Claude Opus 4.1
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리200K 토큰
2025년 8월 6일Proprietary
Claude Opus 4.1이란
Anthropic이 2025년 8월 5일에 출시한 Claude Opus 4의 업그레이드 버전이다. 모델 ID는 claude-opus-4-1-20250805. 코딩, 에이전트 작업, 추론 성능에서 전작 대비 의미 있는 개선을 이뤄낸 프리미엄 모델로, 특히 멀티파일 코드 리팩토링과 장시간 자율 작업에서 강점을 보인다. 200K 토큰 컨텍스트 윈도우와 최대 64K 토큰의 확장 사고(Extended Thinking) 모드를 지원하며, 지식 기준일은 2025년 3월이다.
주요 특징
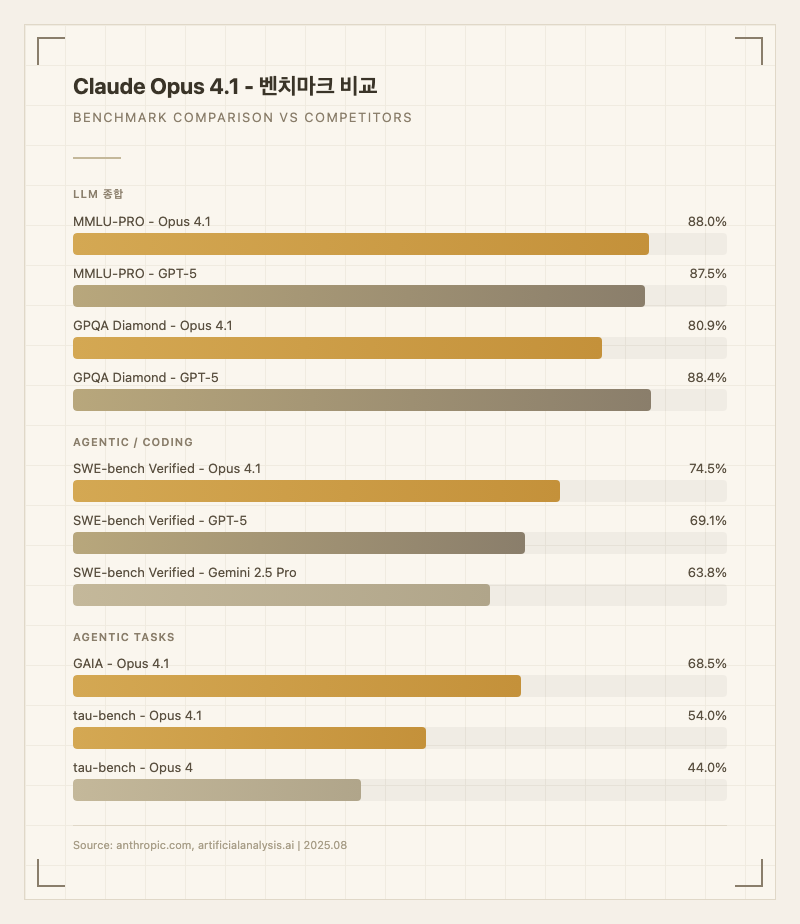
Opus 4.1의 가장 두드러진 변화는 코딩 정밀도다. SWE-bench Verified에서 74.5%를 기록하며 출시 당시 최고 점수를 달성했는데, 이는 실제 GitHub 저장소의 복잡한 버그 4개 중 3개를 자동으로 해결할 수 있는 수준이다 (출처: 공식 블로그). Opus 4의 72.5%에서 2%p 향상된 수치지만, 실사용자들은 벤치마크 수치 이상의 체감 차이를 보고한다. Reddit과 개발자 커뮤니티에서는 "멀티파일 작업에서 빠뜨리는 괄호가 줄었다", "변수 상태 추적이 확실히 나아졌다"는 피드백이 반복적으로 등장한다.
두 번째 핵심은 에이전트 성능이다. tau-bench에서 54%를 기록해 Opus 4의 44%에서 10%p나 뛰었고 (출처: 공식 블로그), GAIA 68.48%로 웹 검색, 파일 분석, 코드 실행을 결합한 복합 멀티스텝 작업에서도 안정적인 수행력을 보여준다. 장시간 연속 작업에서 문맥을 잃지 않는다는 점이 실사용자들에게 높은 평가를 받는다.
세 번째는 안전성 향상이다. 유해 거부율이 97.27%에서 98.76%로 올라갔고, 고위험 악용 시나리오에서의 협력률이 25% 감소했다 (출처: 시스템 카드). 코드 변경에 대해서도 보수적인 접근을 취해서 불필요한 리팩토링이나 의도치 않은 버그 도입이 줄었다는 평가다.
네 번째는 지시 따르기(instruction following) 능력이다. 복잡한 다단계 프롬프트를 더 정확하게 수행하며, 할루시네이션 비율도 Opus 4 대비 감소했다는 커뮤니티 보고가 다수 있다.

할 수 있는 것
실사용자들이 실제로 써보고 보고한 주요 유스케이스를 정리하면 다음과 같다.
코딩 및 소프트웨어 개발: 대규모 코드베이스에서 멀티파일 리팩토링, 버그 수정, 새 기능 구현까지 폭넓게 활용된다. 개발자 커뮤니티에서 73%가 코드 품질과 유지보수성 측면에서 Claude를 선호한다는 조사 결과가 있다. Python, JavaScript, Java 코더들이 특히 "구문 오류가 줄었고 더 큰 코드베이스에서의 기억력이 좋아졌다"고 평가한다. 다만 GPT-5가 빠른 프로토타이핑과 원샷 프롬프팅에서는 더 낫다는 의견도 있다.
연구 및 데이터 분석: 수백 페이지 분량의 논문이나 보고서를 200K 컨텍스트로 한 번에 처리할 수 있다. 세부 사항 추적과 에이전트 검색 능력이 Opus 4 대비 개선되어, 여러 문서에 걸친 정보를 교차 분석하는 작업에서 강점을 보인다.
자율 에이전트 워크플로: Claude Code와 연동해 장시간 코딩 세션을 자율적으로 수행할 수 있다. 수 시간에 걸친 연속 작업에서도 문맥 유지력이 좋다. OSWorld 44.4%로 실제 컴퓨터 인터랙션도 가능하지만 (출처: artificialanalysis.ai), 이 부분은 후속 모델인 Sonnet 4.5(61.4%)에 비해 약한 편이다.
할 수 없는 것 / 한계: 200K 컨텍스트는 Gemini 2.5 Pro의 1M이나 GPT-5의 400K에 비해 제한적이다. 거대한 코드베이스 전체를 한 번에 넣기에는 부족할 수 있다. 이미지/비디오 이해는 텍스트+이미지 입력만 지원하며, 오디오나 비디오 직접 처리는 불가하다. 또한 API 과부하로 인한 간헐적 속도 저하가 보고되기도 한다.
성능
벤치마크 점수
| 벤치마크 | 점수 | 카테고리 | 출처 |
|---|---|---|---|
| MMLU-PRO | 88.0% | LLM 종합 | 공식 블로그 |
| GPQA Diamond | 80.9% | LLM 종합 | 공식 블로그 |
| HumanEval | 95.7% | LLM 종합 | artificialanalysis.ai |
| SWE-bench Verified | 74.5% | Agentic | 공식 블로그 |
| GAIA | 68.48% | Agentic | 공식 블로그 |
| tau-bench | 54.0% | Agentic | 공식 블로그 |
| OSWorld | 44.4% | Agentic | artificialanalysis.ai |
| AIME 2025 | 78.0% | 수학 | lmcouncil.ai |
| MMMU | 77.1% | 멀티모달 | lmcouncil.ai |
경쟁 모델 비교
코딩 영역에서 Opus 4.1은 SWE-bench Verified 74.5%로 GPT-5(69.1%)와 Gemini 2.5 Pro(63.8%)를 앞선다. MMLU-PRO 88.0%는 GPT-5(87.5%)와 비슷한 수준. 반면 GPQA Diamond에서는 80.9%로 GPT-5(88.4%)와 Grok 4(88.0%)에 뒤진다. 즉, 코딩은 확실히 강하지만 과학 추론에서는 경쟁 모델에 밀리는 구도다.
실사용 체감으로는, 복잡한 코드베이스 이해와 새 기능 작성에서는 Claude가 여전히 선호되지만, 빠른 원샷 코딩이나 프로토타이핑에서는 GPT-5가 더 편하다는 의견이 많다. 멀티모달 작업이 필요하면 Gemini 2.5 Pro의 1M 컨텍스트가 대안이 될 수 있다.
한계와 단점: 출력 속도가 29.4 tokens/sec로 경쟁 모델 대비 느린 편이고, API 가격이 가장 비싸다. 토큰 비용 때문에 대량 처리 워크로드에는 적합하지 않다는 지적이 반복된다.
사용 방법
웹/앱 (일반 사용자)
claude.ai에서 Pro 구독($20/월)으로 Opus 4.1을 사용할 수 있다. 모델 선택기에서 Claude Opus 4.1을 고르면 된다. 다만 Pro 플랜에서는 사용량 제한(usage cap)이 있어 파워 유저에게는 불편할 수 있다.
API (개발자)
Anthropic API(api.anthropic.com), Amazon Bedrock, Google Cloud Vertex AI에서 사용 가능하다. API 호출 시 모델 ID로 claude-opus-4-1-20250805를 지정한다. Claude Code에서도 바로 사용할 수 있으며, 확장 사고 모드를 활성화하면 최대 64K 토큰까지 내부 추론에 할당할 수 있다.
공식 문서: https://platform.claude.com/docs
가격
구독 요금
- Claude Pro: $20/월 (Opus 4.1 포함, 사용량 제한 있음)
- Claude Max: 더 높은 사용량 한도 제공
API 가격 (1M 토큰당)
- 입력: $15.00
- 출력: $75.00
경쟁 모델 대비 가격이 상당히 높다. GPT-5는 입력 30, Gemini 2.5 Pro는 입력 10, 후속 모델인 Opus 4.6도 입력 25로 67% 인하되었다. 실사용자들 사이에서 "성능은 좋은데 가격이 문제"라는 반응이 지배적이며, 고볼륨 엔터프라이즈 배포에는 비용 부담이 크다는 평가다.
한국어 토큰 효율 데이터는 미공개이나, Claude는 한국어를 포함한 주요 동아시아 언어에서 영어 대비 80% 이상의 성능을 유지한다고 Anthropic이 밝히고 있다 (출처: 공식 다국어 지원 문서).

기술 사양
| 항목 | 사양 |
|---|---|
| 모델 ID | claude-opus-4-1-20250805 |
| 출시일 | 2025년 8월 5일 |
| 개발사 | Anthropic |
| 모델 유형 | 하이브리드 추론 LLM |
| 입력 | 텍스트 + 이미지 |
| 출력 | 텍스트 |
| 컨텍스트 윈도우 | 200,000 토큰 |
| 최대 출력 | 32,000 토큰 |
| 확장 사고 | 지원 (최대 64K 토큰) |
| 지식 기준일 | 2025년 3월 1일 |
| 라이선스 | Proprietary |
| 출력 속도 | 29.4 tokens/sec (Anthropic API) |
| TTFT | 1.66s (Anthropic API) |
| 유해 거부율 | 98.76% |

참고 자료




스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2025년 8월 6일
학습 마감일
2025년 3월 1일
가성비 지수
0.1
API 가격 (혼합)
입력 $15.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$15.00 / 1M 토큰
출력 (Completion)
$75.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
일반지식최강
88.0
다양한 분야 지식 및 이해
코딩
85.1
코드 생성, 버그 수정, 소프트웨어 엔지니어링
수학/추론
79.5
수학, 과학, 논리적 추론
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| AIME 2026 | 78.0 | % |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude Opus 4.1 | 85.9 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |