Claude Sonnet 4.5
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리1.0M 토큰
2025년 9월 30일Proprietary
Claude Sonnet 4.5란?
Claude Sonnet 4.5는 Anthropic이 2025년 9월 29일에 출시한 차세대 중간급(Sonnet 티어) 모델이다. Claude 4 패밀리의 최신 Sonnet으로, 코딩과 에이전트 워크플로우에 특화되어 있다. API 모델 ID는 claude-sonnet-4-5이며, claude.ai 웹/앱, Amazon Bedrock, Google Cloud Vertex AI, Azure에서 모두 사용 가능하다.
주요 특징
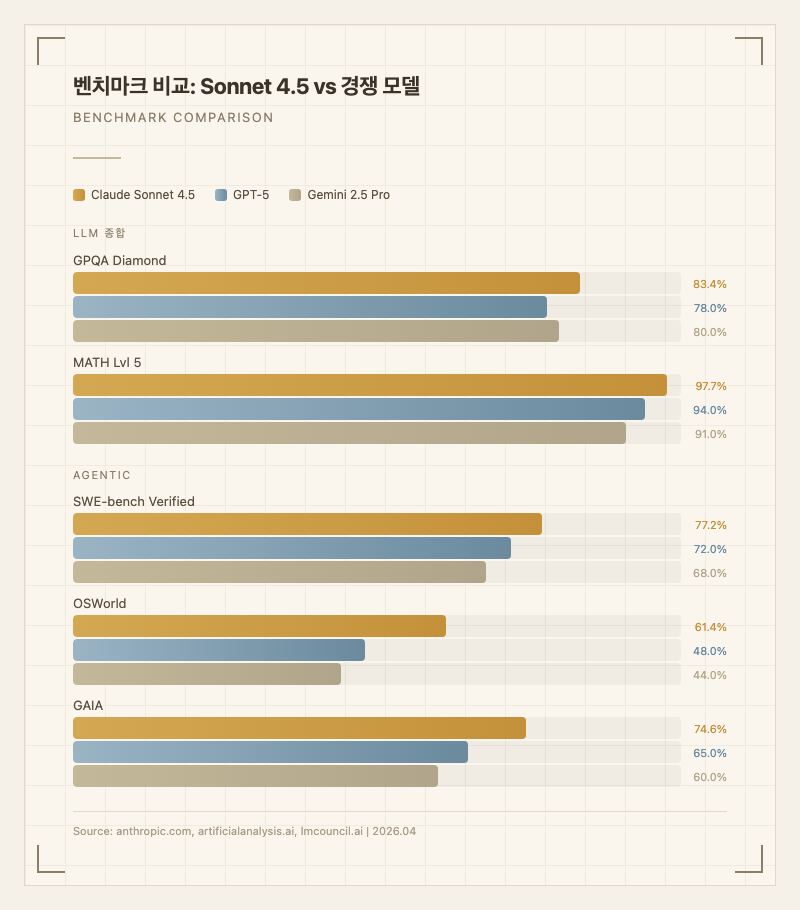
코딩 최강자 포지션 - SWE-bench Verified 77.2%(병렬 컴퓨팅 시 82.0%)로 실제 GitHub 저장소의 복잡한 버그를 자율적으로 해결한다 (출처: 공식 블로그). 출시 당시 GPT-5, Gemini 2.5 Pro를 포함한 모든 모델 중 가장 높은 코딩 벤치마크 점수를 기록했다.
30시간 넘는 장기 에이전트 작업 - 코딩 태스크를 30시간 이상 연속으로 수행하면서 맥락을 잃지 않는다. 수천 줄의 코드와 여러 파일에 걸친 작업을 자율적으로 처리한다는 점이 실사용자들에게 가장 큰 차별점으로 꼽힌다.
하이브리드 추론(Extended Thinking) - 일반 모드와 확장 사고 모드를 전환할 수 있어, 간단한 질문에는 빠르게, 복잡한 추론이 필요한 문제에는 깊이 있게 대응한다.
1M 토큰 컨텍스트 윈도우 - 100만 토큰의 초대형 컨텍스트로 대규모 코드베이스 전체를 한 번에 분석하거나, 수백 페이지 분량의 문서를 처리할 수 있다. 최대 출력은 64,000 토큰이다.
컴퓨터 사용 능력 - OSWorld 61.4%로 컴퓨터 인터페이스를 자율적으로 조작하는 능력이 Sonnet 4(42.2%) 대비 19.2%p 향상되었다 (출처: 공식 블로그).
실사용자 반응을 보면, 출시 48시간 만에 "두 개 쓰던 AI 채팅을 하나로 통합했다"는 평가가 나올 정도로 코딩 워크플로우에서의 체감 차이가 크다. 다만 코드 리뷰 시 34%의 코멘트에서 "might", "could", "possibly" 같은 헤징 표현을 사용해서, 확신 있는 지적보다 조심스러운 제안이 많다는 점은 불만 포인트로 지적된다 (출처: coderabbit.ai).
할 수 있는 것
실사용자들이 실제로 해본 작업과 평가를 중심으로 정리한다.
소프트웨어 개발 - 대규모 코드베이스에서 멀티파일 리팩토링, 버그 수정, 새 기능 구현을 자율적으로 수행한다. Reddit과 Hacker News 사용자들은 "파일 간 의존성을 파악하면서 코드를 수정하는 능력이 다른 모델과 차원이 다르다"고 평가한다. 다만 매우 큰 프로젝트에서는 간혹 불필요한 변경을 추가하는 경우가 있다.
에이전트 워크플로우 - GAIA 74.55%로 웹 검색, 파일 조작, 계산 등 여러 도구를 조합한 복합 태스크를 수행한다 (출처: 공식 블로그). 금융, 법률, 의료, STEM 전문가들이 도메인별 지식과 추론 능력이 이전 모델 대비 극적으로 향상됐다고 평가했다.
글쓰기와 편집 - Every.to의 테스트에서 상위 2개 결과물이 모두 Sonnet 4.5로 생성되었을 만큼, 맥락 파악과 핵심 포인트 도출 능력이 뛰어나다 (출처: every.to). 기술 문서, 블로그 글, 비즈니스 문서 작성에서 실사용자 만족도가 높다.
수학과 과학 추론 - MATH Lvl 5 97.7%, AIME 2025 100%(Python 도구 사용 시)로 올림피아드급 수학 문제를 거의 완벽하게 풀이한다 (출처: 공식 블로그). GPQA Diamond 83.4%로 대학원 수준 물리/화학 추론도 최상위권이다.
컴퓨터 자동화 - OSWorld 61.4%로 데스크톱 환경에서 웹 브라우징, 파일 관리, 애플리케이션 조작 등을 자율적으로 수행한다.
"이건 안 된다"는 평가도 있다. 출력 속도가 약 46.2 tokens/s로 동급 모델 대비 느린 편이고(중간값 66.7 t/s), 확장 사고 모드에서는 토큰 소비가 매우 많아 비용이 급격히 올라갈 수 있다 (출처: artificialanalysis.ai). 또한 문학적 표현력이나 창의적 글쓰기에서는 "추론에 비해 아쉽다"는 한국어 사용자 평가가 있다.

성능
벤치마크 점수
| 벤치마크 | 점수 | 카테고리 | 출처 |
|---|---|---|---|
| GPQA Diamond | 83.4% | LLM | 공식 블로그 |
| MMLU-PRO | 86.0% | LLM | 공식 블로그 |
| MATH Lvl 5 | 97.7% | LLM | 공식 블로그 |
| IFEval | 88.0% | LLM | 공식 블로그 |
| HumanEval | 97.6% | LLM | pricepertoken.com |
| SWE-bench Verified | 77.2% | Agentic | 공식 블로그 |
| OSWorld | 61.4% | Agentic | 공식 블로그 |
| GAIA | 74.55% | Agentic | 공식 블로그 |
| Tau-bench (Retail) | 86.2% | Agentic | leanware.co |
| TerminalBench | 50.0% | 용도별 | artificialanalysis.ai |
| MMMU | 77.8% | 용도별 | localaimaster.com |
| AIME 2025 | 87.0% | 용도별 | 공식 블로그 |
| MMMLU (다국어) | 89.1% | 용도별 | 공식 문서 |
| Arena Elo | 1450 | 종합 | 공식 블로그 |
경쟁 모델 비교
벤치마크 수치만 보면 Sonnet 4.5가 코딩과 에이전트 영역에서 확실히 앞서지만, 실사용 체감은 좀 다르다. GPT-5는 짧고 깔끔한 코드 생성에서 더 낫다는 평가가 있고, Gemini 2.5 Pro는 멀티모달 처리와 문서 분석에서 강점을 보인다. "Sonnet 4.5는 코딩의 왕이지만, 모든 면에서 최고는 아니다"라는 것이 커뮤니티의 대체적인 평가다 (출처: gaodalie.substack.com).
MMMU(비전 추론) 77.8%는 GPT-5(84.2%)와 Gemini 2.5 Pro(82.0%)에 뒤처진다. 멀티모달 벤치마크에서는 코딩만큼의 압도적 우위가 없다.
속도 면에서도 약점이 있다. artificialanalysis.ai에 따르면 출력 속도 46.2 t/s는 비슷한 가격대 추론 모델의 중간값(66.7 t/s)보다 상당히 느리다. 또한 추론 모드에서 매우 장황해져서 Intelligence Index 평가 시 6,400만 토큰을 생성했는데, 평균(1,300만)의 약 5배다.
후속 모델인 Sonnet 4.6이 2026년 3월에 출시되면서 SWE-bench 79.6%로 소폭 개선되었으나, Sonnet 4.5는 여전히 안정적인 선택지로 평가받고 있다.
사용 방법
일반 사용자 - claude.ai 웹사이트(https://claude.ai)에서 무료 또는 Pro($20/월) 계정으로 바로 사용 가능하다. iOS, Android 앱도 제공된다. 무료 티어에서도 Sonnet 4.5를 사용할 수 있지만 일일 메시지 제한이 있다.
개발자(API) - Claude Developer Platform(https://platform.claude.com)에서 API 키를 발급받아 사용한다. 모델 ID는 claude-sonnet-4-5-20250929이다. Python SDK(anthropic 패키지), TypeScript SDK 등을 통해 연동할 수 있다.
클라우드 플랫폼 - Amazon Bedrock, Google Cloud Vertex AI, Microsoft Azure에서 각각의 플랫폼 인증으로 바로 사용 가능하다.
가격
구독 플랜:
- 무료: claude.ai에서 제한적 사용
- Pro: $20/월 (더 많은 메시지, 우선 접근)
- Team: $30/사용자/월
- Enterprise: 별도 협의
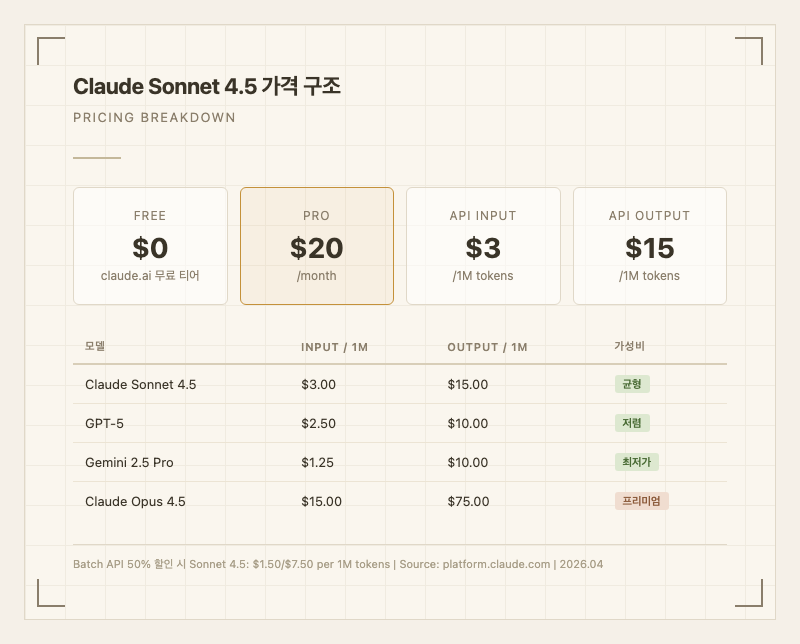
API 가격:
- 입력: $3.00 / 1M 토큰
- 출력: $15.00 / 1M 토큰
- 프롬프트 캐싱: 캐시 히트 시 입력 가격의 10%
- Batch API: 50% 할인 (7.50)
Gemini 2.5 Pro(10)나 GPT-5(10) 대비 출력 토큰 가격이 높은 편이다. 다만 "코딩 에이전트로 쓸 때는 한 번에 제대로 된 결과를 내서 결과적으로 토큰을 덜 쓴다"는 실사용자 평가도 있다. Opus 4.5(75) 대비 5배 저렴하면서 거의 비슷한 성능을 낸다는 점이 가성비 측면에서 가장 큰 강점이다.
200K 토큰을 초과하는 확장 컨텍스트(1M) 사용 시에는 프리미엄 가격이 적용되어 입출력 모두 비용이 크게 올라간다. 한국어 토큰 효율 데이터는 미공개이나, 다국어 벤치마크(MMMLU)에서 영어 대비 80% 이상의 성능을 유지하는 것으로 알려져 있다 (출처: platform.claude.com 다국어 문서).
기술 사양
| 항목 | 상세 |
|---|---|
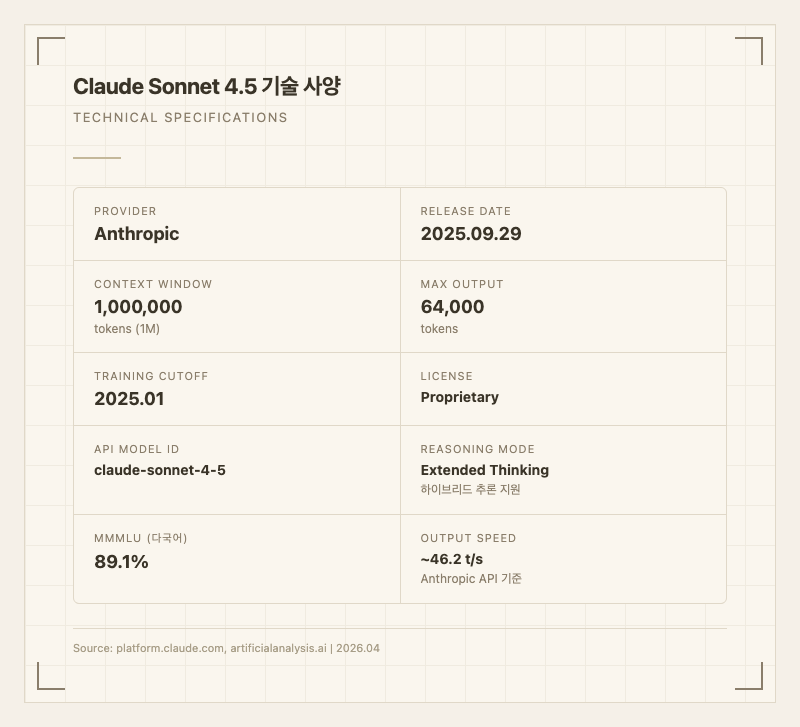
| Provider | Anthropic |
| 모델 ID | claude-sonnet-4-5-20250929 |
| 출시일 | 2025년 9월 29일 |
| 컨텍스트 윈도우 | 1,000,000 토큰 (1M) |
| 최대 출력 | 64,000 토큰 |
| 학습 데이터 기준일 | 2025년 1월 31일 |
| 라이선스 | Proprietary (독점) |
| 추론 모드 | Extended Thinking (하이브리드) |
| 출력 속도 | 약 46.2 tokens/s (Anthropic API 기준, 출처: artificialanalysis.ai) |
| 다국어 성능 | MMMLU 89.1%, 영어 대비 80%+ 유지 |
| 파라미터 수 | 미공개 |
파라미터 수는 Anthropic이 공개하지 않았다. 아키텍처는 Transformer 기반이며, Constitutional AI(RLHF + AI 피드백) 방식으로 학습되었다.
참고 자료



.png)

스펙
컨텍스트 윈도우
1.0M 토큰
라이선스
Proprietary
출시일
2025년 9월 30일
학습 마감일
2025년 1월 31일
가성비 지수
0.5
API 가격 (혼합)
입력 $3.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$3.00 / 1M 토큰
출력 (Completion)
$15.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
수학/추론최강
90.6
수학, 과학, 논리적 추론
지시따르기
88.0
복잡한 지시사항 이해 및 수행
일반지식
86.0
다양한 분야 지식 및 이해
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 | 단위 |
|---|---|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude Sonnet 4.5 | 89.5 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |