Claude Haiku 4.5
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리200K 토큰
2025년 10월 16일Proprietary
한줄 소개
Claude Haiku 4.5는 Anthropic이 2025년 10월 15일에 출시한 경량 AI 모델로, 소형 모델이 도달할 수 있는 성능의 한계를 새롭게 정의했다. 이전 세대 프론티어 모델이던 Claude Sonnet 4와 동급의 성능을 1/3 비용, 2배 이상의 속도로 제공하며, Haiku 라인 최초로 확장 사고(Extended Thinking)를 지원한다.
주요 특징
프론티어급 코딩 성능을 경량 모델에서 실현. SWE-bench Verified 73.3%는 대부분의 경쟁사 플래그십 모델보다 높은 수치로, Augment의 에이전틱 코딩 평가에서 Sonnet 4.5 성능의 90%에 도달한다 (출처: 공식 블로그). 실사용자들 사이에서는 "UI 작업에서 무적"이라는 평가가 많고, 스캐폴딩과 프로토타이핑 속도가 체감상 가장 빠르다는 반응이다.
Haiku 최초 Extended Thinking 지원. 추론 깊이를 제어할 수 있고, 사고 과정의 요약 또는 인터리브 출력이 가능하다. 도구 호출 사이에도 사고를 이어가는 인터리브 사고(Interleaved Thinking) 기능으로, 멀티스텝 에이전틱 작업에서 추론 품질이 크게 향상된다. Extended Thinking을 켜면 코딩과 추론 태스크에서 성능이 눈에 띄게 올라간다 (출처: 공식 문서).
Computer Use 성능 대폭 강화. OSWorld 50.7%로 이전 세대 대비 큰 폭의 도약을 보였다. GUI 자동화, 화면 기반 태스크 수행에서 경쟁 모델 대비 강점을 보인다 (출처: 공식 블로그).
안전성 최상위. Anthropic의 내부 평가에서 Claude Sonnet 4.5 및 Opus 4.1보다도 통계적으로 유의미하게 낮은 수준의 잘못 정렬된 행동을 보였다. 우려되는 행동 비율이 가장 낮은 모델이다 (출처: 공식 블로그).
속도와 비용 효율의 균형. Anthropic API 기준 98.9 tokens/sec 출력 속도(비추론 모드)로, 동일 가격대 비추론 모델 중앙값 57.4 t/s를 크게 상회한다 (출처: artificialanalysis.ai). 실사용자 테스트에서는 GPT-5 mini 대비 에이전틱 검색 쿼리 응답이 44% 더 빨랐다(평균 19.7초 vs 28.3초).

할 수 있는 것
에이전틱 코딩 워크플로. Claude Code의 경량 모드에서 기본 엔진으로 활용된다. /model haiku 명령으로 빠른 속도 개발 모드로 전환하면, plan mode에서는 Sonnet이 계획을 수립하고 Haiku가 빠르게 실행하는 하이브리드 워크플로가 가능하다. 한 사용자는 "이렇게 빨리 앱을 만들어본 적이 없다, 더 이상 Sonnet이 필요 없다"고 평가했다. 실제로 기능 구현, 코드 리팩토링, 테스트 작성 등 반복적 코딩 작업에서 체감 효율이 높다.
UI 프로토타이핑. 커뮤니티에서 "UI 작업의 speed demon"이라 불리며, 스캐폴딩과 빠른 프로토타입 생성에서 특히 강력하다. 단, 긴 세션에서는 변수 이름을 잊거나 클래스 이름을 임의로 바꾸는 경향이 있어, 짧은 단위 태스크로 나눠서 사용하는 것이 실사용자들의 공통 팁이다.
멀티에이전트 서브태스크. 대규모 에이전트 시스템에서 서브에이전트로 활용하기에 최적이다. 비용이 낮고 응답이 빨라서, 병렬 실행이 필요한 아키텍처에서 Sonnet/Opus를 오케스트레이터로, Haiku를 실행자로 배치하는 패턴이 실무에서 많이 쓰인다.
대량 텍스트 분류 및 추출. 고객 지원 티켓 분류, 이메일 라우팅, 콘텐츠 모더레이션 등 높은 처리량이 필요한 작업에서 비용 효율이 뛰어나다. 프롬프트 캐싱으로 최대 90%, 배치 처리로 50%까지 추가 비용 절감이 가능하다.
Computer Use 자동화. 웹 브라우징, 폼 입력, 스크린샷 기반 태스크 수행 등 GUI 자동화에서 경쟁 모델 대비 강점을 보인다.
주의: 안 되는 것. 긴 세션에서 컨텍스트 추적 능력이 떨어진다. 한 사용자는 "긴 세션에서 빠르게 맥락을 잃는다"고 보고했으며, 깊은 논리적 빌드가 필요한 작업에는 적합하지 않다. AIME 3.5%로 고난도 수학에서는 경쟁 모델(GPT-4o Mini 11.5%, Llama 3.3 70B 16.6%)에 크게 뒤진다.
성능
| 벤치마크 | Haiku 4.5 | 비고 |
|---|---|---|
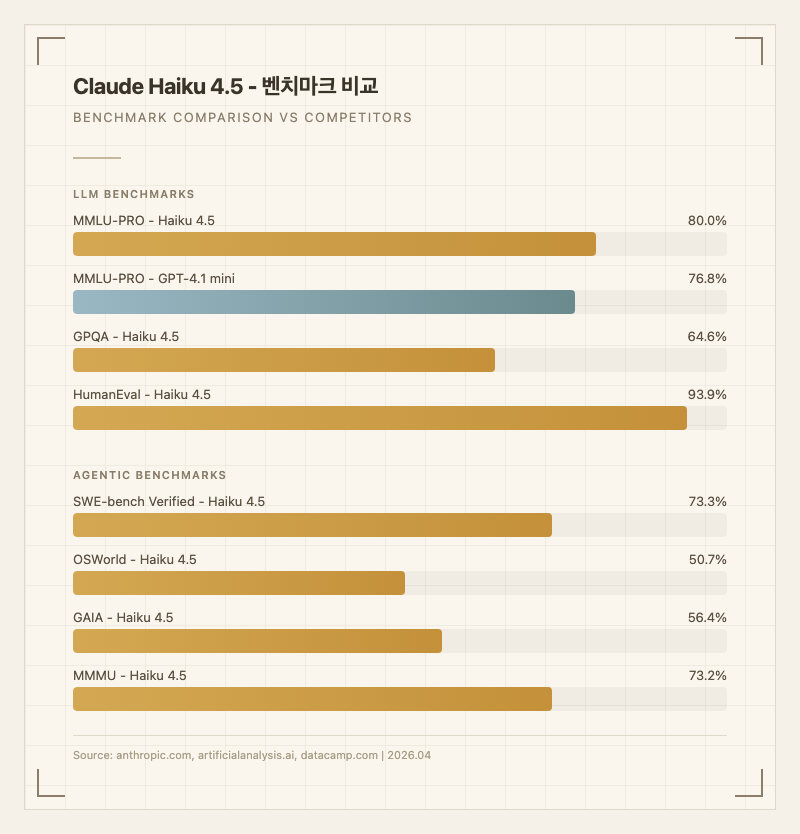
| GPQA | 64.6% | 대학원 수준 과학 추론 (출처: 공식 블로그) |
| MMLU-PRO | 80.0% | 전문 지식 (출처: 공식 블로그) |
| HumanEval | 93.9% | 코드 생성 (출처: 공식 블로그) |
| IFEval | ~86% | 지시 따르기, 경쟁 모델 대비 우위 (출처: chatlyai.app) |
| SWE-bench Verified | 73.3% | 실무 코딩, 경량 모델 중 최고 (출처: 공식 블로그) |
| OSWorld | 50.7% | Computer Use (출처: 공식 블로그) |
| GAIA | 56.4% | 복합 에이전트 태스크 (출처: 공식 블로그) |
| MMMU | 73.2% | 멀티모달 이해 (출처: datacamp.com) |
| Arena Elo | 1404 | 사용자 선호도 (출처: lmsys.org) |
벤치마크는 이렇고 실제로는 이렇다. MMLU-PRO 80.0%라는 수치는 이전 세대 Claude 3.5 Sonnet에 필적하는 수준이지만, Vals AI의 독립 평가에서는 GPQA, MMLU-Pro 같은 학문적 추론/도메인 지식 벤치마크에서 "중간 수준"이라는 평가를 받았다. 반면 코딩과 에이전틱 태스크에서는 벤치마크 수치 이상의 체감 성능을 보여준다. SWE-bench 73.3%는 단순 코드 생성이 아니라 실제 GitHub 이슈를 해결하는 능력이므로, 실무 개발자들의 체감과 일치하는 편이다.
경쟁 모델 비교. GPT-4.1 mini 대비 MMLU-PRO에서 약 3.2%p 우위(80.0% vs 76.8%), SWE-bench에서는 10%p 격차(73.3% vs 63.3%)로 코딩 영역에서 확실한 우위를 점한다. 다만 가격은 입력 기준 2.5배, 출력 기준 3.1배 비싸다. Gemini 2.5 Flash 대비로는 입력 3.3배, 출력 2.0배 비싸지만, 에이전틱 코딩에서 훨씬 높은 성능을 보인다. 실사용자 평가에서 "지능은 Haiku가 이기지만 가격은 경쟁사가 이긴다"는 것이 중론이다.
단점과 한계. 고난도 수학(AIME 3.5%)에서는 확실히 약하다. 긴 세션에서 컨텍스트 추적 능력이 저하되는 문제가 반복적으로 보고된다. 출력이 다소 장황한 경향이 있어(Artificial Analysis 기준 Intelligence Index 평가 시 8.3M 토큰 생성, 평균 3.9M 대비 2배 이상), 출력 토큰 비용이 예상보다 높아질 수 있다.
사용 방법
웹/앱 (일반 사용자). claude.ai에서 무료로 사용할 수 있으며, 모델 선택 드롭다운에서 Claude Haiku 4.5를 선택하면 된다. 무료 계정은 일일 사용량 제한이 있으며, Pro(30/유저/월) 플랜에서 더 많은 사용량을 제공한다. iOS/Android 앱에서도 동일하게 이용 가능하다.
API (개발자). 모델 ID claude-haiku-4-5-20251001로 Claude API에서 호출한다. Anthropic Messages API를 사용하며, 함수 호출, 비전(이미지 입력), Extended Thinking 모드를 지원한다. Claude Platform 외에 Amazon Bedrock, Google Cloud Vertex AI, Microsoft Foundry에서도 배포할 수 있다.
Claude Code (개발자). /model haiku 명령으로 빠른 속도 개발 모드로 전환한다. plan mode를 먼저 실행하면 Sonnet이 계획을 세우고 Haiku가 실행하는 효율적 워크플로가 가능하다.
공식 API 문서: https://platform.claude.com/docs
가격
구독 플랜. claude.ai 무료 계정으로 일일 제한 내 사용 가능, Pro 플랜 30/유저/월, Enterprise는 별도 문의.
API 가격. 입력 5.00/1M 토큰. 프롬프트 캐싱으로 최대 90% 절감, 배치 처리로 50% 절감 가능.
실사용자 가성비 평가. "벨루가 캐비어 가격이 아니라서 좋다"는 평이 대표적이다. GPT-4.1 mini(1.60)나 Gemini 2.5 Flash(2.50) 대비로는 확실히 비싸지만, SWE-bench 73.3% vs 63.3%(GPT-4.1 mini)라는 코딩 성능 격차를 고려하면 에이전틱 코딩 용도에서는 합리적이라는 의견이 많다. 반면 단순 텍스트 생성이나 분류 작업에서는 경쟁 모델이 가격 면에서 유리하다. 특히 출력이 장황한 경향이 있어(Intelligence Index 평가 시 평균의 2배 이상 토큰 생성), 출력 비용이 예상보다 높아질 수 있다는 점은 주의가 필요하다 (출처: artificialanalysis.ai).
한국어 토큰 효율. 한국어 토큰 효율 데이터 미공개. Claude 계열 모델은 영어 대비 한국어에서 약 1.5-2배의 토큰을 소비하는 것으로 알려져 있으나, Haiku 4.5에 대한 정확한 한국어 토큰 효율 수치는 Anthropic에서 공개하지 않았다.

기술 사양
| 항목 | 사양 |
|---|---|
| 제공사 | Anthropic |
| 모델 ID | claude-haiku-4-5-20251001 |
| 출시일 | 2025년 10월 15일 |
| 모델 유형 | LLM (텍스트 + 비전 입력, 텍스트 출력) |
| 컨텍스트 윈도우 | 200,000 토큰 |
| 최대 출력 | 8,192 토큰 |
| Knowledge Cutoff | 2025년 7월 |
| 라이선스 | Proprietary (상업용 API) |
| Extended Thinking | 지원 (Haiku 최초) |
| Tool Use | 코딩, Bash, 웹 검색, Computer Use |
| 다국어 | 영어, 한국어 외 주요 언어 (영어 대비 80%+ 성능) |
| 배포 플랫폼 | Claude API, AWS Bedrock, GCP Vertex AI, Azure Foundry |
| 안전성 | Claude 모델 중 가장 낮은 misalignment 비율 |

참고 자료




스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2025년 10월 16일
학습 마감일
2025년 7월 1일
가성비 지수
1.4
API 가격 (혼합)
입력 $1.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$1.00 / 1M 토큰
출력 (Completion)
$5.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
86.0
복잡한 지시사항 이해 및 수행
코딩
83.6
코드 생성, 버그 수정, 소프트웨어 엔지니어링
일반지식
80.0
다양한 분야 지식 및 이해
멀티모달
73.2
이미지, 비디오 등 멀티모달 이해
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo | 1404.0 | elo |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude Haiku 4.5 | 76.5 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |