Claude 3.7 Sonnet
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리200K 토큰
2025년 2월 25일Proprietary
Claude
3.7 Sonnet이란
Anthropic이 2025년 2월 24일 출시한 Claude 3.7 Sonnet은 시장 최초의 하이브리드 추론(hybrid reasoning) 모델이다. 하나의 모델 안에서 일반 모드(즉시 응답)와 확장 사고 모드(extended thinking, 단계적 추론)를 전환할 수 있다는 점이 가장 큰 차별점이다. 인간이 하나의 두뇌로 빠른 판단과 깊은 숙고를 모두 수행하듯, 추론 능력을 별도 모델이 아닌 프론티어 모델의 통합 기능으로 구현했다는 것이 Anthropic의 설계 철학이다.
주요 특징
Claude 3.7 Sonnet의 핵심 차별화 포인트는 다음과 같다.
-
하이브리드 추론: 일반 모드에서는 빠른 응답을, 확장 사고 모드에서는 사용자에게 사고 과정을 보여주며 단계별로 추론한다. 사고 토큰에 대한 추가 비용 없이 출력 토큰 가격($15/1M)이 동일하게 적용된다.
-
코딩 특화 성능: SWE-bench Verified 70.3%로 출시 당시 코딩 벤치마크 1위를 기록했다. Cognition 팀의 초기 테스트에서 "다른 모든 모델보다 코드 변경 계획 수립과 풀스택 업데이트에서 압도적"이라는 평가를 받았다 (출처: 공식 블로그).
-
수학 추론 최상위: MATH Lvl 5 96.2%로 출시 시점 전체 모델 중 최상위 수학 성능을 기록했다 (출처: 공식 블로그).
-
에이전트 역량: OSWorld 35.8%로 마우스/키보드를 사용한 컴퓨터 인터페이스 조작 능력을 최초로 입증했으며, GAIA 64.24%로 복합 멀티스텝 에이전트 태스크에서도 강점을 보인다.
-
200K 컨텍스트 윈도우: 텍스트와 이미지 입력을 모두 지원하며, 긴 문서 분석이나 대형 코드베이스 작업에 적합하다.
실사용자들의 체감 차이로는, 확장 사고 모드를 켜면 복잡한 수학이나 코딩 문제에서 체감할 수 있을 만큼 정확도가 올라간다는 반응이 많다. 한편으로 "일반 모드에서는 3.5 Sonnet과 큰 차이를 못 느끼겠다"는 의견도 있다 (출처: Reddit, HN 커뮤니티).

할 수 있는 것
Claude 3.7 Sonnet의 실제 사용 사례와 커뮤니티 평가를 정리한다.
코딩 및 소프트웨어 개발: 가장 많은 호평을 받는 분야다. 복잡한 UI와 백엔드 코드를 동시에 다루는 풀스택 작업에서 "며칠 걸릴 작업을 한 번에 해결했다"는 사용자 후기가 있다 (출처: Reddit). 레거시 코드베이스를 이해하고 기존 기능을 깨뜨리지 않으면서 개선안을 제시하는 능력도 우수하다고 평가된다.
수학 및 과학 추론: 확장 사고 모드에서 대학원 수준 수학 문제(MATH Lvl 5)를 96.2% 정확도로 풀며, GPQA Diamond에서도 확장 사고 시 84.8%까지 올라간다 (출처: 공식 시스템 카드). 경쟁 수학 문제(AIME)에서는 일반 모드 약 53%, 확장 사고 모드 80%로 격차가 크다.
문서 분석 및 글쓰기: 한국어 사용자들 사이에서 "프롬프트의 의도를 충실히 이해하려는 태도가 인상적"이라는 평가가 있다 (출처: 클리앙). 톤 조절, 스타일 준수, 장문 일관성에서 경쟁 모델보다 우수하다는 비교 리뷰가 많다.
에이전트 워크플로우: 멀티스텝 프로세스를 자율적으로 수행하는 에이전트 작업에서 강점을 보이지만, 한 가지 주의점이 있다. "요청한 것 이상으로 과도하게 코드를 수정하려 든다"는 불만이 있으며, 특히 Cursor 환경에서 "멈추지 않고 관련 없는 코드까지 변경하려 해서 사실상 사용 불가"라는 극단적 평가도 존재한다 (출처: Reddit r/cursor).
안 되는 것: 오디오/비디오 입력은 지원하지 않는다(텍스트+이미지만 가능). 컨텍스트 윈도우 200K는 대규모 모노레포 전체를 한 번에 처리하기에는 부족할 수 있다. 일반 모드에서 지시 따르기(instruction following) 정확도가 3.5 Sonnet보다 떨어진다는 보고가 반복적으로 나온다.
성능
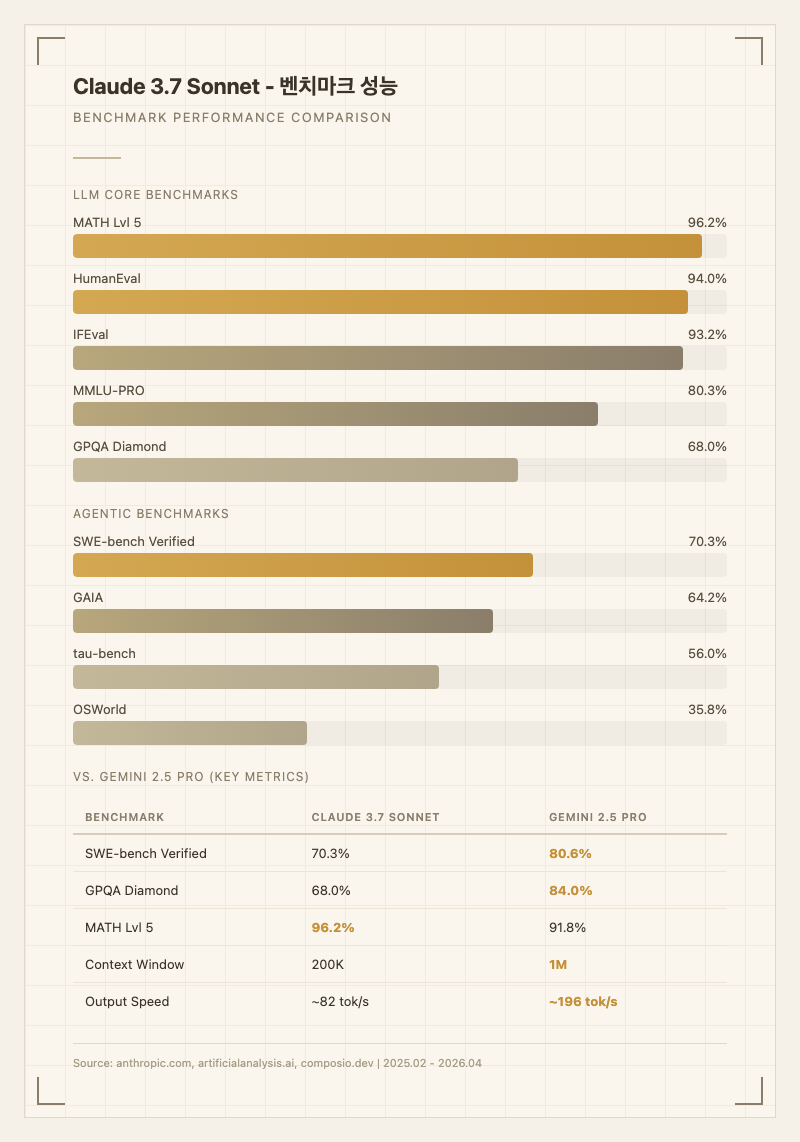
벤치마크 점수
| 벤치마크 | 점수 | 카테고리 | 출처 |
|---|---|---|---|
| MATH Lvl 5 | 96.2% | LLM | 공식 블로그 |
| HumanEval | 94.0% | LLM | 공식 블로그 |
| IFEval | 93.2% | LLM | 공식 블로그 |
| MMLU-PRO | 80.3% | LLM | 공식 블로그 |
| GPQA Diamond | 68.0% (표준) / 84.8% (확장 사고) | LLM | 공식 시스템 카드 |
| SWE-bench Verified | 70.3% | Agentic | 공식 블로그 |
| GAIA | 64.24% | Agentic | artificialanalysis.ai |
| tau-bench | 56.0% | Agentic | datacamp.com |
| OSWorld | 35.8% | Agentic | 공식 블로그 |
| MMMU | 75.0% | Capability | mmmu-benchmark |
| HLE | 34.0% | Capability | automatio.ai |
| Arena Elo | 1370 | 사용자 선호도 | lmsys.org |
경쟁 모델 대비 비교
Gemini 2.5 Pro와 비교하면 SWE-bench Verified(80.6% vs 70.3%), GPQA Diamond(84% vs 68%), 컨텍스트 윈도우(1M vs 200K), 출력 속도(~196 tok/s vs ~82 tok/s) 모두에서 뒤처진다. 반면 MATH Lvl 5(96.2% vs 91.8%)에서는 우위를 유지한다 (출처: composio.dev, artificialanalysis.ai).
벤치마크와 실체감의 괴리
벤치마크 수치만 보면 코딩 최강이지만, 실사용에서는 다른 양상이 나타난다. 개발자 커뮤니티의 합의는 "일상적인 코딩 작업에서는 3.5 Sonnet이 3.7보다 안정적"이라는 것이다. 3.7은 과도한 자율성(요청하지 않은 코드 변경)과 지시 따르기 불안정이 반복적으로 지적된다. 확장 사고 모드를 켜야 진가가 발휘되지만, 그만큼 응답 지연과 토큰 소비가 늘어나는 트레이드오프가 있다 (출처: Reddit, 16x Prompt, HN).
사용 방법
웹/앱 (일반 사용자)
claude.ai에서 무료로 사용할 수 있다(제한적). Claude Pro 구독($20/월)으로 더 많은 사용량과 확장 사고 모드에 접근할 수 있다. iOS/Android 앱에서도 동일하게 이용 가능하다.
API (개발자)
Anthropic API를 통해 모델 ID claude-3-7-sonnet-20250219로 접근한다. Amazon Bedrock, Google Vertex AI, Databricks에서도 동일 모델을 사용할 수 있다. 확장 사고 모드는 API에서 thinking 파라미터로 활성화하며, 사고 예산(budget_tokens)을 1,024~128,000 범위에서 설정할 수 있다.
공식 문서: https://platform.claude.com/docs
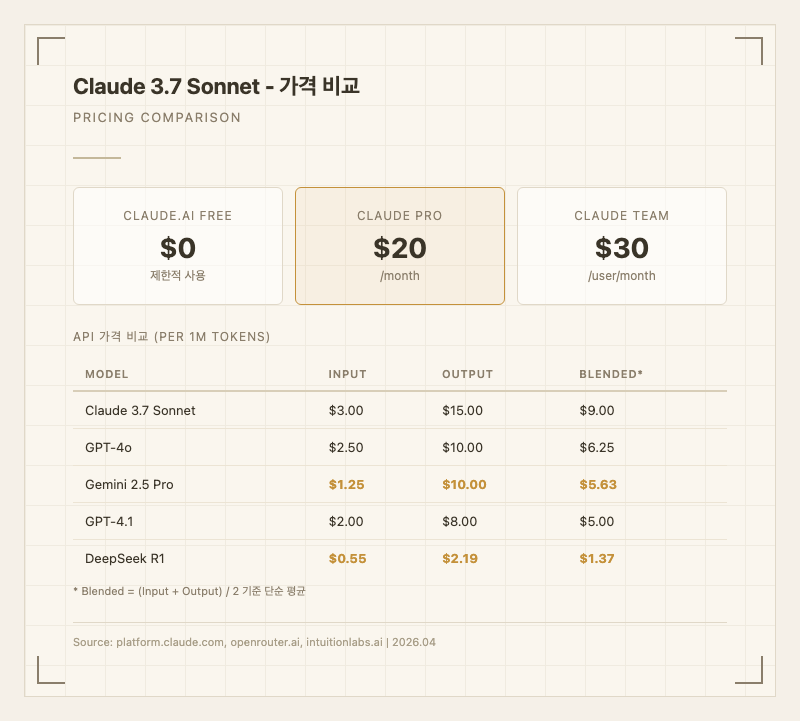
가격
구독 플랜
- Free: 제한된 메시지 수로 무료 사용
- Pro: $20/월 - 더 많은 사용량, 확장 사고 모드, 우선 접근
- Team: $30/사용자/월 - 팀 협업 기능 포함
API 가격
- 입력: $3.00 / 1M tokens
- 출력: $15.00 / 1M tokens (사고 토큰 포함)
- 캐시 입력: $0.30 / 1M tokens
경쟁 모델 대비 비싼 편이다. Gemini 2.5 Pro(입력 10.00)보다 약 1.6배, DeepSeek R1(입력 2.19)보다 약 6.5배 비싸다. 한국어 사용자들 사이에서도 "돈 내고 써도 아깝지 않다"는 평가와 "GPT-4o나 Gemini Flash 대비 가격 대비 성능이 떨어진다"는 의견이 공존한다 (출처: 클리앙, intuitionlabs.ai).
한국어 토큰 효율 데이터는 미공개다. Anthropic의 토크나이저 특성상 한국어는 영어 대비 약 2-3배 많은 토큰을 소비하는 것으로 알려져 있으나, Claude 3.7 Sonnet 고유의 한국어 토큰 효율 측정 데이터는 공개된 바 없다.
기술 사양
| 항목 | 사양 |
|---|---|
| 제공사 | Anthropic |
| 모델 ID | claude-3-7-sonnet-20250219 |
| 출시일 | 2025년 2월 24일 |
| 모델 유형 | LLM (하이브리드 추론) |
| 파라미터 수 | 미공개 |
| 컨텍스트 윈도우 | 200,000 tokens |
| 학습 데이터 기준일 | 2024년 10월 31일 |
| 라이선스 | Proprietary |
| 입력 모달리티 | 텍스트, 이미지 |
| 출력 모달리티 | 텍스트 |
| 출력 속도 | ~82 tok/s (일반 모드, 출처: artificialanalysis.ai) |
| 확장 사고 예산 | 1,024 - 128,000 tokens |

참고 자료


스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2025년 2월 25일
학습 마감일
2024년 10월 31일
가성비 지수
0.4
API 가격 (혼합)
입력 $3.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$3.00 / 1M 토큰
출력 (Completion)
$15.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
93.2
복잡한 지시사항 이해 및 수행
코딩
82.2
코드 생성, 버그 수정, 소프트웨어 엔지니어링
일반지식
80.3
다양한 분야 지식 및 이해
멀티모달
75.0
이미지, 비디오 등 멀티모달 이해
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude 3.7 Sonnet | 83.2 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |