는 불만도 있다. 피크 시간대에 "Server is busy" 메시지가 빈번하게 뜨면서 워크플로우가 중단된다는 서버 안정성 문제도 실사용자들이 자주 지적하는 부분이다.
한국어 성능은 GPT-4o mini와 비슷하거나 약간 낮은 수준으로 평가된다. 한국어 데이터셋에 대한 별도 파인튜닝 없이도 준수한 수준을 유지하지만, 유창성 측면에서 프론티어 모델(GPT-4o, Claude 3.5 Sonnet)에는 미치지 못한다.
성능
| 벤치마크 | DeepSeek V3 | 비고 |
|---|---|---|
| MATH Lvl 5 | 90.2% | 고급 수학 (출처: 공식 기술 보고서) |
| IFEval | 86.1% | 지시 따르기 (출처: 공식 기술 보고서) |
| HumanEval | 82.6% | 코드 생성 (출처: 공식 기술 보고서) |
| MMLU-PRO | 75.9% | 전문 지식 (출처: 공식 기술 보고서) |
| GPQA | 59.4% | 과학 추론 (출처: 공식 기술 보고서) |
| SWE-bench Verified | 42.0% | 코드 에이전트 (출처: artificialanalysis.ai) |
| tau-bench | 44.0% | 에이전트 (출처: artificialanalysis.ai) |
| GAIA | 29.4% | 범용 에이전트 (출처: artificialanalysis.ai) |
벤치마크 수치상으로 DeepSeek V3는 LLM 종합 영역에서 강력하지만, 에이전트 영역에서는 상대적으로 약하다. SWE-bench Verified 42%, GAIA 29.4%는 같은 시기 Claude 3.5 Sonnet이나 GPT-4o에 비해 낮은 수치다.
Artificial Analysis Intelligence Index에서 DeepSeek V3(Dec 2024)는 16점으로 비교 모델 평균(22점) 이하를 기록했다. 다만 이후 출시된 V3.1(28점), V3.2(32점)에서 대폭 개선되었다 (출처: artificialanalysis.ai).
실제 코딩 테스트에서는 Claude 3.5가 85%, GPT-4o가 82%, DeepSeek V3가 78%의 정확도를 보였다 (출처: dredyson.com). 벤치마크 대비 실사용 차이는 크지 않지만, 복잡한 멀티스텝 추론이 필요한 작업에서는 격차가 벌어지는 경향이 있다. 반면 단순 코드 생성이나 수학 문제에서는 체감 성능이 프론티어 모델과 거의 동등하다는 후기가 많다.
에이전트 태스크에서의 한계는 실사용에서도 확인된다. GitHub 이슈에서 보고된 Function Calling Agent 테스트에서 DeepSeek V3는 81.5%(212/260)로, Qwen Plus 96.5%(251/260) 대비 낮은 성능을 보였다.
사용 방법DeepSeek V3는 여러 경로로 접근할 수 있다.
웹/앱 (일반 사용자): chat.deepseek.com에서 무료로 바로 사용 가능하다. 별도 구독 없이 최신 모델을 제한 없이 이용할 수 있으며, 이 점이 ChatGPT 무료 티어 대비 큰 장점으로 꼽힌다. iOS/Android 앱도 제공된다.
API (개발자): platform.deepseek.com에서 API 키를 발급받아 사용한다. OpenAI SDK 호환 API를 제공하므로, 기존 OpenAI 기반 코드에서 base URL만 변경하면 바로 전환 가능하다. 신규 가입 시 500만 토큰 무료 크레딧이 제공된다.
셀프 호스팅: MIT 라이선스이므로 Hugging Face에서 모델 가중치를 다운로드하여 자체 서버에 배포할 수 있다. 671B 모델이므로 상당한 GPU 자원이 필요하지만, 데이터 보안이 중요한 기업 환경에서는 유력한 선택지다.
서드파티 제공자: OpenRouter, Together AI 등 다양한 서드파티를 통해서도 접근 가능하다.
가격DeepSeek V3의 가격 경쟁력은 압도적이다.
웹/앱: 완전 무료. 구독 모델 없이 전체 기능 이용 가능.
