Claude Opus 4
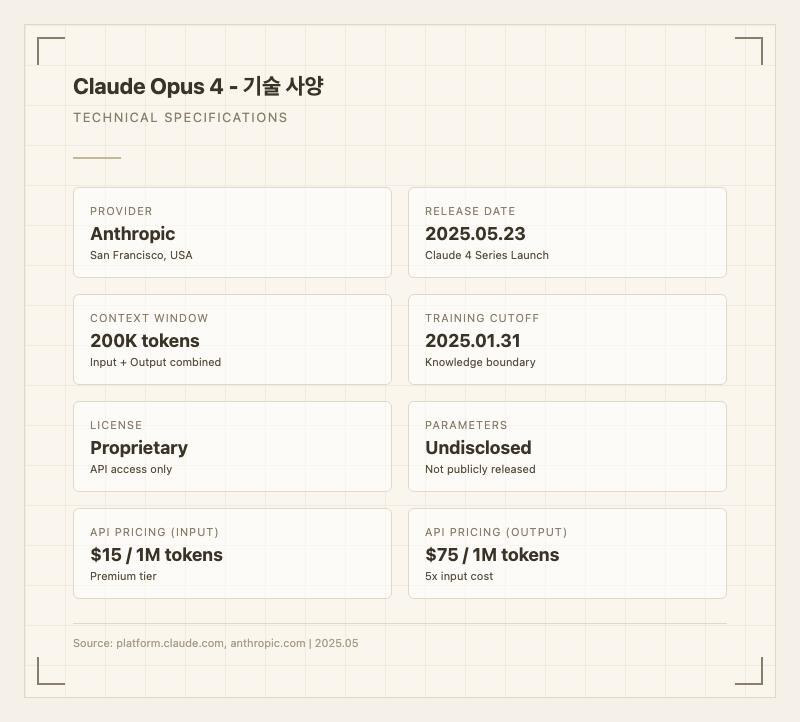
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리200K 토큰
2025년 5월 23일Proprietary
한줄 소개
Claude Opus 4는 Anthropic이 2025년 5월 23일 출시한 Claude 4 시리즈의 플래그십 모델로, "인내심 있는 AI"라는 콘셉트 아래 장시간 자율 에이전트 작업에 특화된 대규모 언어 모델이다. 출시 당시 세계 최고의 코딩 모델로 벤치마킹되었으며, 복잡한 소프트웨어 엔지니어링과 에이전트 워크플로우에서 지속적인 성능을 발휘하도록 설계되었다.
주요 특징
Claude Opus 4의 가장 큰 차별점은 장시간 에이전트 작업에서의 일관성이다. 7시간 이상의 연속 코딩 세션에서도 품질 저하 없이 수천 단계의 작업을 자율적으로 수행할 수 있다. 이는 단순히 긴 대화를 유지하는 것이 아니라, 복잡한 소프트웨어 프로젝트를 처음부터 끝까지 자율적으로 완수하는 능력을 의미한다.
실사용자들이 체감하는 가장 큰 차이점은 지시 따르기(instruction following) 능력이다. 세부적인 포맷 요구사항, 특정 제약 조건, 미묘한 가이드라인이 주어졌을 때 Claude는 첫 번째 시도에서 모든 조건을 정확하게 따르는 경향이 있다. 경쟁 모델들이 간혹 제약 조건을 누락하거나 재해석하는 것과 대비된다.
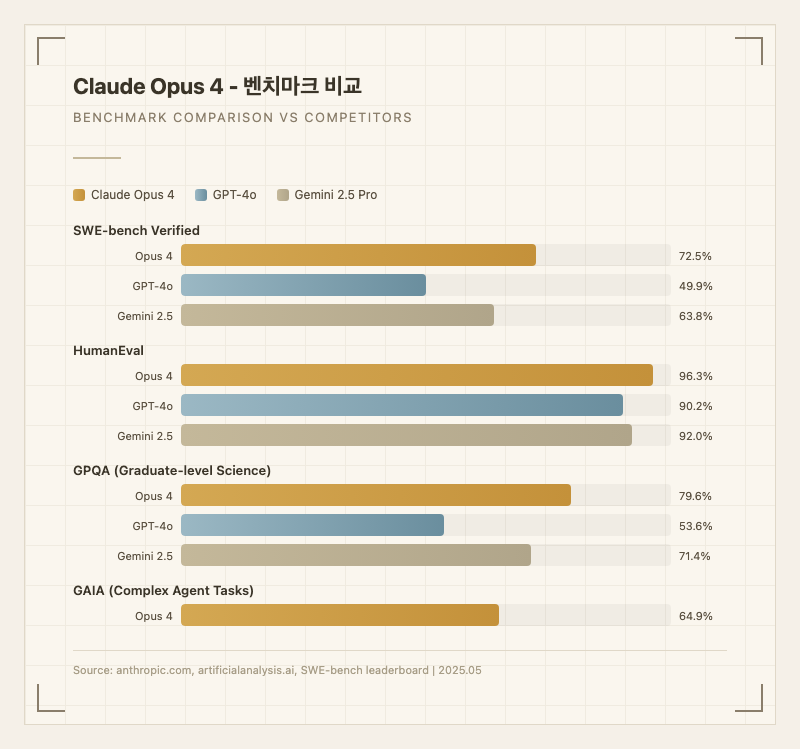
코딩 영역에서는 SWE-bench Verified 72.5%로 출시 당시 세계 최고 기록을 달성했으며, HumanEval 96.3%로 거의 모든 프로그래밍 문제를 정확하게 해결할 수 있는 수준이다. 다만 이후 출시된 Opus 4.5, 4.6에서 이 수치는 더욱 개선되었다.
또한 200K 토큰의 컨텍스트 윈도우를 지원하여 대규모 코드베이스나 긴 문서를 한 번에 처리할 수 있고, 100개 이상의 언어를 지원하며 한국어를 포함한 주요 언어에서 영어 대비 80% 이상의 성능을 유지한다.

할 수 있는 것
Claude Opus 4가 실제로 잘하는 작업들은 다음과 같다.
대규모 코드 마이그레이션과 리팩토링: 수백 개 파일에 걸친 코드베이스를 분석하고, 일관된 방식으로 마이그레이션을 수행한다. Reddit과 Hacker News 사용자들은 "에이전틱 코딩에서는 Claude가 Gemini보다 낫다"는 의견이 많다.
복잡한 버그 수정: SWE-bench 결과에서 알 수 있듯이 실제 소프트웨어 저장소의 복잡한 버그 4개 중 약 3개를 자동으로 수정할 수 있다. 멀티 파일 변경이 필요한 복잡한 태스크에서 특히 강점을 보인다.
멀티스텝 데이터 분석: 웹 검색과 파일 분석을 결합한 복합 에이전트 태스크에서 GAIA 64.85%를 기록하며, 여러 도구를 연결해서 쓰는 작업에서 뛰어나다(출처: GAIA leaderboard).
연구 및 분석 작업: GPQA 79.6%로 대학원 수준 과학 문제에서도 높은 정확도를 보이며, MMLU 87.4%의 폭넓은 일반 지식으로 다양한 분야의 리서치를 지원한다(출처: 공식 블로그).
한계: 멀티모달 능력에서는 Gemini 2.5 Pro에 뒤처진다. 네이티브 비디오 이해, 오디오 처리 등에서는 Google 모델이 더 강하다. 또한 속도 면에서 GPT-4o보다 응답 지연이 크며, 짧은 프롬프트에서 특히 차이가 난다.
성능Claude Opus 4의 벤치마크 성능은 다음과 같다.
| 벤치마크 | 점수 | 카테고리 | 출처 |
|---|---|---|---|
| HumanEval | 96.3% | LLM (코딩) | 공식 블로그 |
| MMLU | 87.4% | 일반 지식 | 공식 블로그 |
| MMLU-PRO | 86.0% | 전문 지식 | 공식 블로그 |
| GPQA | 79.6% | 대학원 과학 | 공식 블로그 |
| GSM8K | 96.2% | 수학 추론 | 공식 블로그 |
| SWE-bench Verified | 72.5% | 에이전틱 코딩 | SWE-bench leaderboard |
| GAIA | 64.85% | 복합 에이전트 | GAIA leaderboard |
| tau-bench | 44.0% | 도구 사용 | tau-bench leaderboard |
Artificial Analysis Intelligence Index에서 Claude Opus 4(비추론 모드)는 33점을 기록했다. 이후 출시된 Opus 4.5는 50점, Opus 4.6은 53점으로 크게 향상되었다(출처: artificialanalysis.ai).
실사용에서의 체감은 벤치마크 수치와 다소 다르다. Reddit과 Hacker News 사용자들은 Claude가 코딩과 정밀한 지시 따르기에서는 확실히 강하지만, 일반 대화에서의 속도는 GPT 계열이 더 빠르다고 평가한다. 특히 복잡한 멀티파일 코딩 작업에서 Claude의 일관성이 돋보이지만, 단순한 질의응답이나 빠른 반복 작업에서는 Sonnet 4나 GPT-4o가 더 효율적이라는 의견이 많다.
한계점으로는 Artificial Analysis Index 기준 비추론 모드에서 33점으로 GPT-4o와 비슷한 수준이며, 추론 모드 없이는 최신 모델들과 격차가 있다.
사용 방법
웹/앱 (일반 사용자): claude.ai에서 무료 계정으로 기본 사용이 가능하다. Claude Pro 구독($20/월)을 통해 Opus 4 모델에 대한 우선 접근과 더 많은 사용량을 확보할 수 있다. iOS와 Android 앱에서도 동일한 기능을 사용할 수 있다.
API (개발자): platform.claude.com에서 API 키를 발급받아 사용한다. 모델 ID는 claude-opus-4-20250514이며, Messages API를 통해 호출한다. Python SDK(anthropic 패키지)와 TypeScript SDK(@anthropic-ai/sdk)를 공식 지원한다.
pip install anthropic
공식 문서: https://platform.claude.com/docs
가격
구독 플랜: Claude Free(무료, 제한된 사용량), Claude Pro(30/사용자/월, 팀 관리 기능)이 있다.
API 가격: 입력 75/1M 토큰. 이는 현재 시점에서 상당히 비싼 가격대로, 이후 출시된 Opus 4.5와 4.6이 동일하거나 더 나은 성능을 25에 제공하면서 가격 대비 성능 면에서 레거시 모델이 되었다.
실사용자 가성비 평가를 보면, API 기준으로 Opus 4는 "비싸다"는 평이 지배적이다. 동일 작업을 Sonnet 4로 처리하면 훨씬 저렴하면서도 대부분의 경우 충분한 품질을 얻을 수 있기 때문이다. Opus 4는 정말 복잡한 에이전트 작업이나 최고 품질이 필요한 경우에만 가격을 정당화할 수 있다는 것이 커뮤니티 공통 의견이다.
한국어 토큰 효율 데이터는 Anthropic이 공식적으로 공개하지 않았다. 다만 Claude 모델 전반이 한국어를 포함한 주요 언어에서 영어 대비 80% 이상의 상대 성능을 유지한다는 것이 Anthropic의 공식 입장이다(출처: platform.claude.com 다국어 지원 문서).

기술 사양
| 항목 | 내용 |
|---|---|
| 제공사 | Anthropic |
| 출시일 | 2025년 5월 23일 |
| 모델 분류 | Large Language Model (LLM) |
| 파라미터 수 | 비공개 |
| 컨텍스트 윈도우 | 200,000 토큰 |
| 학습 데이터 기준일 | 2025년 1월 31일 |
| 라이선스 | Proprietary (API 접근만 가능) |
| API 가격 (입력) | $15 / 1M 토큰 |
| API 가격 (출력) | $75 / 1M 토큰 |
| 지원 언어 | 100개 이상 (한국어 포함) |
Anthropic은 모델 아키텍처나 파라미터 수를 공개하지 않고 있다. Claude 4 시리즈 이후 Opus 4.5(2025년 11월), Opus 4.6(2026년 2월)이 순차적으로 출시되면서 컨텍스트 윈도우가 1M 토큰으로 확장되고 가격은 67% 인하되었다.
참고 자료

스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2025년 5월 23일
학습 마감일
2025년 1월 31일
가성비 지수
0.1
API 가격 (혼합)
입력 $15.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$15.00 / 1M 토큰
출력 (Completion)
$75.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
92.0
복잡한 지시사항 이해 및 수행
일반지식
86.0
다양한 분야 지식 및 이해
코딩
84.4
코드 생성, 버그 수정, 소프트웨어 엔지니어링
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GAIA | 64.8 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude Opus 4 | 85.6 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |