Claude Sonnet 4.6
AnthropicLLM자연어 처리컴퓨터 비전오디오 처리1.0M 토큰
2026년 2월 18일Proprietary
한줄 소개
Claude Sonnet 4.6은 Anthropic이 2026년 2월 17일에 출시한 최신 Sonnet급 AI 모델이다. Claude Code(AI 코딩 에이전트)의 기본 엔진이자, claude.ai 무료 및 Pro 사용자 모두의 기본 모델이며, GitHub Copilot의 AI 코딩 에이전트 엔진으로도 채택되었다. "Opus급 성능을 Sonnet 가격으로"라는 콘셉트 그대로, 이전까지 Opus 모델에서만 가능했던 수준의 코딩, 에이전트, 장문 맥락 처리를 Sonnet 가격대에서 제공하는 것이 핵심이다.
주요 특징
Sonnet 4.6의 가장 두드러진 변화는 다섯 가지로 요약된다.
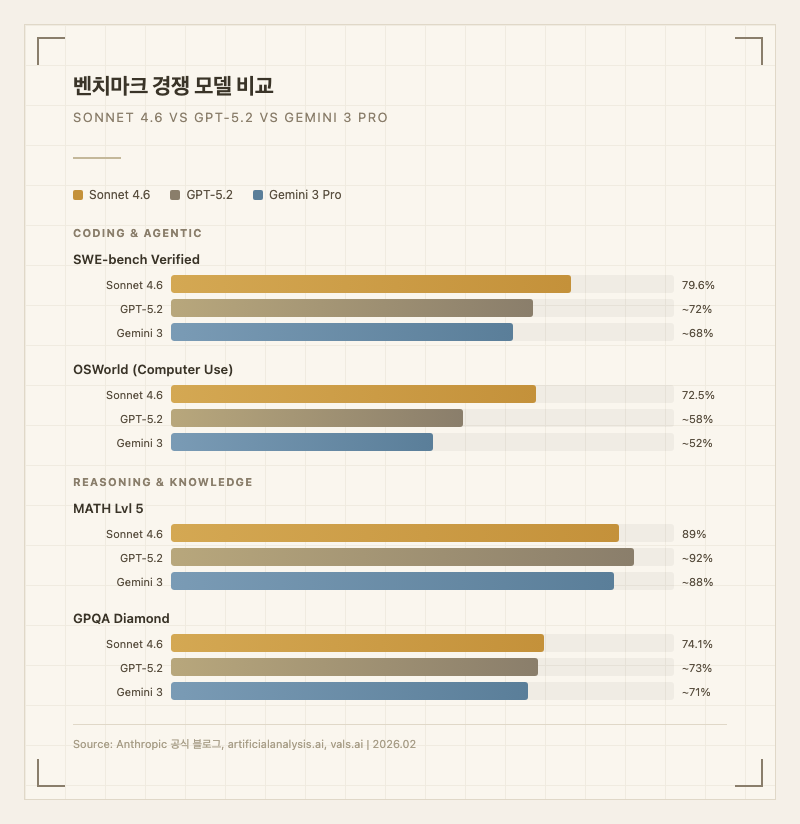
첫째, 코딩 성능의 대폭 향상이다. SWE-bench Verified 79.6%는 실제 GitHub 저장소의 복잡한 버그를 자동으로 수정하는 능력을 측정한 것으로, 5개 중 4개를 스스로 고칠 수 있는 수준이다 (출처: Anthropic 공식 블로그). 개발자 커뮤니티에서는 "Sonnet 4.5에서 끊기던 멀티스텝 리팩토링이 4.6에서는 끝까지 따라온다"는 평가가 지배적이다. Reddit과 GitHub Copilot 서브레딧에서는 "vibe coding과 반복적 기능 개발에서는 Sonnet 4.6이 압도적"이라는 의견이 주류를 이룬다.
둘째, 컴퓨터 사용(Computer Use) 능력이다. OSWorld 72.5%는 브라우저 탐색, 파일 관리, 터미널 작업 등을 사람 개입 없이 수행할 수 있는 능력을 뜻한다 (출처: Anthropic 공식 블로그). Sonnet 4.5 대비 컴퓨터 사용 능력이 대폭 개선되었다.
셋째, 1M 토큰 컨텍스트 윈도우다. 약 75만 단어, 코드베이스 5-10개 분량을 한 번에 처리할 수 있어 이전에는 Opus에서만 가능했던 대규모 코드베이스 분석이 Sonnet급에서도 가능해졌다. 200K 이상 요청은 별도 베타 헤더 없이 자동으로 작동한다.
넷째, Extended Thinking 지원이다. 복잡한 추론이 필요한 작업에서 모델이 스스로 사고 과정을 확장해 더 정확한 답변을 생성한다. MATH Lvl 5에서 전작 62%에서 89%로 27%p 점프한 것이 이를 반영한다 (출처: Anthropic 공식 블로그).
다섯째, 가격 대비 성능이다. Opus 4.6의 97-99% 성능을 약 1/5 비용에 제공한다. 얼리 테스터의 70%가 Sonnet 4.5보다 Sonnet 4.6을 선호했고, 59%는 이전 최상위 모델인 Opus 4.5보다도 Sonnet 4.6을 선호했다 (출처: Anthropic 공식 블로그).

할 수 있는 것
실사용자들이 실제로 해본 작업과 결과를 중심으로 정리하면 다음과 같다.
코딩/개발: Claude Code에서 기본 엔진으로 작동하며, 기존 복잡한 코드베이스를 읽고 리팩토링하는 데 GPT-5.2보다 낫다는 평가가 많다. "게으르지 않다(less lazy)"는 표현이 반복적으로 등장하는데, 멀티스텝 작업에서 중간에 포기하거나 완료를 속이지 않고 끝까지 수행한다는 뜻이다. 다만 정말 새로운 아키텍처를 처음부터 설계하는 수준의 작업은 Opus 4.6이 여전히 우위라는 의견도 있다.
에이전트/자동화: 웹 QA, 워크플로우 자동화, 파일 관리 등 컴퓨터를 직접 조작하는 에이전트 작업에서 강점을 보인다. GDPval-AA 1633 Elo로 오피스 생산성 작업에서 전 모델 중 1위를 기록했다 (출처: artificialanalysis.ai). 브라우저 기반 테스팅, 폼 작성, 데이터 입력 같은 반복 업무를 자동화하는 사례가 커뮤니티에서 자주 보고된다.
문서 작성: 이전 Sonnet 대비 글쓰기 품질이 개선되었다. GPT-5.2의 경우 OpenAI가 코딩과 수학에 집중하느라 글쓰기 품질이 퇴보했다는 평가가 있는 반면(Sam Altman이 직접 인정), Sonnet 4.6은 자연스러운 산문체를 유지한다. 한국어에서도 문어체 표현의 자연스러움이 양호하다는 한국 사용자 후기가 있다.
한계: 비디오와 오디오를 네이티브로 처리하지 못한다. 이 영역에서는 Gemini 3 Pro가 유일한 선택지다. 또한 max effort 모드에서 토큰 사용량이 상당히 많아(벤치마크 평가 시 200M 출력 토큰), 비용 관리에 주의가 필요하다.
성능
벤치마크 요약
| 벤치마크 | 점수 | 카테고리 | 출처 |
|---|---|---|---|
| SWE-bench Verified | 79.6% | Agentic | Anthropic 공식 |
| OSWorld | 72.5% | Agentic | Anthropic 공식 |
| GPQA Diamond | 74.1% | LLM | Anthropic 공식 |
| MMLU-PRO | 79.2% | LLM | Anthropic 공식 |
| MATH Lvl 5 | 89% | LLM | Anthropic 공식 |
| IFEval | 89.5% | LLM | Anthropic 공식 |
| HumanEval | 92.1% | LLM | Anthropic 공식 |
| MMMU | 83.6% | Capability | Anthropic 공식 |
| HLE | 51% | Reasoning | artificialanalysis.ai |
| AIME 2025 | 94% | Math | nxcode.io |
| TerminalBench | 53% | Agentic | artificialanalysis.ai |
| Arena Elo | 1438 | Capability | lmsys.org |
경쟁 모델 비교
Artificial Analysis Intelligence Index에서 Sonnet 4.6은 51점으로, GPT-5.2(51)와 동점이고 Opus 4.6(53)에 2점 차로 바짝 붙었다 (출처: artificialanalysis.ai). Anthropic이 Intelligence Index 상위 2개를 동시에 점유한 것은 이번이 처음이다.
코딩과 에이전트에서는 Sonnet 4.6이 선두다. 수학에서는 GPT-5.2가 근소하게 앞선다(MATH ~92% vs 89%). 멀티모달(비디오/오디오)에서는 Gemini 3 Pro가 유일한 선택지다. 가격은 Sonnet 4.6이 GPT-5.2 대비 25-46% 저렴하다.
실사용에서의 체감 차이로는, 코딩 품질 자체는 Sonnet 4.6과 GPT-5.2가 비슷하지만 Sonnet 4.6이 "끝까지 따라오는" 경향이 있어 멀티스텝 작업에서 더 신뢰할 수 있다는 평가가 반복된다. 글쓰기에서는 Sonnet 4.6이 GPT-5.2보다 자연스럽다는 의견이 우세하다. 단점으로는 max effort 모드에서 토큰 사용량이 Sonnet 4.5 대비 약 3배(74M vs 25M)로, extended thinking을 과도하게 사용하면 비용이 급증할 수 있다 (출처: artificialanalysis.ai).
사용 방법
일반 사용자(웹/앱): claude.ai에서 무료로 사용 가능하다. 무료 티어에서도 Sonnet 4.6이 기본 모델이다. Claude Pro($20/월) 구독 시 사용량 제한이 완화되고, Opus 4.6 등 상위 모델도 사용할 수 있다. iOS, Android 앱에서도 동일하게 접근 가능하다.
개발자(API): Anthropic Messages API를 통해 접근한다. 모델 ID는 claude-sonnet-4-6-20260217이다. Extended Thinking, Tool Use(Function Calling), Computer Use, Vision 등 모든 Claude API 기능을 지원한다. Amazon Bedrock, Google Vertex AI, OpenRouter 등 주요 클라우드 플랫폼에서도 사용 가능하다.
Claude Code: 터미널 기반 AI 코딩 에이전트로, Sonnet 4.6이 기본 엔진이다. npm install -g @anthropic-ai/claude-code 후 바로 사용할 수 있다.
가격
API 가격은 Sonnet 4.5와 동일하게 유지된다: 입력 15 per 1M 토큰. 프롬프트 캐싱을 사용하면 캐시 읽기가 1.50/$7.50으로 50% 절감된다.
웹 구독 플랜은 Free(무료, Sonnet 4.6 기본 포함), Pro(30/사용자/월)으로 구성된다.
경쟁 모델과 비교하면, GPT-5.2(입력 20)보다 25-46% 저렴하면서 코딩/에이전트에서는 동등 이상의 성능을 낸다. Opus 4.6(입력 75) 대비 5분의 1 비용으로 97-99% 성능을 제공하므로, 대부분의 사용 사례에서 Opus 대신 Sonnet 4.6을 쓰는 것이 합리적이다.
커뮤니티에서는 "2026년 2월 기준 가장 가성비 좋은 프론티어 모델"이라는 평가가 지배적이다. 다만 extended thinking을 max effort로 사용하면 토큰 소모가 급격히 늘어나므로(일반 대비 약 3배), 비용 관리를 위해 thinking budget을 적절히 조절할 필요가 있다.
한국어 토큰 효율 데이터는 공식적으로 미공개다. Anthropic 문서에 따르면 한국어를 포함한 주요 동아시아 언어에서 영어 대비 80% 이상의 성능을 유지한다고 한다 (출처: Anthropic Multilingual Support 문서). 한국어 사용자 후기에서는 문어체, 표준어 중심의 이해도가 높다는 평가가 있다.

기술 사양
| 항목 | 사양 |
|---|---|
| 개발사 | Anthropic |
| 출시일 | 2026년 2월 17일 |
| 모델 ID | claude-sonnet-4-6-20260217 |
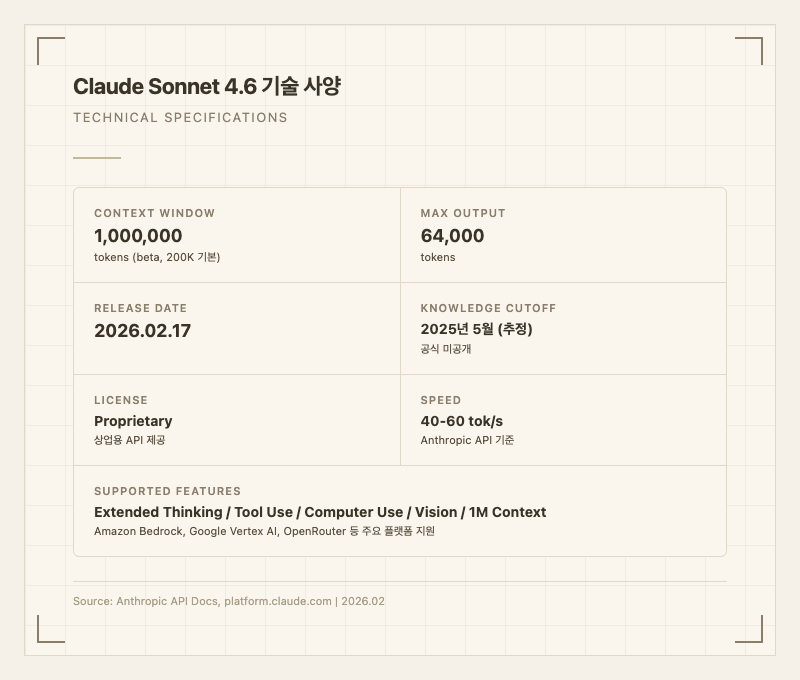
| 컨텍스트 윈도우 | 1,000,000 토큰 (베타, 기본 200K) |
| 최대 출력 | 64,000 토큰 |
| 처리 속도 | 40-60 토큰/초 (Anthropic API 기준) |
| 라이선스 | Proprietary (상업용 API 제공) |
| 지원 기능 | Extended Thinking, Tool Use, Computer Use, Vision, 1M Context |
| 플랫폼 | claude.ai, Anthropic API, Amazon Bedrock, Google Vertex AI, OpenRouter |
| 학습 데이터 기준일 | 공식 미공개 |
파라미터 수는 공식적으로 공개되지 않았다. 아키텍처 역시 Transformer 기반이라는 점 외에 구체적인 내용은 미공개다.
참고 자료




스펙
컨텍스트 윈도우
1.0M 토큰
라이선스
Proprietary
출시일
2026년 2월 18일
학습 마감일
2025년 5월 1일
가성비 지수
0.5
API 가격 (혼합)
입력 $3.00/1M
조회수
0
API 가격 (USD 기준)
입력 (Prompt)
$3.00 / 1M 토큰
출력 (Completion)
$15.00 / 1M 토큰
용도별 성능
태스크 관련 벤치마크 평균 점수
지시따르기최강
89.5
복잡한 지시사항 이해 및 수행
멀티모달
83.6
이미지, 비디오 등 멀티모달 이해
일반지식
79.2
다양한 분야 지식 및 이해
Provider
Anthropic
분류
자연어 처리컴퓨터 비전오디오 처리TransformerLLM
성능 평가
꼭지점 클릭 → 벤치마크 행 이동
| 벤치마크 | 이 모델 |
|---|
유사 모델 비교
| 모델 | LLM 점수GPQA·MMLU·MATH·IFEval·HumanEval |
|---|---|
| Claude Sonnet 4.6 | 82.4 |
| o1-pro | 86.4 |
| o3 | 88.8 |
| Grok 4.1 Fast | 74.4 |
| Command A | 69.1 |