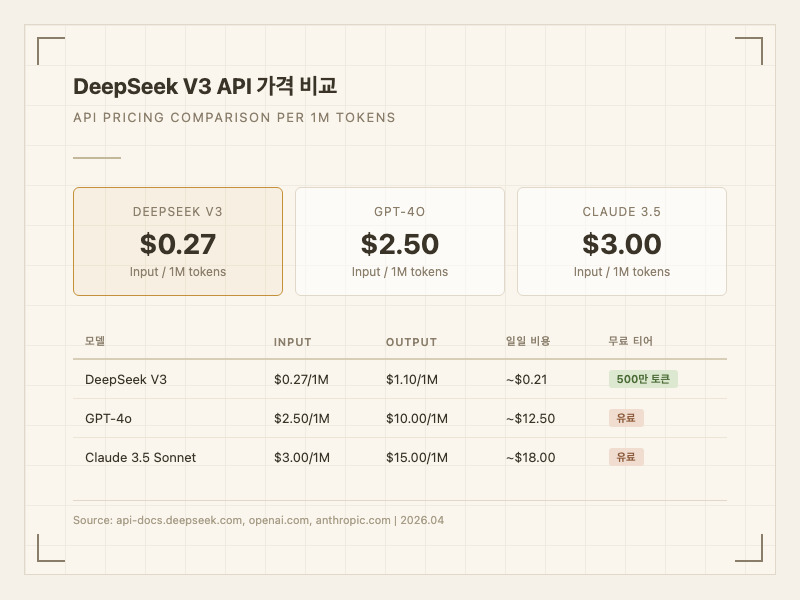
API 가격 (공식, 1M 토큰 기준):
- 입력: 0.07)
- 출력: $1.10
- 자동 컨텍스트 캐싱으로 반복 프롬프트 비용 절감
경쟁 모델과 비교하면, GPT-4o는 입력 10.00, Claude 3.5 Sonnet은 입력 15.00이다. DeepSeek V3는 입력 기준 GPT-4o 대비 약 9배, Claude 3.5 대비 약 11배 저렴하다.
실사용자들의 가성비 평가는 대체로 긍정적이다. "Sonnet 대비 15배 저렴하면서 프로그래밍 용도로는 충분하다", "하루 $0.21로 GPT-4o급 성능을 쓸 수 있다"는 반응이 많다 (출처: reddit, dev.to). 다만 "토큰을 많이 소모하는 경향이 있어서 실제 비용은 단가 차이만큼 벌어지지 않는다"는 지적도 있다.
한국어 토큰 효율 데이터는 DeepSeek V3에 대해 직접 공개된 바 없다. Byte-level BPE 128K 어휘 토크나이저를 사용하며, 다국어 압축 효율을 최적화했다고 기술 보고서에 명시되어 있다. 참고로 동일 계열 DeepSeek R1의 경우, 한국어 추론 시 영어 대비 토큰 절감률이 14-30% 범위로 보고된 바 있다 (출처: 교차 언어 추론 효율 연구).
기술 사양
| 항목 | 사양 |
|---|---|
| 총 파라미터 | 671B (6,710억) |
| 활성 파라미터 | 37B (370억) per token |
| 아키텍처 | Mixture-of-Experts (MoE) + Multi-head Latent Attention (MLA) |
| 전문가 구성 | 256 라우팅 전문가 + 1 공유 전문가, 토큰당 8개 활성 |
| 컨텍스트 윈도우 | 163,840 토큰 (163K) |
| 토크나이저 | Byte-level BPE, 128K 어휘 |
| 훈련 데이터 | 14.8T 토큰 |
| 훈련 비용 | 2.788M H800 GPU Hours (~$5.5M) |
| 훈련 정밀도 | FP8 혼합 정밀도 |
| 학습 데이터 기준일 | 2024-07-31 |
| 출시일 | 2024-12-27 |
| 라이선스 | MIT License |
DeepSeek V3는 multi-token prediction 훈련 목표를 채택하여 한 번의 forward pass에서 여러 토큰을 동시에 예측하도록 학습되었다. 이는 추론 속도 향상에도 기여한다. 14.8T 토큰의 사전훈련 후 SFT(Supervised Fine-Tuning)와 RLHF(Reinforcement Learning from Human Feedback) 단계를 거쳐 최종 모델이 완성되었다 (출처: 공식 기술 보고서).
후속 모델로 V3.1(2025년 8월, 하이브리드 추론 아키텍처), V3.2(2025년 12월, DeepSeek Sparse Attention 도입)가 출시되어 성능이 대폭 향상되었다. 현재 deepseek-chat API 엔드포인트는 V3.2 기준으로 서비스되고 있다.
프라이버시 관련 우려사항도 있다. DeepSeek의 프라이버시 정책에 따르면 키보드 타이핑 패턴, 기기 데이터, IP 주소, 전체 대화 기록이 수집된다. 2025년에는 Wiz 보안 연구원이 100만 건 이상의 채팅 기록과 API 키가 노출된 인증되지 않은 데이터베이스를 발견한 사건도 있었다 (출처: Trustpilot, 보안 연구 보고서). 데이터 보안이 중요한 환경에서는 MIT 라이선스를 활용한 셀프 호스팅을 고려할 필요가 있다.

참고 자료





스펙
컨텍스트 윈도우
164K 토큰
라이선스
MIT
출시일
2024년 12월 27일
학습 마감일
2024년 7월 31일
가성비 지수
6.9
API 가격 (혼합)
입력 $0.320/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.32 / 1M 토큰
출력 (Completion)
$0.89 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
86.1
복잡한 지시사항 이해 및 수행
일반지식
75.9
다양한 분야 지식 및 이해
수학/추론
74.8
수학, 과학, 논리적 추론
Provider
DeepSeek
DeepSeek의 다른 모델
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GAIA | 29.4 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| DeepSeek V3 | 76.2 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |