DeepSeek V3.2
DeepSeekLLM자연어 처리컴퓨터 비전오디오 처리164K 토큰
2025년 12월 1일DeepSeek License
한줄 소개
DeepSeek V3.2는 중국 AI 스타트업 DeepSeek이 2025년 12월에 출시한 대규모 언어 모델로, V3.2-Exp의 공식 후속작이다. 685B 파라미터의 Mixture-of-Experts(MoE) 아키텍처를 사용하며, 추론 시 37B만 활성화해 GPT-5급 성능을 업계 최저 수준의 비용으로 제공한다. thinking 모드와 non-thinking 모드를 모두 지원하는 최초의 통합 추론+도구 사용 모델이기도 하다.
주요 특징
DeepSeek V3.2의 핵심 차별점은 다섯 가지로 요약된다.
첫째, DeepSeek Sparse Attention(DSA)이다. 기존 full attention의 연산 비용을 획기적으로 줄이는 세밀한 희소 어텐션 메커니즘으로, 긴 컨텍스트에서도 품질 저하 없이 효율을 극대화한다. 163K 토큰 컨텍스트 윈도우를 실용적인 비용으로 처리할 수 있는 핵심 기술이다 (출처: 공식 기술 논문 arxiv.org/abs/2512.02556).
둘째, 에이전트 통합 추론이다. V3.2는 thinking을 tool-use에 직접 통합한 최초의 모델이다. 85,000개의 합성 에이전트 태스크로 학습했으며, 수학/프로그래밍/일반 추론/에이전트 코딩/에이전트 검색 등 6개 전문 도메인에서 thinking과 non-thinking 모드를 모두 지원한다 (출처: 공식 기술 논문).
셋째, 압도적 가격 경쟁력이다. 입력 0.42/1M 토큰으로 GPT-5(30) 대비 약 36배, Claude Opus 4.6(75) 대비 약 54배 저렴하다. 캐시 히트 시에는 입력 $0.028까지 떨어진다. 실사용자들 사이에서 "이 가격에 이 성능은 사기"라는 평가가 지배적이다 (출처: api-docs.deepseek.com).
넷째, 오픈 웨이트이다. DeepSeek License 하에 가중치가 공개되어 자체 호스팅과 파인튜닝이 가능하다. 프라이버시 우려가 있는 사용자는 로컬 배포로 해결할 수 있다.
다섯째, OpenAI API 호환이다. base URL과 API 키만 변경하면 기존 OpenAI SDK 기반 애플리케이션을 즉시 마이그레이션할 수 있다.
실사용자들이 체감하는 가장 큰 차이는 역시 가격이다. Reddit과 개발자 커뮤니티에서 "코딩과 수학에서는 GPT-5에 필적하면서 비용은 5-10% 수준"이라는 평가가 반복적으로 등장한다. 반면 "일상 대화나 글쓰기에서는 ChatGPT나 Claude보다 자연스럽지 않다"는 지적도 있다 (출처: neuriflux.com, mysummit.school).

할 수 있는 것
V3.2가 실제로 잘 하는 영역과 한계를 실사용자 후기 기반으로 정리하면 다음과 같다.
수학/추론: AIME 2025에서 93.1%, MATH Lvl 5에서 92.4%를 기록하며, 국제 수학 올림피아드급 문제를 거의 완벽하게 푼다. 상위 변형인 V3.2-Speciale은 IMO, ICPC World Finals에서 금메달을 획득했다. 실사용자들도 "수학 문제 풀이에서는 GPT-5와 구분이 안 된다"고 평가한다 (출처: 공식 기술 논문, benchlm.ai).
코딩: HumanEval 91%, SWE-bench Verified 73.1%로 실무 코딩에서도 강하다. 338개 프로그래밍 언어를 지원하며, 실사용자들은 "코드 생성 속도와 정확도가 가격 대비 최고"라고 평가한다. 다만 SWE-bench에서 Claude Opus 4.6(80.8%)에는 아직 미치지 못한다. "DeepSeek은 작동하는 코드를 생성하지만, 구형 검증 라이브러리를 사용하는 경우가 있었다"는 비교 리뷰도 있다 (출처: morphllm.com, thesys.dev).
에이전트 워크플로우: tau-bench에서 Airline 63.8, Retail 81.1, Telecom 96.2를 기록하며 에이전트 태스크에서 오픈소스 모델 중 최고 수준이다. 다만 TerminalBench 2.0에서는 46.4%로 Claude Opus(55.3%)와 GPT-5(52.1%)에 비해 떨어진다 (출처: 공식 기술 논문).
일상 대화/글쓰기: 여기가 약점이다. 실사용자들은 "글쓰기 품질이 ChatGPT보다 떨어지고, 안정성도 낮다"고 지적한다. "기능도 적고 프라이버시 의문도 있다"는 평가도 있다. 일반 사용자의 데일리 AI 어시스턴트로는 ChatGPT나 Claude 대비 불리하다 (출처: neuriflux.com, elephas.app).
한국어: 한국어를 어느 정도 처리할 수 있으나, 프론티어 모델 수준까지는 아니다. GPT-4o급 구형 모델에는 크게 밀리지 않는 수준이라는 평가가 있다. 한국어 토큰 효율 데이터는 미공개 상태이며, 128K Byte-level BPE 토크나이저가 다국어 압축 효율을 최적화했다고는 하나 한국어 특화 수치는 확인되지 않는다 (출처: wikidocs.net).
성능
벤치마크 점수 (thinking 모드 기준)
| 벤치마크 | DeepSeek V3.2 | 비고 |
|---|---|---|
| GPQA | 84.0% | 대학원 수준 과학 추론 (출처: 공식 논문) |
| MMLU-PRO | 86.2% | 전문 지식 (출처: 공식 논문) |
| MATH Lvl 5 | 92.4% | 수학 추론 (출처: 공식 논문) |
| IFEval | 88.5% | 명령어 따르기 (출처: benchlm.ai) |
| HumanEval | 91.0% | 코드 생성 (출처: 공식 논문) |
| SWE-bench Verified | 73.1% | 실무 코딩 (출처: 공식 논문) |
| AIME 2025 | 93.1% | 수학 경시대회 (출처: 공식 논문) |
| TerminalBench 2.0 | 46.4% | 터미널 작업 (출처: 공식 논문) |
| HLE | 40.8% | 최고난도 시험 (출처: 공식 논문) |
경쟁 모델 대비 위치
수학과 추론에서는 GPT-5에 필적하거나 앞선다. MATH Lvl 5(92.4%)는 GPT-5(약 90.8%)를 능가한다. GPQA(84.0%)와 MMLU-PRO(86.2%)는 GPT-5에 약간 뒤지지만 격차가 크지 않다.
에이전트/코딩에서는 확실히 열세다. SWE-bench Verified에서 Claude Opus 4.6(80.8%)에 7.7%p 뒤지고, TerminalBench에서도 Claude와 GPT-5 대비 명확한 차이가 있다. "자율 시스템의 두뇌로 쓰기에는 부족하다"는 평가가 있다 (출처: pritamroy.com).
벤치마크와 실사용 체감의 괴리도 있다. "벤치마크 점수는 프론티어급인데 채팅 UI 경험은 그에 미치지 못한다"는 평가가 반복된다. 서버 용량 문제로 피크 시간대(베이징 시간 오전 9시-오후 6시)에 "Server is busy" 오류가 빈번하고, 첫 토큰까지의 지연이 예측 불가능하다는 것이 실사용자들의 공통된 불만이다 (출처: neuriflux.com, thesys.dev).

사용 방법
웹/앱 (일반 사용자)
chat.deepseek.com에서 무료로 사용 가능하다. 회원 가입만 하면 별도 사용량 제한 없이 V3.2와 R1 모델에 접근할 수 있다. 모바일 앱도 제공된다. 다만 피크 시간대에는 서버 혼잡으로 인한 대기가 발생할 수 있다.
API (개발자)
DeepSeek API는 OpenAI API 포맷을 따르므로 기존 코드에서 base URL과 API 키만 변경하면 된다. deepseek-chat 또는 deepseek-reasoner 엔드포인트가 모두 V3.2에 해당한다.
- thinking 모드(reasoner): 최대 64K 출력 토큰, Chain-of-Thought 추론 지원
- non-thinking 모드(chat): 최대 8K 출력 토큰
신규 가입 시 5M 토큰 무료 크레딧이 제공된다. OpenRouter, Together AI 등 서드파티 제공업체를 통해서도 접근 가능하다.
공식 문서: https://api-docs.deepseek.com
가격DeepSeek V3.2의 가격 구조는 다음과 같다.
| 항목 | 가격 |
|---|---|
| Input | $0.28 / 1M tokens |
| Output | $0.42 / 1M tokens |
| Cache hit (input) | $0.028 / 1M tokens |
| 웹 사용 | 무료 (제한 없음) |
GPT-5 대비 입력은 36배, 출력은 71배 저렴하다. Claude Opus 4.6 대비로는 입력 54배, 출력 179배 차이가 난다. "80-90%의 품질을 5-10%의 가격에 얻을 수 있다"는 것이 실사용자들의 공통된 평가다 (출처: elephas.app, tldl.io).
오픈소스이므로 자체 서버에 배포하면 API 비용 자체가 발생하지 않는다. 685B 모델이라 상당한 하드웨어가 필요하지만, 연구 목적이나 대규모 추론 워크로드에서는 총 소유 비용이 더 유리할 수 있다.
한국어 토큰 효율 데이터는 미공개 상태다. 128K 토크나이저가 다국어 압축을 최적화했다고 하나, Gemini-3.0-Pro 같은 모델 대비 "비슷한 출력 품질을 위해 더 긴 생성 경로가 필요한 경우가 있다"는 지적이 있다 (출처: scopir.com).

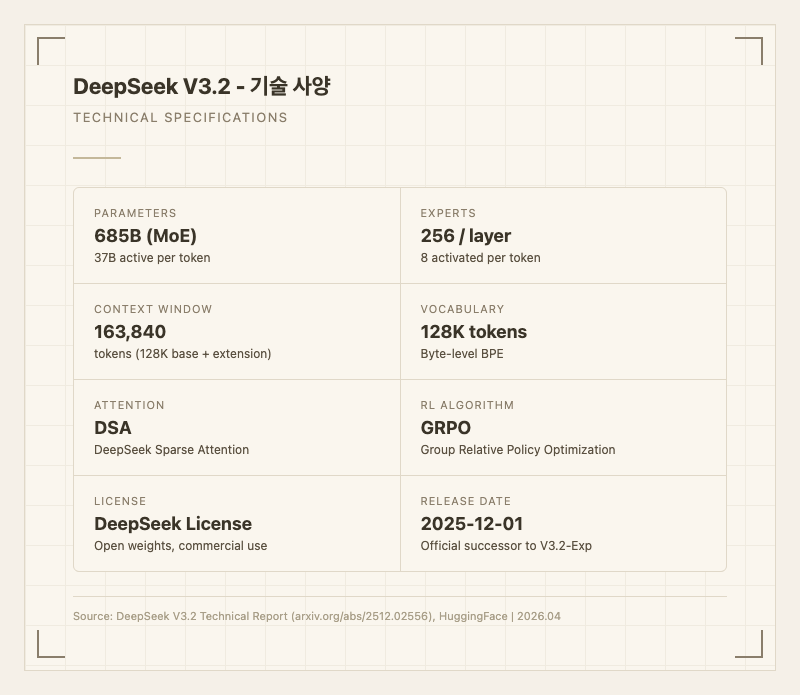
기술 사양
| 항목 | 사양 |
|---|---|
| 총 파라미터 | 685B (MoE) |
| 활성 파라미터 | 37B per token |
| 전문가 수 | 256개/레이어, 8개 활성화 |
| 컨텍스트 윈도우 | 163,840 tokens |
| 토크나이저 | Byte-level BPE, 128K 어휘 |
| 어텐션 | DeepSeek Sparse Attention (DSA) |
| 강화학습 | GRPO (Group Relative Policy Optimization) |
| 학습 도메인 | 수학, 프로그래밍, 일반 추론, 에이전트 코딩, 에이전트 검색, 일반 에이전트 |
| 라이선스 | DeepSeek License (오픈 웨이트, 상업적 사용 가능) |
| 출시일 | 2025년 12월 1일 |
| 학습 데이터 기준일 | 미공개 |
V3.2의 아키텍처는 V3에서 진화한 것으로, 핵심 혁신은 DSA(DeepSeek Sparse Attention)이다. 풀 어텐션의 연산 복잡도를 대폭 줄이면서도 장문맥에서의 품질을 유지한다. 학습 후에는 GRPO 기반 강화학습으로 추론 능력을 추가로 강화했다. 합성 데이터 파이프라인이 85,000개 에이전트 태스크를 1,800개 환경에서 자동 생성하여 에이전트 능력의 일반화 성능을 크게 높였다 (출처: 공식 기술 논문 arxiv.org/abs/2512.02556).
참고 자료





스펙
컨텍스트 윈도우
164K 토큰
라이선스
DeepSeek License
출시일
2025년 12월 1일
가성비 지수
14.4
API 가격 (혼합)
입력 $0.280/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$0.28 / 1M 토큰
출력 (Completion)
$0.42 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
88.5
복잡한 지시사항 이해 및 수행
일반지식
86.2
다양한 분야 지식 및 이해
수학/추론
77.8
수학, 과학, 논리적 추론
Provider
DeepSeek
DeepSeek의 다른 모델
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 |
|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| DeepSeek V3.2 | 87.8 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |