Claude 3.5 Sonnet
AnthropicLMM시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)200K 토큰
2024년 10월 22일Proprietary
한줄 소개
Claude 3.5 Sonnet은 Anthropic이 2024년 6월에 처음 출시하고 같은 해 10월에 대폭 업그레이드한 중간급 LLM이다. '가격 대비 성능의 새로운 기준'이라는 평가를 받으며, 당시 최상위 모델이던 Claude 3 Opus를 1/5 가격으로 성능까지 뛰어넘은 전환점이 된 모델이다.
주요 특징
Claude 3.5 Sonnet을 다른 모델과 구분짓는 핵심 포인트는 다섯 가지다.
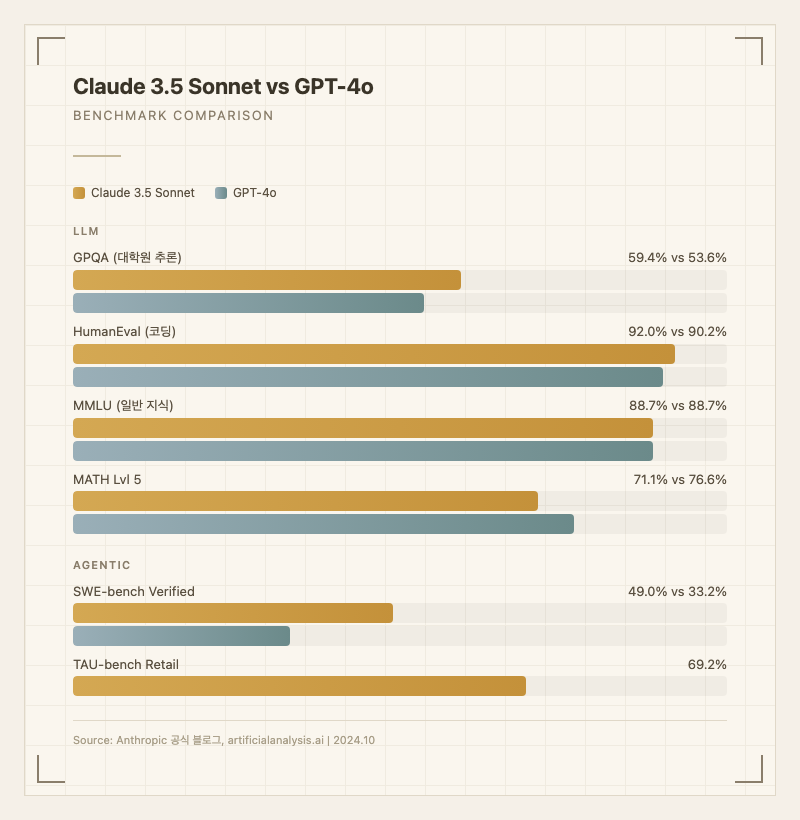
첫째, 코딩 능력이 출시 당시 전체 모델 중 최고였다. HumanEval 92%로 GPT-4o(90.2%)를 앞질렀고, SWE-bench Verified 49%로 실제 GitHub 이슈의 절반 가까이를 자동으로 해결했다 (출처: Anthropic 공식 블로그). 실사용자들 사이에서 "코딩은 Claude"라는 평가가 굳어지기 시작한 것이 이 모델부터다. Reddit에서 한 개발자는 "Claude 3.5 Sonnet으로 넘어간 뒤 GPT-4o로 돌아갈 이유가 없어졌다"고 말할 정도였다.
둘째, 컴퓨터 조작(Computer Use) 기능을 최초로 도입했다. 2024년 10월 업그레이드에서 화면을 보고 마우스를 움직이고 키보드를 입력하는 기능을 퍼블릭 베타로 제공한 최초의 프런티어 AI 모델이다 (출처: Anthropic 공식 발표).
셋째, 시각 데이터 처리가 뛰어나다. 차트, 그래프, 불완전한 이미지에서도 텍스트를 정확히 추출하며, 텍스트만으로는 얻기 어려운 시각적 인사이트까지 도출한다. 한국 사용자 후기에서도 "이미지 분석 능력이 체감될 정도로 정확하다"는 평가가 많았다.
넷째, 200K 토큰의 넓은 컨텍스트 윈도우로 수백 페이지의 문서나 대규모 코드베이스를 분할 없이 한 번에 처리한다. 긴 계약서 분석이나 대규모 코드 리뷰 같은 실무에서 특히 유용하다.
다섯째, Constitutional AI 기반의 안전한 출력으로 기업 환경에서 특히 널리 채택되었다. 명시적인 유해 콘텐츠 거부뿐 아니라, 응답 전반의 톤과 정확성에서 안정감이 있다는 것이 기업 사용자들의 공통 평가다.

할 수 있는 것
Claude 3.5 Sonnet의 실제 유스케이스는 상당히 넓다.
코딩 분야에서는 단순 코드 생성을 넘어서 실제 버그 수정, 리팩토링, 테스트 작성까지 가능하다. SWE-bench Verified 49%라는 수치가 보여주듯, 실제 오픈소스 프로젝트의 이슈를 읽고 수정 PR을 만드는 수준이다. 실사용자들은 "3분 만에 HTML5 게임을 만들었다", "복잡한 멀티파일 리팩토링을 한 번에 해냈다"고 보고했다. 다만 "가끔 환각으로 존재하지 않는 API를 호출한다"는 단점도 꾸준히 지적된다.
데이터 분석에서는 비정형 데이터를 탐색하면서 여러 도구를 조합해 인사이트를 도출하는 데 강점을 보인다. CSV 파일을 읽고 시각화 코드를 작성하고 해석까지 한 번에 처리하는 워크플로우가 가능하다.
문서 처리에서는 200K 컨텍스트를 활용해 긴 논문, 계약서, 기술 문서를 통째로 넣고 요약하거나 특정 조항을 찾아내는 작업이 가능하다. 실사용자들은 "200페이지 PDF를 넣고 질문하면 정확한 위치를 찾아준다"고 평가했다.
Computer Use 기능으로는 웹 브라우징, 폼 작성, 반복 작업 자동화 등 에이전틱 워크플로우를 구축할 수 있다. 다만 이 기능은 베타 단계여서 속도가 느리고 실수도 있다는 것이 초기 사용자들의 공통 피드백이다.
한국어 콘텐츠 작성에서는 "이질감 없는 자연스러운 한국어"를 구사한다는 것이 한국 사용자들의 일관된 평가다. 블로그 글, 마케팅 카피, 번역 작업에서 GPT-4o보다 한국어 품질이 좋다고 느끼는 사용자가 많았다.
반면 "안 되는 것"도 명확하다. 실시간 정보 접근이 불가능하고(학습 기준일 2024년 4월), 긴 출력이 필요한 작업에서는 8,192 토큰 제한에 걸린다. 수학적 추론에서는 GPT-4o(MATH 76.6%)에 비해 71.1%로 다소 뒤처진다 (출처: 공식 벤치마크).
성능
Claude 3.5 Sonnet의 벤치마크 성적은 출시 당시 중간급 모델로서는 파격적이었다.
| 벤치마크 | Claude 3.5 Sonnet | GPT-4o | 비고 |
|---|---|---|---|
| GPQA | 59.4% | 53.6% | 대학원 수준 추론 (출처: Anthropic 공식) |
| MMLU | 88.7% | 88.7% | 일반 지식 동률 (출처: Anthropic 공식) |
| MMLU-PRO | 77.2% | - | 전문 영역 (출처: Anthropic 공식) |
| HumanEval | 92.0% | 90.2% | 코딩 (출처: Anthropic 공식) |
| MATH Lvl 5 | 71.1% | 76.6% | 수학 - GPT-4o 우위 (출처: Anthropic 공식) |
| IFEval | 90.2% | - | 지시 따르기 (출처: Anthropic 공식) |
| SWE-bench Verified | 49.0% | 33.2% | 실제 코드 수정 (출처: Anthropic 공식) |
| TAU-bench Retail | 69.2% | - | 도구 사용 (출처: Anthropic 공식) |
| OSWorld | 22.0% | - | 컴퓨터 조작 (출처: Anthropic 공식) |
| BBH | 93.1% | - | 복합 추론 (출처: Anthropic 공식) |
| GSM8K | 96.4% | - | 초등 수학 (출처: Anthropic 공식) |
벤치마크와 실사용 체감의 괴리도 있다. 수학 벤치마크에서는 GPT-4o에 뒤지지만, 코딩과 에이전틱 작업에서는 확실히 앞선다는 것이 대다수 사용자의 체감이다. "벤치마크 점수로는 비슷해 보이는데, 실제로 코드를 짜보면 Claude가 맥락을 훨씬 잘 파악한다"는 의견이 Reddit에서 반복적으로 나왔다.
속도 면에서는 GPT-4o보다 24% 느리다. 평균 지연 시간 9.3초(GPT-4o는 7.5초), 첫 토큰까지 걸리는 시간도 1.2초(GPT-4o는 0.56초)로 체감 차이가 있다 (출처: artificialanalysis.ai).
한계점으로는 Arena Elo 1352로 여전히 높은 수준이지만, 2025년 이후 출시된 Claude 3.7 Sonnet, Claude Sonnet 4.5, GPT-5 등 후속 모델에 비하면 전반적 성능 격차가 벌어졌다. 현재 시점에서는 레거시 모델에 가까운 위치다.
사용 방법
일반 사용자는 claude.ai에서 무료로 Claude 3.5 Sonnet을 사용할 수 있다. 별도 설치 없이 웹 브라우저에서 바로 대화를 시작하면 된다. Claude iOS 앱에서도 동일하게 이용 가능하다. Pro($20/월) 또는 Team 플랜에 가입하면 사용량 제한이 대폭 완화된다.
개발자는 Anthropic API를 통해 직접 연동할 수 있다. API 키를 발급받은 후 HTTP 요청으로 호출하면 되며, Python SDK(@anthropic-ai/sdk)도 제공된다. 모델 ID는 claude-3-5-sonnet-20241022이다. 또한 Amazon Bedrock과 Google Cloud Vertex AI를 통해서도 접근 가능해, 기존 클라우드 인프라에 통합하기 쉽다.
Computer Use 기능은 API에서만 제공되며, 별도의 베타 엔드포인트를 통해 사용한다. 공식 문서는 https://docs.anthropic.com 에서 확인할 수 있다.
가격
Claude 3.5 Sonnet의 API 가격은 입력 토큰 100만 개당 15이다 (출처: Anthropic 공식 가격표). 이 가격은 Claude 3 Sonnet과 동일하면서 성능은 Claude 3 Opus를 뛰어넘어, "같은 값에 훨씬 좋은 모델"이라는 평가를 받았다.
Claude Pro 구독은 $20/월로, claude.ai에서 높은 사용량 한도와 우선 접근을 제공한다. 무료 티어에서도 사용 가능하지만 시간당 메시지 수가 제한된다.
경쟁 모델과 비교하면, GPT-4o(입력 10.00)보다 출력 비용이 50% 높다. 하지만 Claude 3 Opus(입력 75)의 1/5 비용이며, 실제 성능은 Opus 이상이라 가성비 측면에서는 우수하다.
실사용자들의 가성비 평가는 대체로 긍정적이다. "GPT-4o보다 약간 비싸지만 코딩 품질이 확실히 좋아서 충분히 값어치한다"는 의견이 지배적이다. 다만 대량 사용 시에는 출력 토큰 $15의 부담이 커지므로, 비용에 민감한 프로젝트에서는 GPT-4o나 Gemini 1.5 Pro가 더 경제적일 수 있다.
한국어 토큰 효율 데이터는 Anthropic에서 공식적으로 공개하지 않았다. 다만 Claude 모델은 영어 대비 80% 이상의 다국어 성능을 유지하며, 한국어를 포함한 주요 언어에서 강력한 처리 능력을 보인다 (출처: Anthropic 다국어 문서).

기술 사양
| 항목 | 사양 |
|---|---|
| Provider | Anthropic |
| 출시일 | 2024-06-20 (초기) / 2024-10-22 (업그레이드) |
| 모델 분류 | LLM (멀티모달 입력: 텍스트 + 이미지) |
| 컨텍스트 윈도우 | 200,000 토큰 |
| 최대 출력 | 8,192 토큰 |
| 학습 데이터 기준일 | 2024-04-01 |
| 라이선스 | Proprietary (상용) |
| 파라미터 수 | 비공개 |
| 아키텍처 | Transformer 기반 (상세 비공개) |
| 안전 장치 | Constitutional AI (RLHF + CAI) |
| API 접근 | Anthropic API, AWS Bedrock, GCP Vertex AI |
| Computer Use | Public Beta (2024.10~) |

참고 자료


스펙
컨텍스트 윈도우
200K 토큰
라이선스
Proprietary
출시일
2024년 10월 22일
학습 마감일
2024년 4월 1일
가성비 지수
0.2
API 가격 (혼합)
입력 $6.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$6.00 / 1M 토큰
출력 (Completion)
$30.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
90.2
복잡한 지시사항 이해 및 수행
일반지식
77.2
다양한 분야 지식 및 이해
코딩
70.5
코드 생성, 버그 수정, 소프트웨어 엔지니어링
Provider
Anthropic
분류
시각-언어 (Vision-Language)오디오-언어 (Audio-Language)통합 모달리티 (Any-to-Any)Multimodal TransformerLMM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
| Arena Elo |
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude 3.5 Sonnet | 73.1 |
| Nova Pro 1.0 | 68.4 |
| Gemma 4 | 86.2 |
| Claude 3 Haiku | 46.5 |
| Nova Premier 1.0 | 73.2 |