Claude Opus 4.5
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리200K 토큰
2025년 11월 25일Proprietary
한줄 소개
Claude Opus 4.5는 Anthropic이 2025년 11월 24일에 출시한 최상위 프리미엄 AI 모델이다. "가장 지능적이고, 가장 효율적이며, 코딩과 에이전트와 컴퓨터 사용에서 세계 최고"라는 수식어를 달고 나왔다. 이전 세대인 Opus 4 대비 성능은 올리면서 가격은 3분의 1로 낮춘 것이 핵심 포인트다.
주요 특징
Opus 4.5의 가장 큰 차별점은 토큰 효율성이다. 같은 문제를 풀 때 Sonnet 4.5 대비 출력 토큰을 최대 76% 적게 쓴다 (출처: 공식 블로그). 코딩 벤치마크에서도 medium effort 수준에서 Sonnet 4.5의 최고 점수를 맞추면서 토큰은 훨씬 적게 쓰는 식이다. 실사용자들 사이에서도 "같은 작업을 시켰는데 응답이 짧고 핵심만 담겨 있다"는 평가가 나온다.
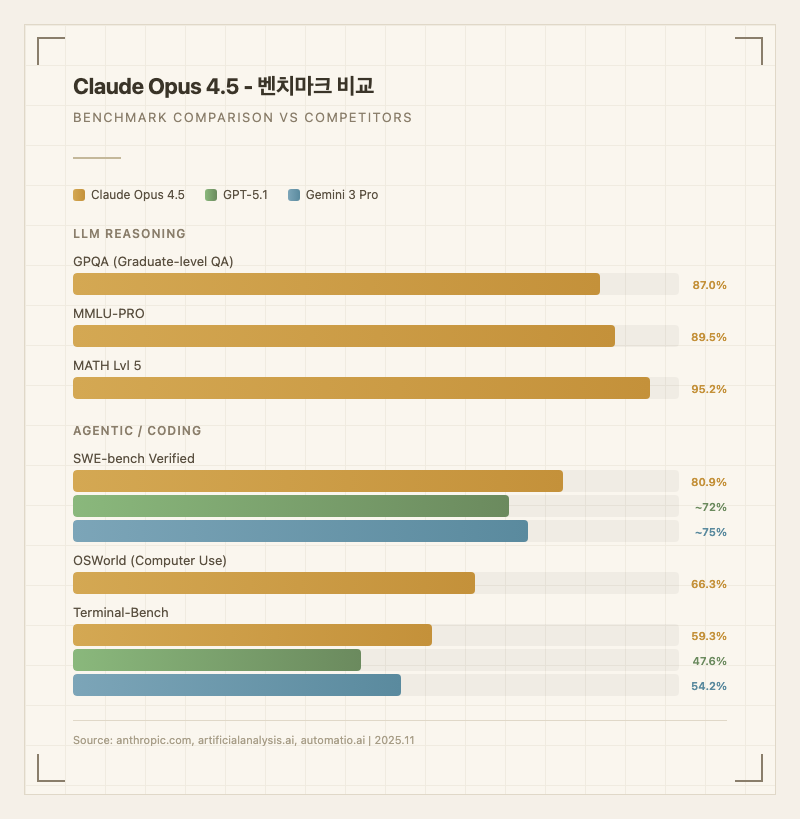
두 번째로, 에이전틱 작업에서의 압도적 성능이다. SWE-bench Verified 80.9%는 출시 당시 모든 AI 모델 중 최초로 80%를 넘긴 기록이다 (출처: 공식 블로그). 실제 깃허브 이슈를 자동으로 해결하는 테스트에서 10개 중 8개를 혼자 처리한다는 뜻이다. OSWorld 66.3%는 컴퓨터를 직접 마우스 클릭하고 키보드로 조작하는 작업에서도 1위를 차지했음을 보여준다.
세 번째, 가격 혁신이다. Opus 4가 입력 75/1M 토큰이었던 것에 비해, Opus 4.5는 입력 25/1M 토큰으로 정확히 3배 저렴해졌다. 여기에 프롬프트 캐싱을 쓰면 캐시 히트 시 입력 비용이 $0.50으로 추가 90% 절감된다.
네 번째, effort level 제어 기능이다. low/medium/high 세 단계로 추론 깊이를 조절할 수 있어, 간단한 질문에는 빠르게, 어려운 문제에는 깊이 사고하도록 설정할 수 있다. 이 기능은 비용 최적화에 실질적으로 도움이 된다.
Reddit과 Hacker News 사용자들의 체감 평가를 보면, "Claude가 에이전틱 코딩에서는 확실히 낫고, Gemini는 멀티모달에서 더 낫다"는 의견이 주류다. 특히 복잡한 멀티파일 리팩토링 작업에서 Opus 4.5의 직관적 이해력이 크게 개선됐다는 피드백이 많다.

할 수 있는 것
코딩 작업에서 Opus 4.5는 실질적으로 "시니어 개발자급 페어 프로그래머" 역할을 한다. SWE-bench Verified에서 검증된 것처럼 실제 오픈소스 프로젝트의 버그를 파악하고 수정 코드를 작성하는 능력이 출중하다. Terminal-Bench 59.3%는 터미널 환경에서의 시스템 관리, 디버깅, 배포 작업도 경쟁 모델(GPT-5.1: 47.6%, Gemini 3 Pro: 54.2%) 대비 앞선다는 것을 보여준다 (출처: automatio.ai).
컴퓨터 사용 에이전트로서도 강력하다. OSWorld 66.3%는 브라우저에서 정보를 검색하고, 스프레드시트를 조작하고, 파일을 관리하는 등 실제 컴퓨터 작업의 3분의 2를 성공적으로 수행한다는 의미다. Anthropic 공식 발표에 따르면 "슬라이드 작업, 스프레드시트 정리 같은 일상적 오피스 업무에서도 의미 있는 개선"을 보인다고 한다.
연구 분석과 딥 리서치에서도 실사용자들이 높이 평가한다. 200K 컨텍스트 윈도우를 활용해 긴 논문이나 법률 문서를 한 번에 읽고 요약하거나 비교 분석하는 데 적합하다. GPQA 87%는 대학원 수준 과학 문제에서의 추론력을 의미하며, MMLU 90.8%로 종합 지식 평가에서도 최상위를 기록했다 (출처: 공식 블로그).
다만 실사용자들은 한계도 지적한다. "5건 중 1건 정도는 여전히 사람이 개입해야 한다"는 평가가 있고, Pro 플랜에서 무거운 코딩 작업을 2-3시간 하면 레이트 리밋에 걸린다는 불만도 있다. 매일 코딩용으로 쓰려면 Max 5x ($100/월) 이상이 필요하다는 의견이 많다.
성능
| 벤치마크 | Claude Opus 4.5 | 비고 |
|---|---|---|
| GPQA | 87.0% | 대학원 수준 과학 QA (출처: 공식 블로그) |
| MMLU-PRO | 89.5% | 전문 영역 종합 평가 (출처: 공식 블로그) |
| MATH Lvl 5 | 95.2% | 올림피아드급 수학 (출처: 공식 블로그) |
| IFEval | 92.0% | 지시 따르기 (출처: 공식 블로그) |
| HumanEval | 92.0% | 코드 생성 (출처: 공식 블로그) |
| SWE-bench Verified | 80.9% | 실제 SW 버그 수정 (출처: 공식 블로그) |
| OSWorld | 66.3% | 컴퓨터 사용 에이전트 (출처: 공식 블로그) |
| Terminal-Bench | 59.3% | 터미널 작업 (출처: automatio.ai) |
| HLE | 20.0% | 최고 난이도 추론 (출처: vellum.ai) |
| AIME 2025 | 87.0% | 수학 경시대회 (출처: vellum.ai) |
| MMMU | 80.7% | 멀티모달 이해 (출처: vellum.ai) |
| ARC-AGI-2 | 37.6% | 추상 추론 (출처: datacamp.com) |
| MMLU | 90.8% | 종합 지식 (출처: 공식 블로그) |
| Arena Elo | 1490 | 블라인드 사용자 평가 (출처: 공식 블로그) |
경쟁 모델과 비교하면 포지션이 명확하다. 코딩과 에이전틱 작업에서는 Opus 4.5가 명확한 1위이고, 수학적 추론에서는 GPT-5.2가 AIME 2025에서 100%를 달성하며 더 앞선다. 멀티모달과 초대용량 컨텍스트에서는 1M 토큰 윈도우를 가진 Gemini 3 Pro가 강점을 보인다.
실사용자들의 체감 비교를 보면, "벤치마크에서 몇 퍼센트 차이가 나든 실제로 코딩 작업을 시키면 Claude가 더 직관적으로 문제를 파악한다"는 의견이 많다. 반면 "수학 문제를 집중적으로 풀려면 GPT 쪽이 더 안정적"이라는 평가도 존재한다. Sonar의 코드 품질 분석에 따르면, Opus 4.5는 코드 일관성과 구조적 완성도에서 경쟁 모델을 앞서지만, 가끔 지나치게 신중해서 응답이 느려지는 경향이 있다.
사용 방법
일반 사용자는 claude.ai 웹사이트나 모바일 앱에서 Claude Pro (100/월, $200/월) 구독으로 Opus 4.5를 사용할 수 있다. Pro 플랜에서도 Opus 4.5에 접근 가능하지만, 무거운 작업을 장시간 하면 레이트 리밋이 걸린다.
개발자는 Anthropic API를 통해 모델 ID claude-opus-4-5-20251101로 접근한다. Python SDK 예시:
python
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello"}]
)
Extended Thinking 모드를 활성화하면 복잡한 추론 작업에서 더 정확한 결과를 얻을 수 있다. effort level을 low/medium/high로 조절해 토큰 비용과 품질 사이의 균형을 맞출 수 있다. Amazon Bedrock, Google Cloud Vertex AI, Azure AI에서도 사용 가능하며, Snowflake Cortex AI에서도 접근할 수 있다.
가격
구독 기준으로는 Claude Pro 100/월 5x 또는 $200/월 20x)이 현실적이다.
API 가격은 입력 25/1M 토큰이다. 전작 Opus 4의 입력 75 대비 정확히 3배 저렴해졌다. 프롬프트 캐싱을 활용하면 캐시 히트 시 입력이 2.50, 출력 $12.50까지 낮출 수 있다.
경쟁 모델과 비교하면, GPT-5.1은 입력 10이고 Gemini 3 Pro는 입력 10으로, 단순 토큰 단가로는 Opus 4.5가 경쟁사 대비 비싼 편이다. 하지만 Opus 4.5의 토큰 효율성(같은 작업에 더 적은 토큰 사용)을 감안하면 실제 비용 차이는 상당히 좁혀진다. 실사용자들 사이에서는 "토큰당은 비싸지만 작업당 비용은 비슷하거나 더 싸다"는 평가가 있다.
한국어 토큰 효율에 대해서는 구체적인 공식 데이터가 미공개 상태다. 다만 Anthropic 공식 문서에 따르면 한국어는 "high-resource language"로 분류되어 영어 대비 80% 이상의 성능을 유지한다고 한다 (출처: platform.claude.com 다국어 지원 문서).

기술 사양
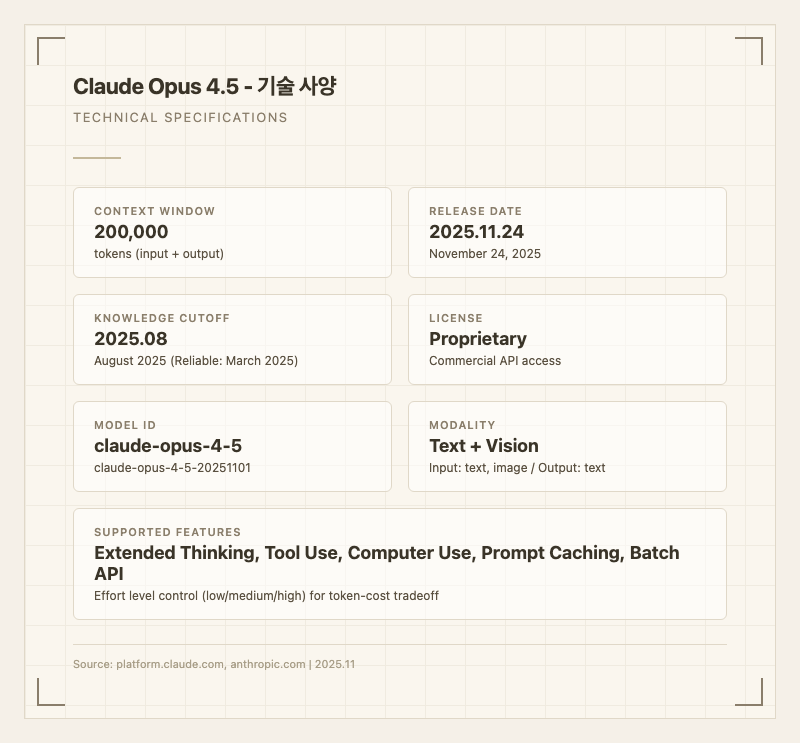
- 컨텍스트 윈도우: 200,000 토큰
- 학습 데이터 기준일: 2025년 8월 (신뢰 기준: 2025년 3월)
- 라이선스: Proprietary (상용 API 접근)
- 모델 ID: claude-opus-4-5-20251101
- 입출력: 텍스트 + 이미지 입력, 텍스트 출력
- 지원 기능: Extended Thinking, Tool Use, Computer Use, Prompt Caching, Batch API, Effort Level Control
- 파라미터 수: 비공개
- 아키텍처: 비공개 (Transformer 기반 추정)
- 출시일: 2025년 11월 24일
- 제공 플랫폼: Anthropic API, Amazon Bedrock, Google Cloud Vertex AI, Azure AI, Snowflake Cortex AI
참고 자료



스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2025년 11월 25일
학습 마감일
2025년 8월 1일
가성비 지수
0.3
API 가격 (혼합)
입력 $5.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$5.00 / 1M 토큰
출력 (Completion)
$25.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
92.0
복잡한 지시사항 이해 및 수행
일반지식
89.5
다양한 분야 지식 및 이해
멀티모달
80.7
이미지, 비디오 등 멀티모달 이해
코딩
77.4
코드 생성, 버그 수정, 소프트웨어 엔지니어링
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude Opus 4.5 | 90.7 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |