Claude 3.7 Sonnet (thinking)
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리200K 토큰
2025년 2월 25일Proprietary
한줄 소개
Claude 3.7 Sonnet(Thinking)은 Anthropic이 2025년 2월에 출시한 최초의 하이브리드 추론 모델이다. 하나의 모델에서 즉각 응답과 심층 사고(extended thinking)를 전환할 수 있는 구조로, "빠르게 답할 것인가, 깊이 생각할 것인가"를 사용자가 직접 선택할 수 있다.
주요 특징
Claude 3.7 Sonnet(Thinking)의 핵심은 확장된 사고(extended thinking) 기능이다. 일반 모드에서는 기존 Claude처럼 즉각 응답하고, thinking 모드를 켜면 답변 전에 내부적으로 최대 128K 토큰까지 추론 과정을 거친다. 개발자는 thinking budget을 직접 설정해서 사고에 투입되는 토큰 양을 정밀하게 조절할 수 있다.
가장 눈에 띄는 특징은 사고 과정의 투명성이다. thinking 모드에서 모델이 어떤 과정으로 결론에 도달했는지 원시 형태 그대로 보여준다(Research Preview 단계). 이건 디버깅이나 결과 검증 측면에서 실질적인 가치가 있다.
코딩 분야에서는 SWE-bench Verified 70.3%(커스텀 scaffold 기준)을 기록하면서 이전 3.5 Sonnet의 49.0% 대비 큰 폭으로 향상되었다 (출처: 공식 블로그). 프론트엔드 개발과 풀스택 업데이트에서 특히 강점을 보인다.
실사용자 반응을 보면, Reddit의 한 개발자(Ehsan1238)는 "보통 며칠 걸리는 복잡한 코드 작업을 한 번에 끝냈다"고 평가했다. 반면 Cursor 서브레딧의 stxthrowaway123은 "무관한 코드를 발견하면 멋대로 수정하기 시작해서 오히려 엉망이 된다"고 불만을 표시하기도 했다. 지시를 충실히 따르는 면에서 3.5 Sonnet보다 후퇴했다는 의견이 커뮤니티에서 반복적으로 나온다.

할 수 있는 것
thinking 모드가 빛을 발하는 영역은 복잡한 수학/과학 추론이다. MATH Lvl 5에서 96.2점으로 수학 추론에서 거의 완벽에 가까운 성능을 보여준다 (출처: 공식 블로그). 대학원 수준 과학 문제(GPQA Diamond 84.8점)에서도 높은 정확도를 기록한다.
코딩에서는 에이전틱 워크플로에서 자율적으로 다단계 프로세스를 탐색하는 능력이 강점이다. TAU-bench에서 소매 관련 태스크 81.2%, 항공 관련 58.4%로 OpenAI o1(각각 73.5%, 54.2%)을 앞섰다 (출처: 공식 블로그). 문서 리뷰, 다단계 추론, 에이전트 기반 의사결정 흐름에서 경쟁 모델보다 우위를 점한다.
실제로 사용해본 개발자들의 체감 평가를 보면, 복잡한 UI와 백엔드 코드를 동시에 다루는 작업에서 강점이 있다. 다만 Reddit 사용자 vanderpyyy의 조언처럼 "가능한 한 적은 줄의 코드로 작성하라"를 커스텀 지시에 추가하면 과도한 복잡성 문제를 완화할 수 있다.
한국어 처리 측면에서는 이전 3.5 버전 대비 더 자연스럽고 맥락을 잘 이해하는 답변을 생성하며, 긴 문장에서도 일관성을 유지한다는 평가가 있다 (출처: wikidocs.net). 다만 한국어 전용 벤치마크 데이터는 미공개 상태다.
성능thinking 모드 기준 주요 벤치마크 성적은 다음과 같다.
| 벤치마크 | 점수 | 출처 |
|---|---|---|
| MATH Lvl 5 | 96.2 | 공식 블로그 |
| HumanEval | 94.0 | pricepertoken.com |
| IFEval | 93.2 | 공식 블로그 |
| GPQA Diamond | 84.8 | 공식 블로그 |
| MMLU-PRO | 82.7 | vals.ai |
| TAU-bench (Retail) | 81.2 | 공식 블로그 |
| MMMU | 75.0 | datacamp.com |
| SWE-bench Verified | 70.3 | 공식 블로그 (scaffold) |
경쟁 모델과 비교하면, Gemini 2.5 Pro가 AIME에서 30% 이상, GPQA에서도 Claude를 앞서는 영역이 있다 (출처: analyticsvidhya.com). 특히 Gemini 2.5 Pro는 1M 토큰 컨텍스트와 더 저렴한 가격이 장점이고, DeepSeek R1은 가격 대비 성능에서 압도적이다.
"벤치마크는 높은데 실제로는 어떤가"에 대해 커뮤니티 반응을 보면, 코딩 태스크에서 일부 개발자는 여전히 3.5 Sonnet을 선호한다. 개발자 @mayfer는 "코딩에서는 3.5 Sonnet이 3.7보다 낫다"고 평가했다. thinking 모드가 복잡한 문제에서는 확실히 강하지만, 단순한 일상 코딩에서는 오버킬이 될 수 있다는 것이다. 과도한 사고로 인한 속도 저하나 불필요한 코드 변경을 유발하는 경향이 단점으로 지적된다.

사용 방법
일반 사용자는 claude.ai에서 Claude Pro(30/사용자/월), Enterprise 플랜을 통해 thinking 모드를 사용할 수 있다. Free 플랜에서도 제한적으로 이용 가능하다.
개발자는 Anthropic API(platform.claude.com)에서 모델 ID claude-3-7-sonnet-20250219로 접근한다. thinking 모드는 API 요청 시 별도로 활성화해야 하며, thinking budget 파라미터로 사고에 할당할 최대 토큰 수를 지정한다. Amazon Bedrock과 Google Cloud Vertex AI에서도 동일하게 사용 가능하다.
다만 이 모델은 현재 retired 상태이며, Anthropic은 Claude Sonnet 4.6으로의 업그레이드를 권장하고 있다 (출처: platform.claude.com).
가격
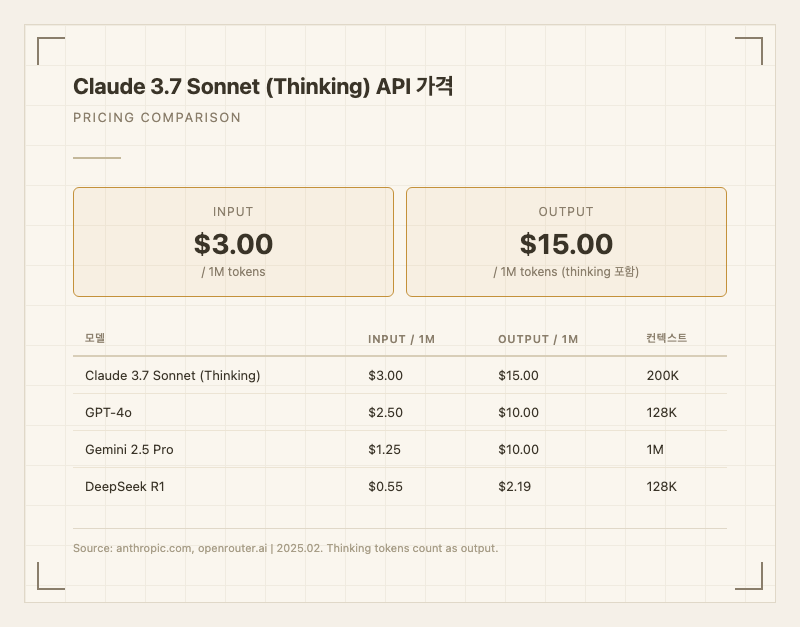
API 가격은 입력 15.00/1M 토큰이다. thinking 토큰은 출력 토큰으로 과금된다. 일반 모드와 thinking 모드의 토큰 단가는 동일하지만, thinking 모드에서는 내부 추론에 상당량의 토큰이 소비되므로 실질 비용은 크게 증가할 수 있다.
경쟁 모델과 비교하면 GPT-4o(입력 10.00)보다 20-50% 비싸고, Gemini 2.5 Pro(입력 10.00) 대비로는 2배 이상 비싸다. DeepSeek R1(입력 2.19)과의 가격 차이는 5-7배에 달한다.
구독 요금은 claude.ai 기준으로 Free(무료, 제한적), Pro(30/사용자/월), Enterprise(별도 문의)로 구성된다.
실사용자 가성비 평가를 보면, thinking 토큰이 출력으로 과금되는 구조 때문에 복잡한 문제일수록 비용이 급증한다는 의견이 많다. RAG 챗봇처럼 응답 시간이 중요한 구현에서는 thinking 모드의 지연 시간과 토큰 소모가 현실적인 제약이 된다.
한국어 토큰 효율 데이터는 미공개 상태다. Claude 시리즈가 사용하는 토크나이저의 한국어 효율에 대한 공식 수치는 Anthropic에서 발표한 바 없다.
기술 사양
| 항목 | 사양 |
|---|---|
| 개발사 | Anthropic |
| 모델 ID | claude-3-7-sonnet-20250219 |
| 출시일 | 2025년 2월 24일 |
| 모델 유형 | 하이브리드 추론 LLM |
| 파라미터 수 | 미공개 |
| 컨텍스트 윈도우 | 200,000 토큰 |
| 최대 출력 | 128,000 토큰 (Thinking 모드 beta) |
| 학습 데이터 기준일 | 2024년 10월 |
| 라이선스 | Proprietary |
| 입력 모달리티 | 텍스트, 이미지 |
| 출력 모달리티 | 텍스트 |
| 제공 플랫폼 | Anthropic API, Amazon Bedrock, Google Vertex AI |

참고 자료


스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2025년 2월 25일
학습 마감일
2024년 10월 31일
가성비 지수
0.5
API 가격 (혼합)
입력 $3.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$3.00 / 1M 토큰
출력 (Completion)
$15.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
93.2
복잡한 지시사항 이해 및 수행
수학/추론
90.5
수학, 과학, 논리적 추론
일반지식
82.7
다양한 분야 지식 및 이해
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| GPQA | 84.8 |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude 3.7 Sonnet (thinking) | 88.9 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |